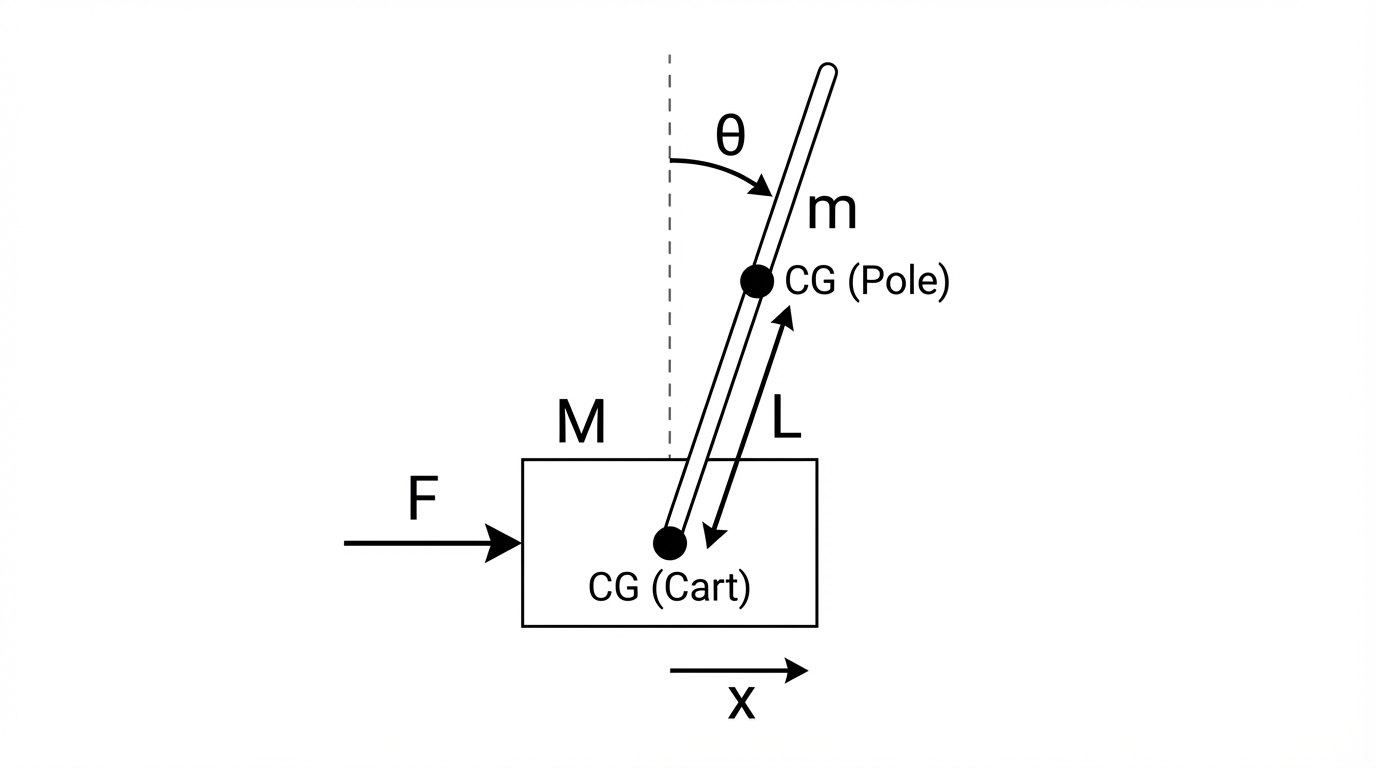
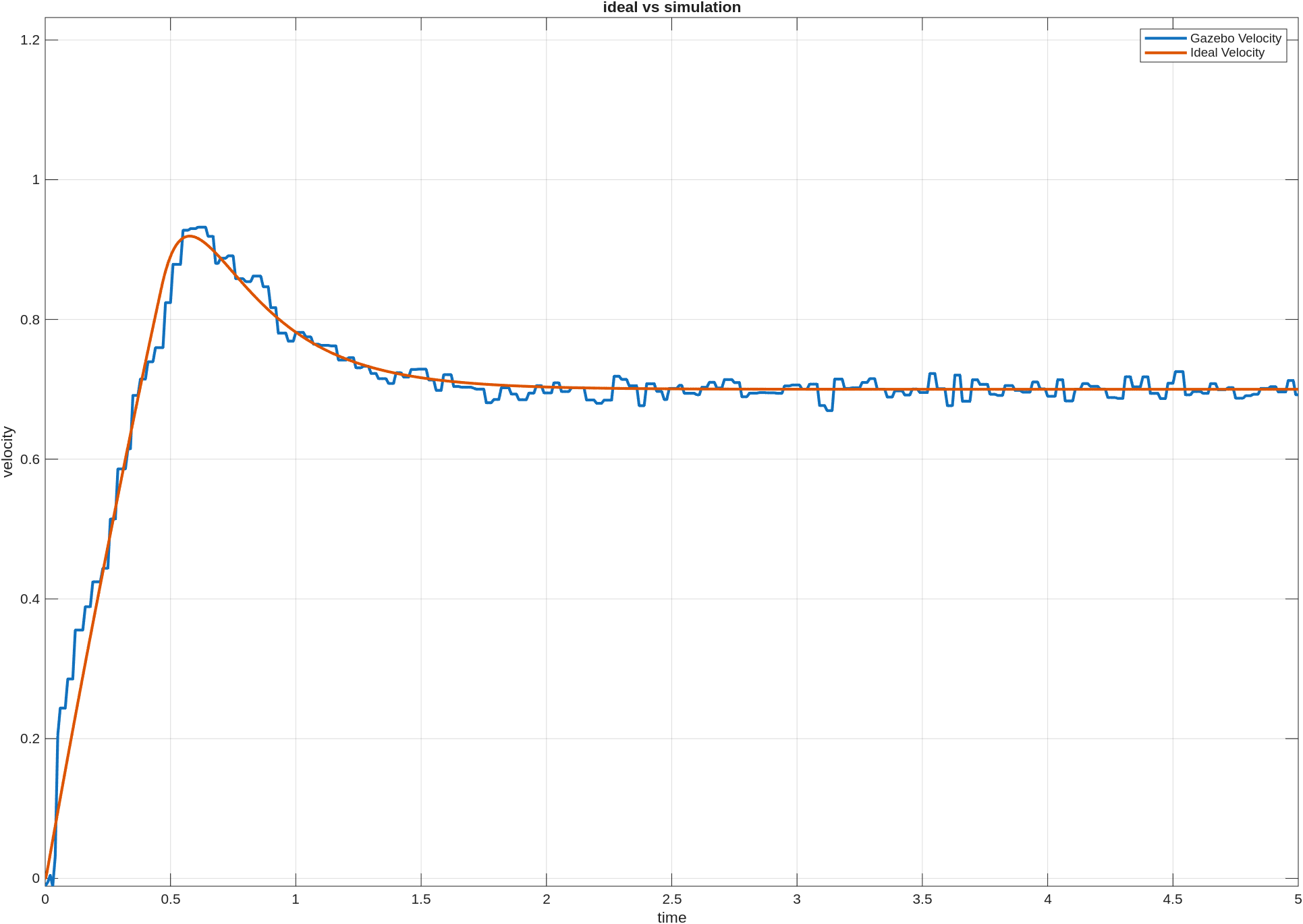
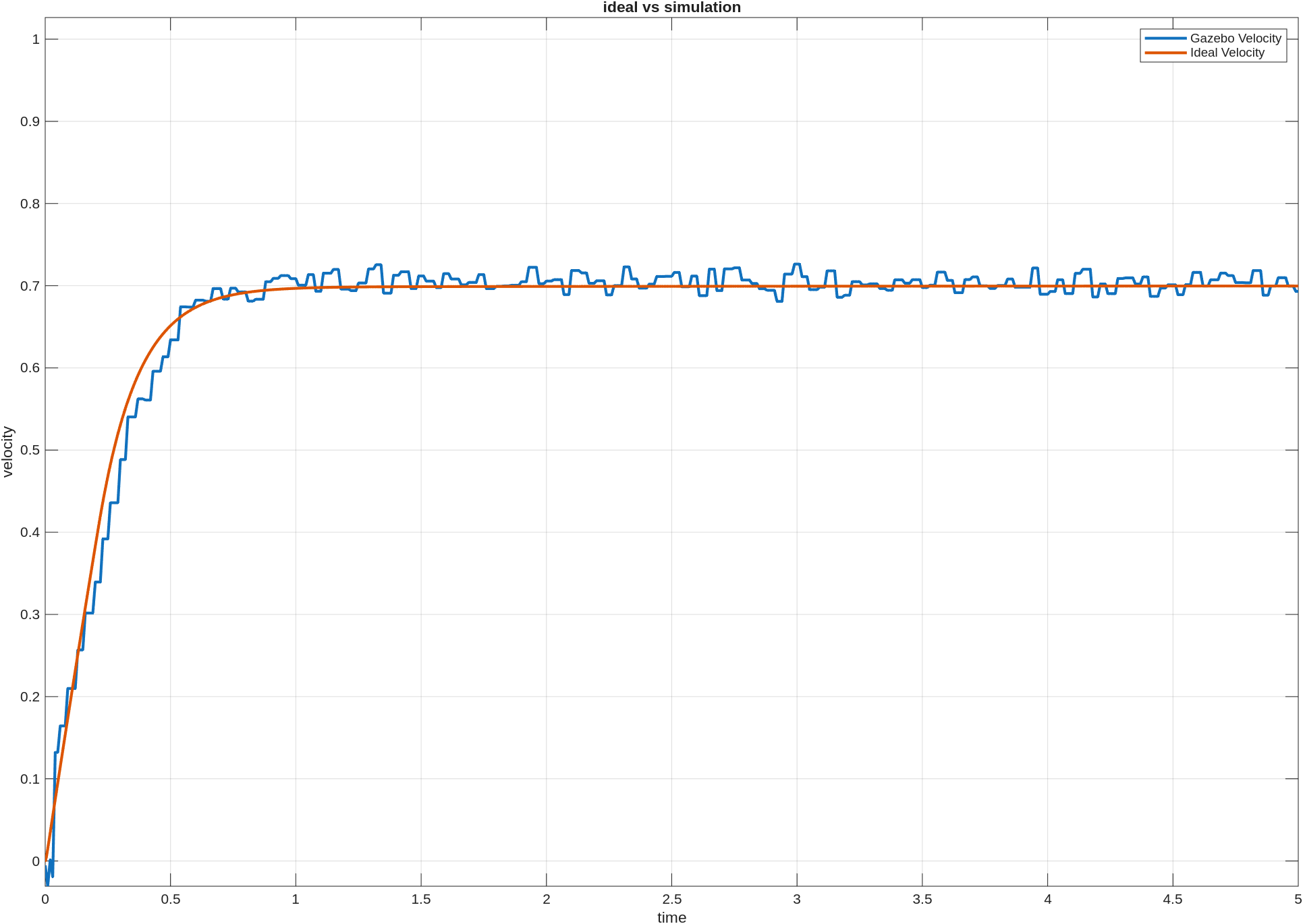
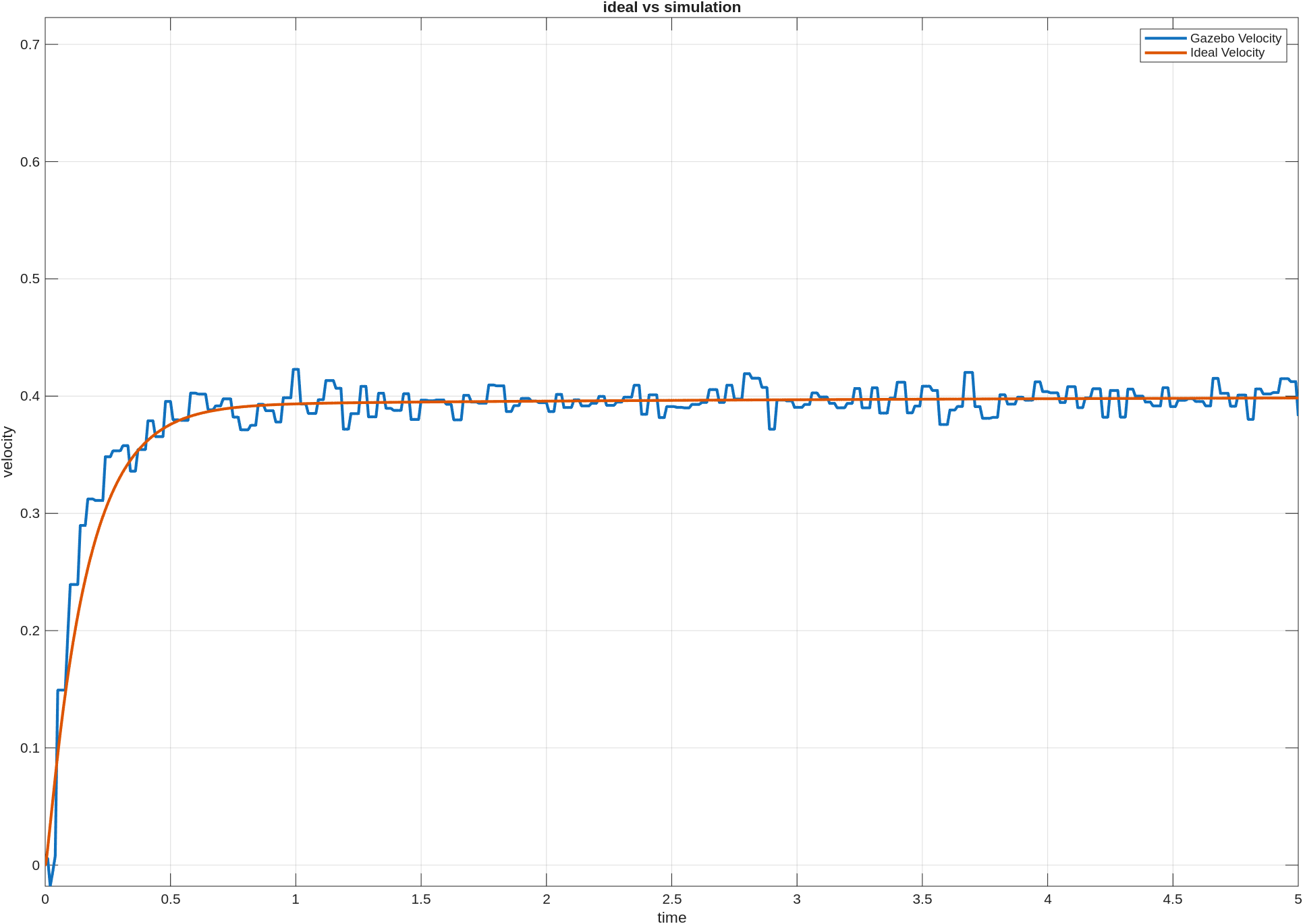
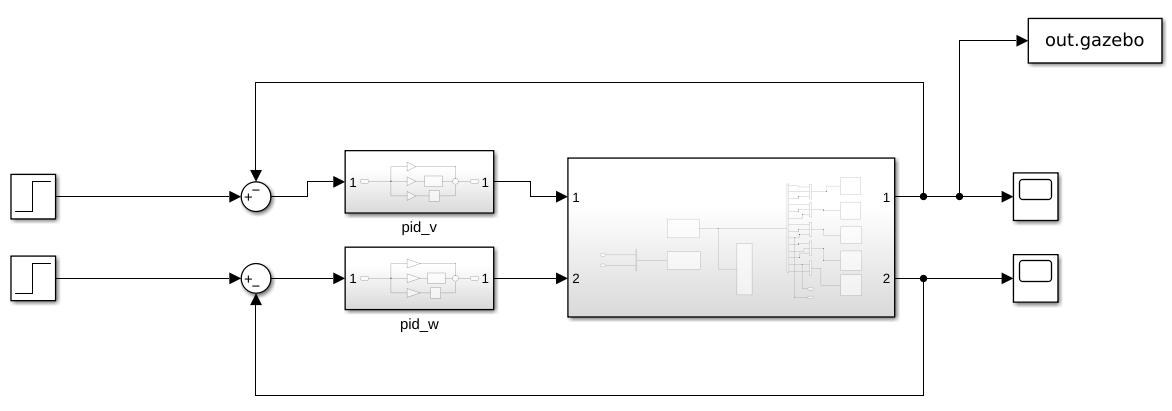
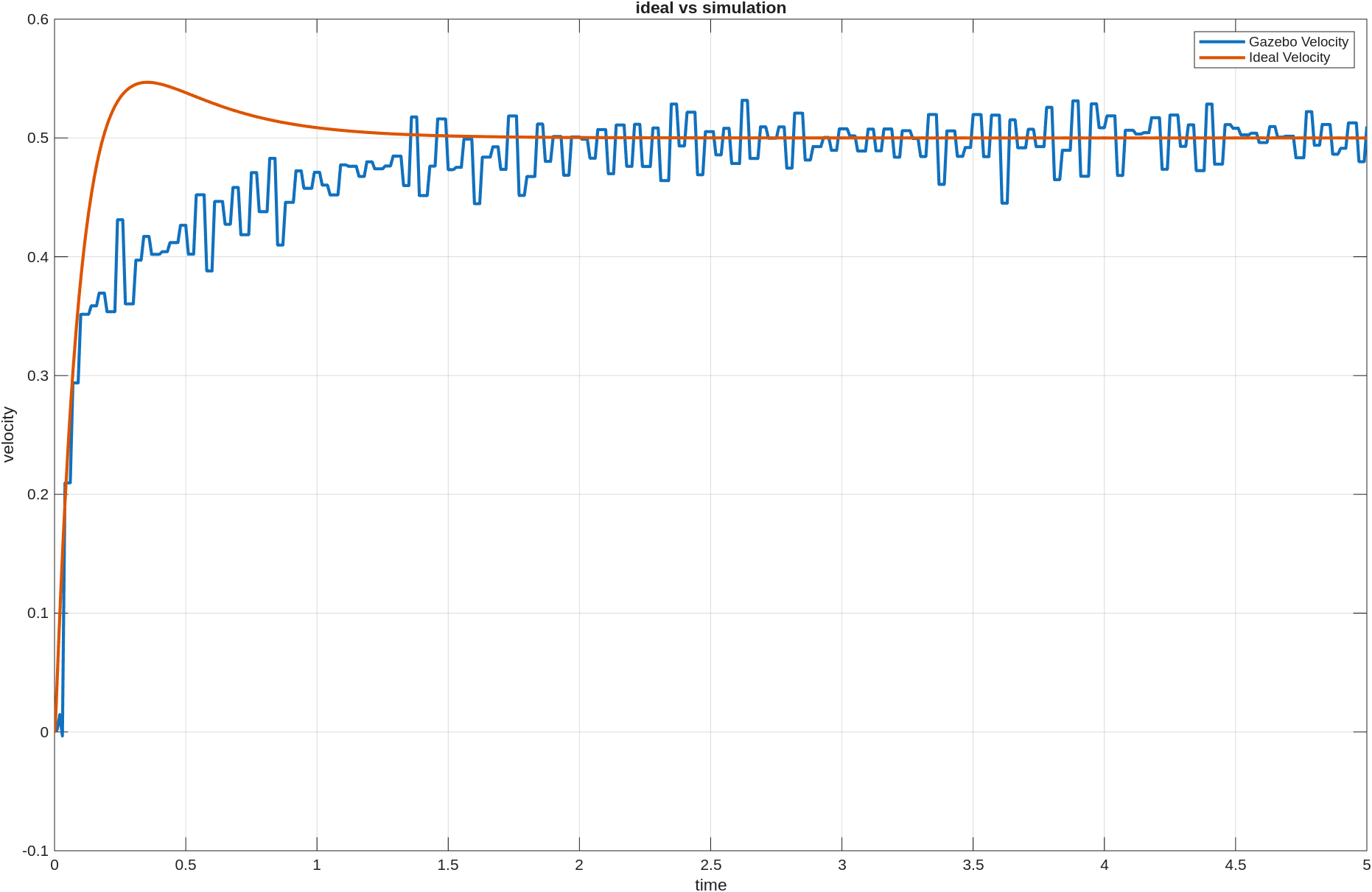
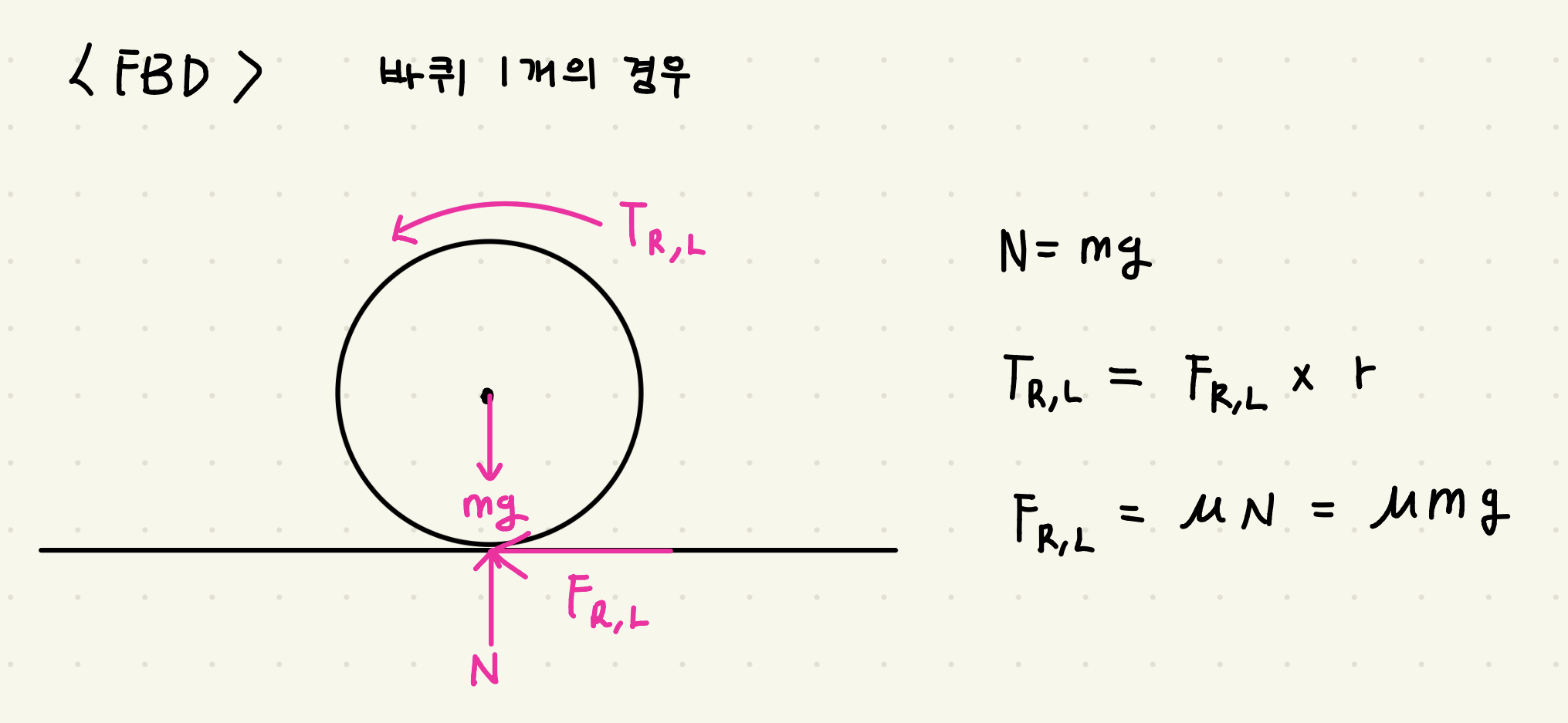
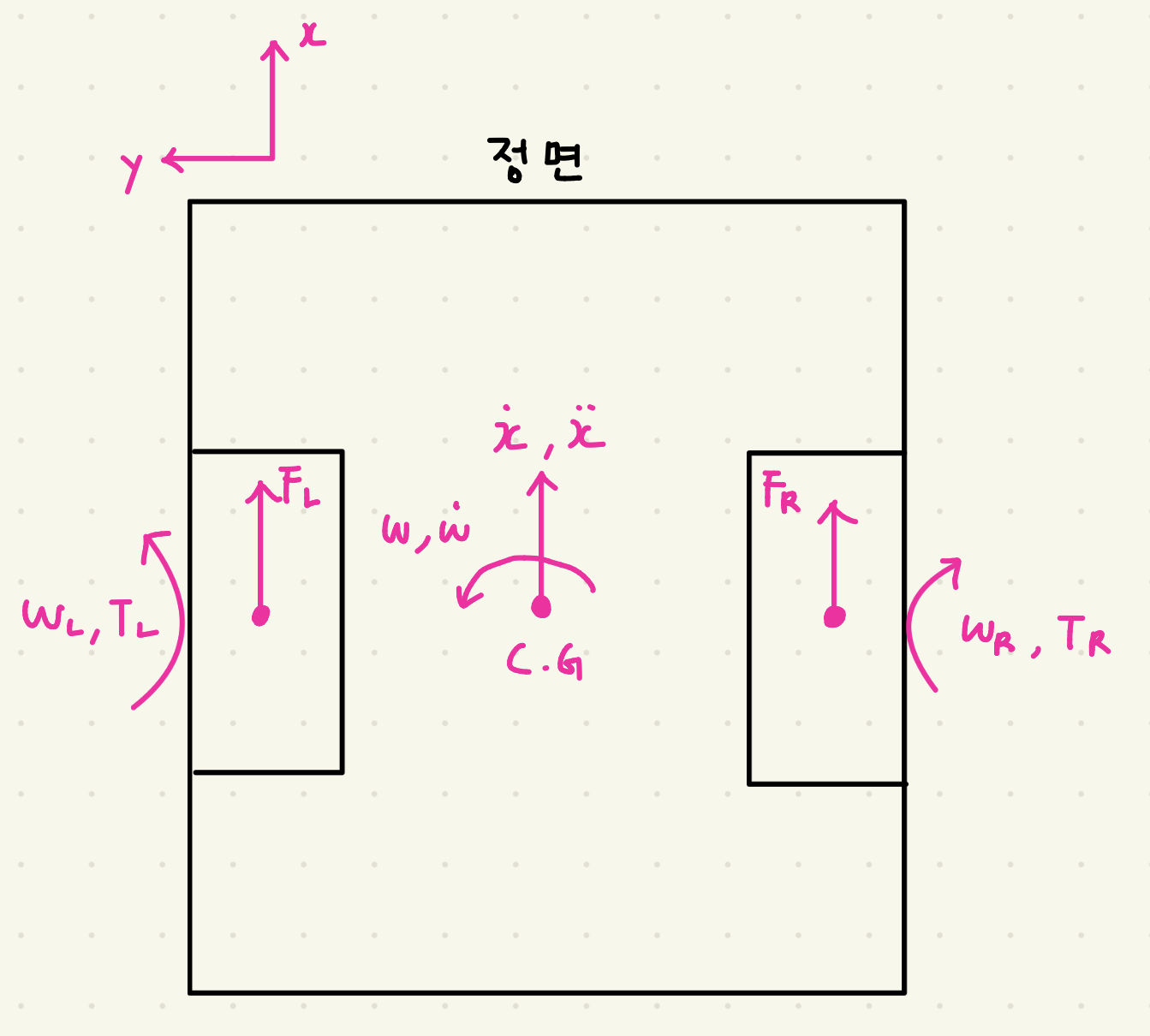
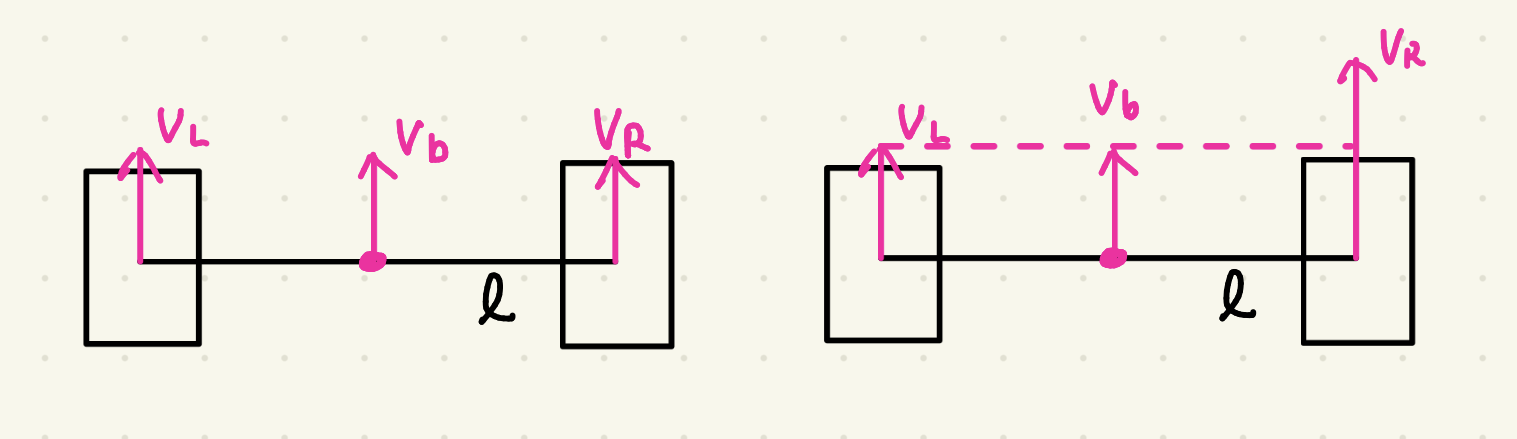
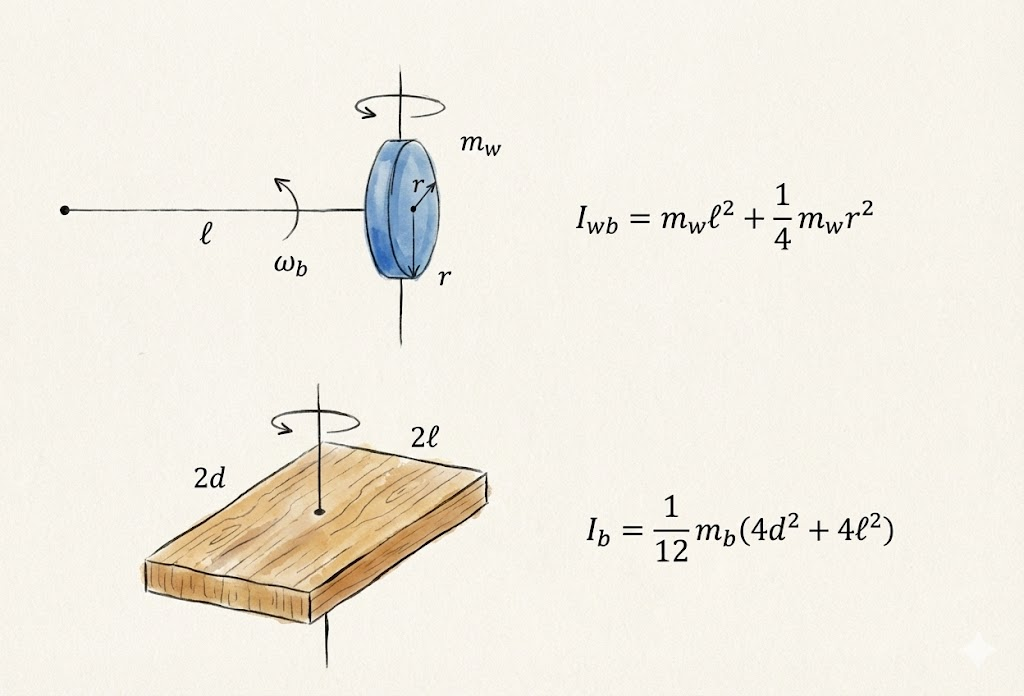
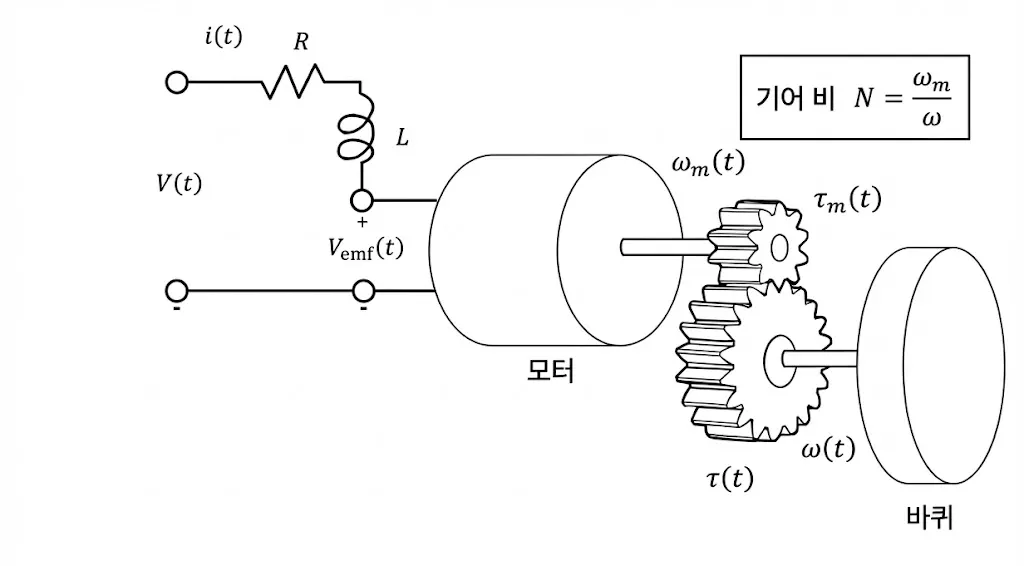
이전 포스팅에서는 custom env를 만들고, baseline을 두고, PPO가 실제로 학습되는지까지는 확인했다. 그 과정만으로도 강화학습을 처음 붙여보는 경험은 충분히 할 수 있었지만, 실험을 더 해보려고 하니 아쉬운 점도 분명히 보였다.
예를 들면 이런 것들이었다.
- PPO를 한 가지 설정으로만 돌려서, 왜 그 설정을 썼는지 비교하기 어려웠다.
- target을 다르게 주면 어떤 차이가 나는지 더 체계적으로 보고 싶었다.
- 결과가 한 번 잘 나온 것인지, 여러 seed에서도 비슷한지 보고 싶었다.
- 학습 때 보던 target과 안 보던 target을 나눠서 평가해 보고 싶었다.
그래서 이번 포스팅은 이전 구조를 지우거나 고치는 대신, 그 위에 조금 더 연구처럼 실험할 수 있는 구조를 새로 만든 버전이라고 생각하고 시작했다.
목표
이번 확장판에서 먼저 해보고 싶은 목표는 아래 네 가지였다.
- 이전 포스팅에서 만들었던 2-link leg RL 문제를 그대로 유지하면서, 실험 구조만 더 엄밀하게 바꿔 보기
- 목표 각도 변화량 방식과 직접 토크 방식을 같은 환경에서 비교할 수 있게 만들기
fixed target,randomized target,held-out target을 나눠서 정책이 어디까지 대응하는지 보기- seed를 여러 개 돌리고 결과를 한 폴더 구조 안에서 정리해서, 한 번 잘 나온 실험과 반복해서 비슷하게 나오는 실험을 구분해 보기
즉 이번 실험는 “PPO가 되느냐”만 보는 기록이 아니라, 어떤 실험 조건을 추가로 확인하고 싶어서 확장했는지를 적어 가는 노트로 쓰려고 한다.
왜 action 방식부터 다시 보려고 했나?
이전 포스팅에서는 action을 목표 각도 변화량 방식 한 가지로만 두고 실험했다. 그 방식 자체는 그때는 합리적이었다. 직접 토크를 내게 하는 것보다 안정적일 것 같았고, 내가 이미 알고 있던 PD 제어와도 자연스럽게 이어졌기 때문이다.
그런데 확장판을 생각하면서 보니, 사실 그때는 “왜 이 action 방식이 더 낫다고 생각했는지”를 결과로 직접 비교해 본 적은 없었다. 그냥 첫 실험용으로 그렇게 정하고 들어간 셈이었다. 그래서 이번에는 같은 2-link 문제를 유지한 상태에서, action만 바꿨을 때 어떤 차이가 나는지 따로 보고 싶어졌다.
이번 확장판에서 비교하려는 action 방식은 두 가지다.
목표 각도 변화량 방식(pd_target_offset) 현재 자세를 기준으로 목표 관절각을 조금 움직이게 한 뒤, 실제 토크는 PD 제어기가 만들게 하는 방식직접 토크 방식(direct_torque) policy가 낸 action을 거의 바로 토크로 해석하는 방식
내가 먼저 확인하고 싶은 것은 아주 단순하다. 정말 목표 각도 변화량 방식이 학습하기 더 쉬운지, 아니면 생각보다 직접 토크 방식도 해볼 만한지 보는 것이다. 즉 이번 확장판에서는 action 설계도 그냥 받아들이는 것이 아니라, 비교해 볼 수 있는 대상으로 두기로 했다.
직접 토크 방식은 action이 어떻게 쓰이나?
이전 포스팅에서는 action이 바로 토크가 되지 않았다. 먼저 목표 관절각을 조금 움직이는 명령으로 바꾸고, 실제 토크는 PD 제어기가 계산했다. 그래서 policy가 내는 값과 실제 물리에 들어가는 값 사이에 한 단계가 더 있었다.
그런데 직접 토크 방식에서는 그 중간 단계가 없다. policy가 낸 action을 거의 바로 토크로 바꿔서 동역학 계산에 넣는다.
예를 들어 policy가
action = [0.6, -0.4]
를 냈고, 최대 토크가
tau_limit = 40.0
이라면 실제 토크는
tau = 40.0 * [0.6, -0.4]
= [24.0, -16.0]
처럼 바로 계산된다.
즉 이 방식에서는
- 첫 번째 관절에는
24.0 - 두 번째 관절에는
-16.0
의 토크가 바로 들어간다고 생각하면 된다.
내가 이해한 바로는, 이 방식은 중간 완충 장치가 없는 느낌에 가깝다. 목표 각도 변화량 방식에서는 action이 먼저 목표 자세 쪽으로 바뀌고 PD 제어기가 토크를 만들어 줬는데, 직접 토크 방식에서는 policy 출력이 거의 바로 물리계로 들어간다. 그래서 학습 초반에 이상한 action이 나오면 더 거칠게 움직일 수도 있을 것 같았다.
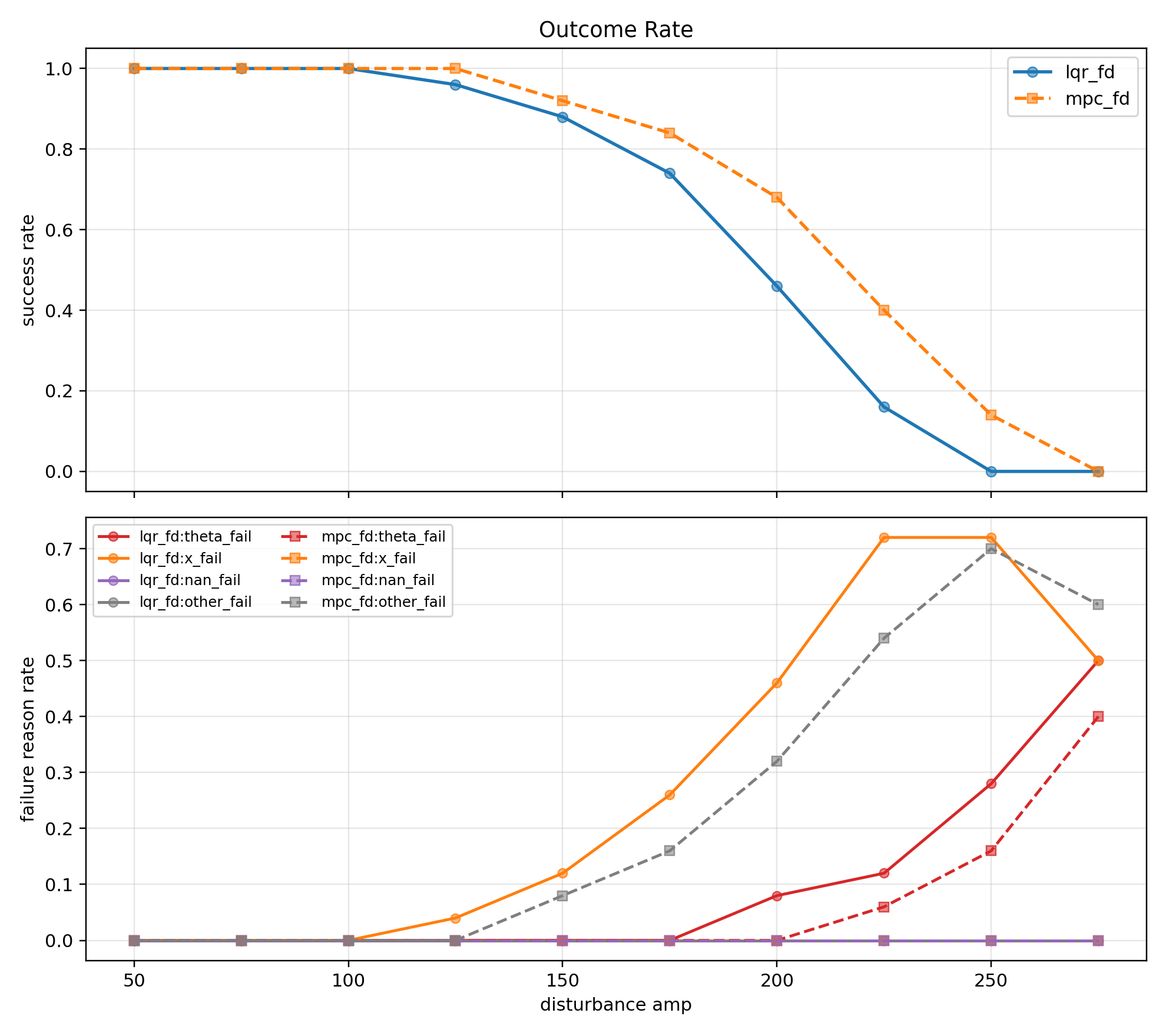
액션 방식 비교 실험 결과
이번에는 target 조건은 둘 다 randomized_train으로 고정하고, action 방식만 바꿔서 비교했다.
- 목표 각도 변화량 방식 (
pd_target__randomized_train) - 직접 토크 방식 (
direct_torque__randomized_train)
각 실험은 seed 7, 11, 21로 돌렸고, 각 seed마다 100000 step 학습했다. 그 뒤 run별 평가를 돌리고, 마지막에 aggregate 결과를 모아서 비교했다.
여기서 내가 처음 헷갈렸던 건 primary와 held-out이라는 말이었다.
primary평가는 학습 때와 같은 방식으로 목표를 다시 랜덤하게 뽑아서 보는 평가다(이전에 사용한 방식).held-out평가는 학습 때 일부러 따로 쓰지 않은 고정 목표 25개에서 따로 보는 평가다.
즉 primary는 “학습하던 방식의 문제에서는 잘 되나?”를 보는 것이고, held-out은 “처음 보는 평가용 목표들에서도 어느 정도 되나?”를 보는 것이다.
aggregate 숫자부터 보면
| 실험 | primary best success rate | held-out success rate | primary best mean final distance |
|---|---|---|---|
| 목표 각도 변화량 방식 | 30.0% |
30.7% |
0.538 |
| 직접 토크 방식 | 0.0% |
0.0% |
0.635 |
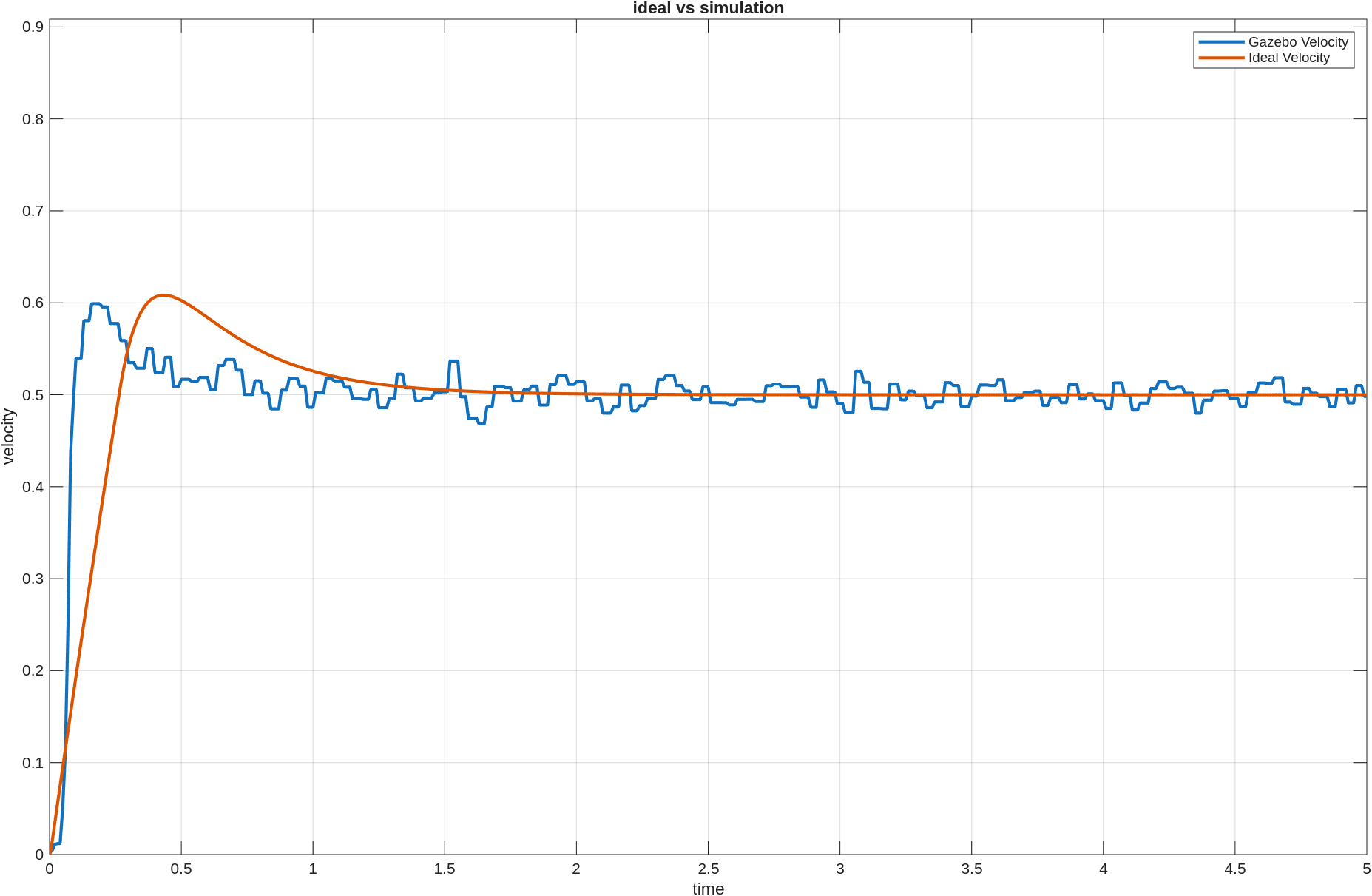
결론은 아주 단순했다. 같은 target 조건에서는 직접 토크 방식보다 목표 각도 변화량 방식이 훨씬 잘 학습됐다.
직접 토크 방식은 seed를 세 개 돌렸는데도 success가 한 번도 나오지 않았다.
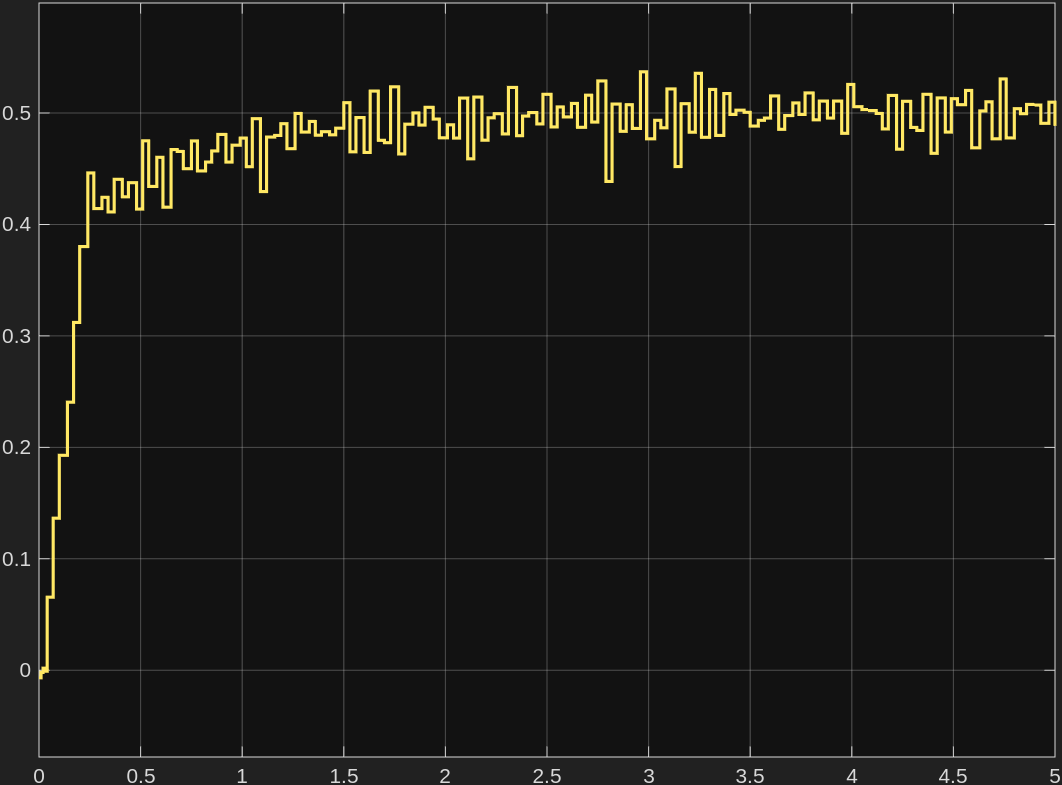
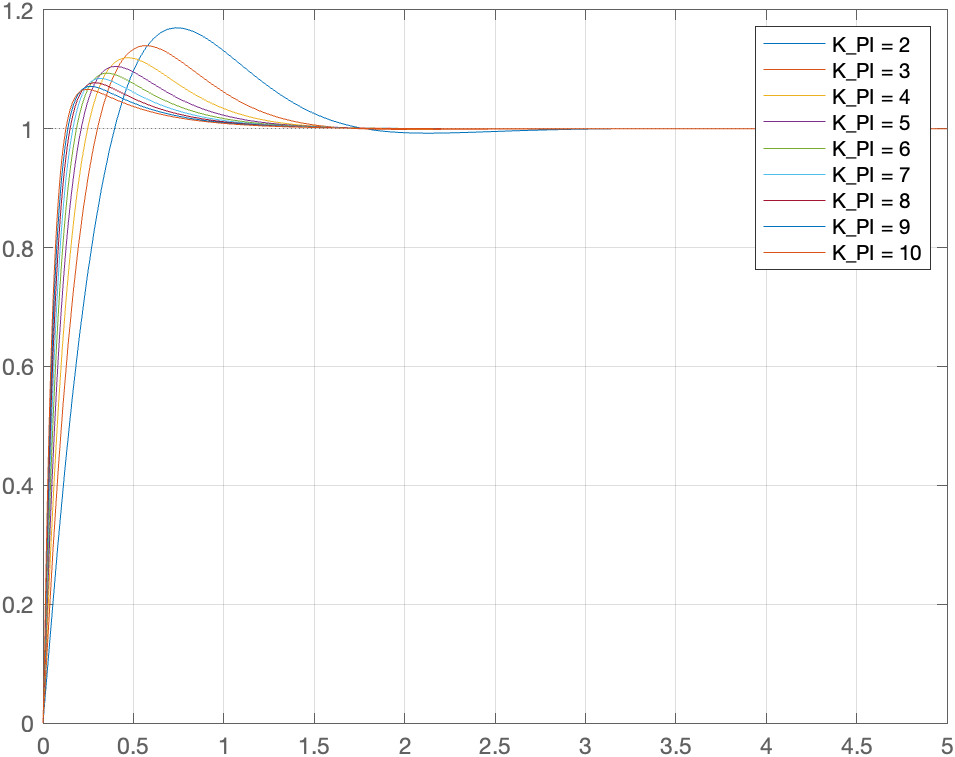
성공률 그래프를 보면
성공률 그래프를 보면 차이가 바로 보였다.
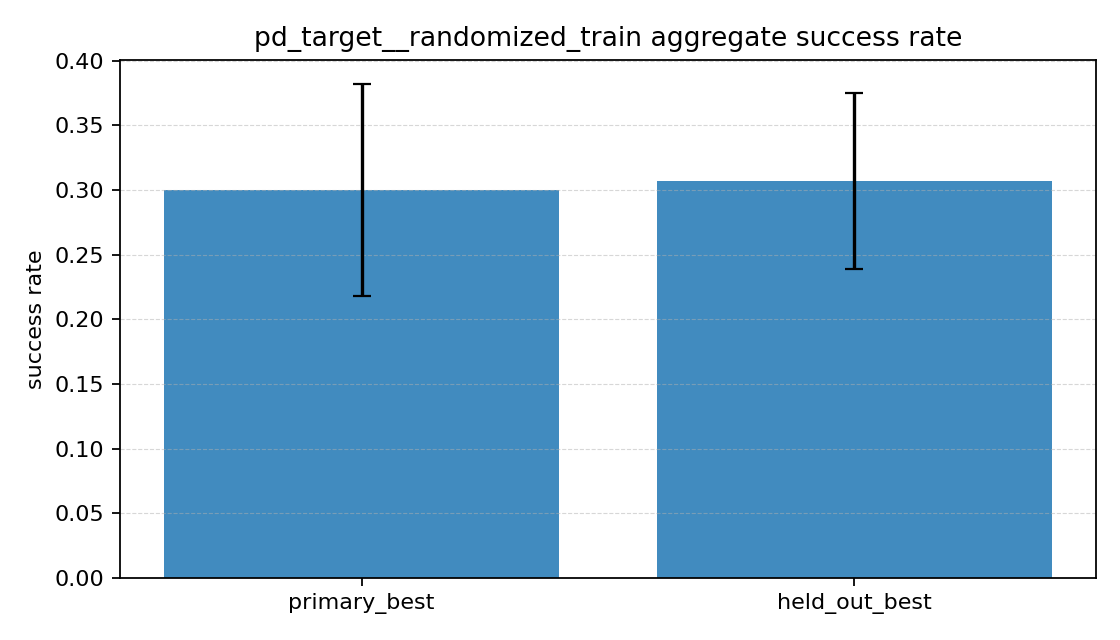
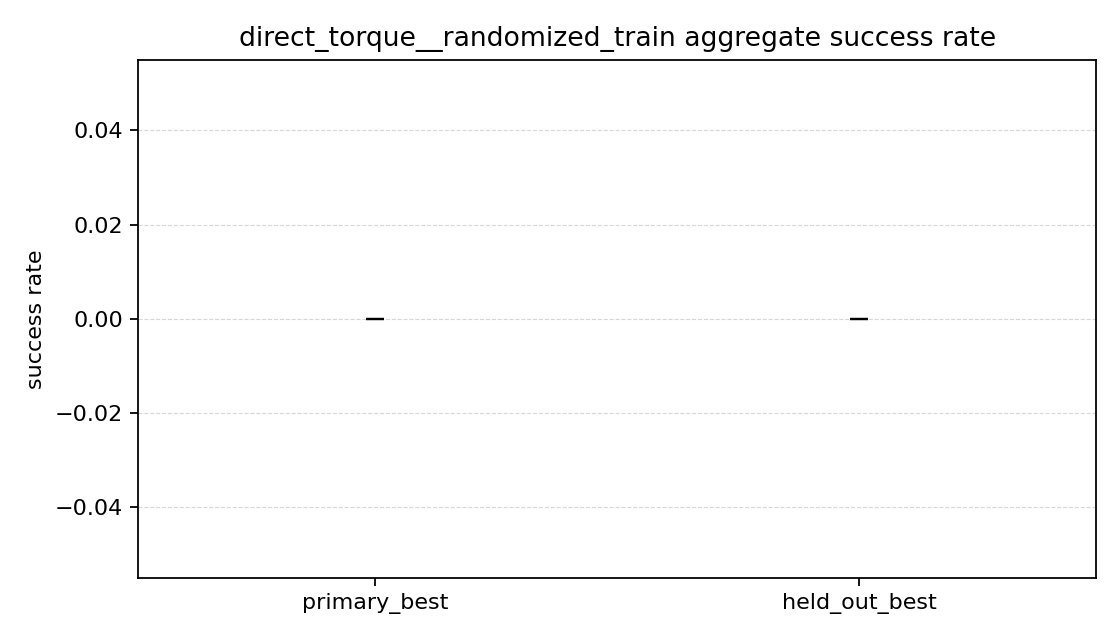
- 목표 각도 변화량 방식은 primary와 held-out 둘 다 성공률이 대략
30%근처였다. - 직접 토크 방식은 primary도
0%, held-out도0%였다.
즉 직접 토크 방식은 학습 때와 같은 방식으로 랜덤 목표를 다시 뽑아도 잘 못 갔고, 학습 때 따로 쓰지 않은 held-out 목표들에서도 마찬가지였다.
최종 거리 그래프를 보면
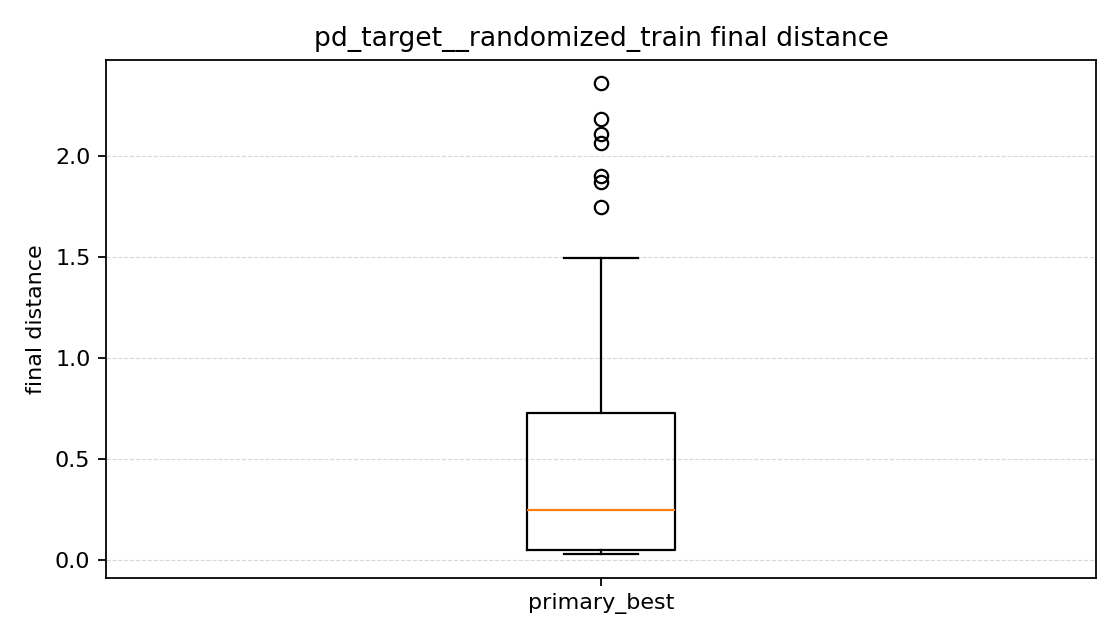
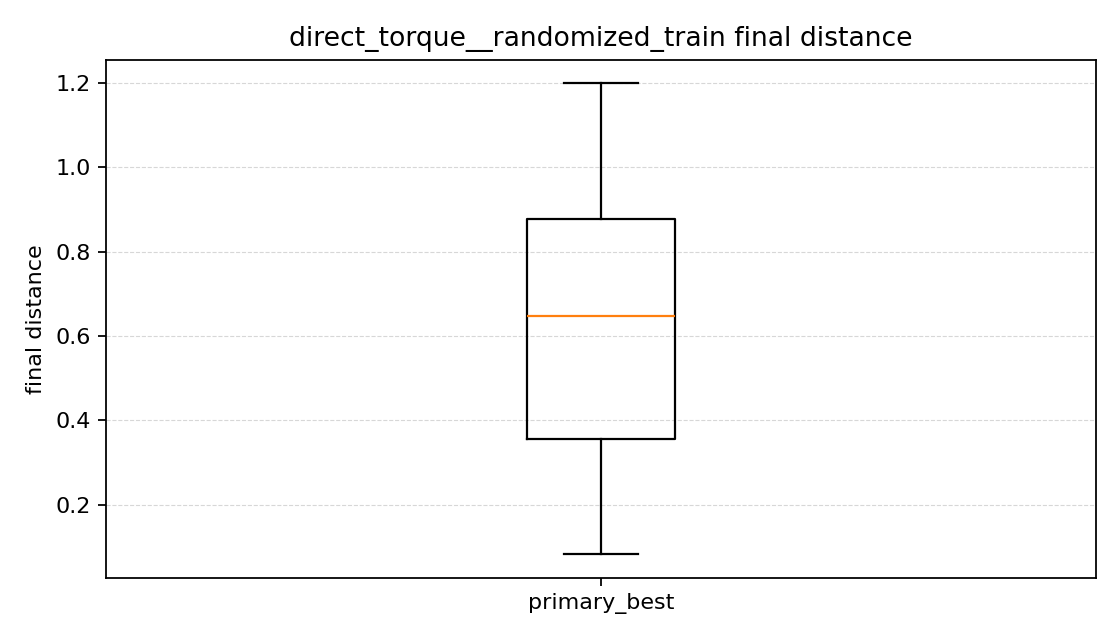
이 그래프는 박스플롯이라서 처음에는 조금 낯설었다. 나는 이걸 이렇게 읽었다.
- 네모 박스: 값들이 많이 모여 있는 구간
- 가운데 주황선: 중앙값
- 위아래 선: 크게 튀지 않은 범위
- 바깥 동그라미: 다른 값들보다 유난히 크게 튀는 값
그래서 여기서는 주황선이 낮을수록 보통 목표에 더 가깝게 끝났다고 볼 수 있다. 또 위쪽 동그라미가 많으면 어떤 episode들은 목표에서 훨씬 멀리 끝났다고 이해했다.
이번 결과에서는 목표 각도 변화량 방식 쪽이 전반적으로 더 낮은 거리 쪽에 분포했고, 중앙값도 직접 토크 방식보다 더 낮았다. 즉 보통의 episode를 놓고 보면 목표 각도 변화량 방식이 더 가까이 가는 편이었다.
다만 목표 각도 변화량 방식 쪽은 분포가 더 넓고, 위쪽으로 튀는 값도 보였다. 잘되는 episode에서는 확실히 더 잘 가지만, 어떤 경우에는 멀리서 끝나는 경우도 남아 있었다는 뜻이다.
반대로 직접 토크 방식은 분포가 조금 더 모여 있기는 했지만, 전체적으로 목표에서 더 먼 쪽에 머물렀다. 즉 아주 크게 망한다기보다, 애초에 목표까지 충분히 가까이 가지 못한 채 끝나는 경우가 많았다고 느꼈다.
제어 effort 그래프를 보면
제어 effort 그래프는 조금 흥미로웠다.
여기서 제어 effort는 각 episode 동안 나온 토크의 크기를 계속 더해서 만든 값이다.
코드에서는
control_effort += ||tau||^2 * dt
처럼 계산한다. 즉 토크를 얼마나 많이, 얼마나 오래 썼는지를 같이 반영한 값이다. 그래서 값이 크면 그 episode에서는 제어 입력을 더 많이 쓴 것으로 볼 수 있다.
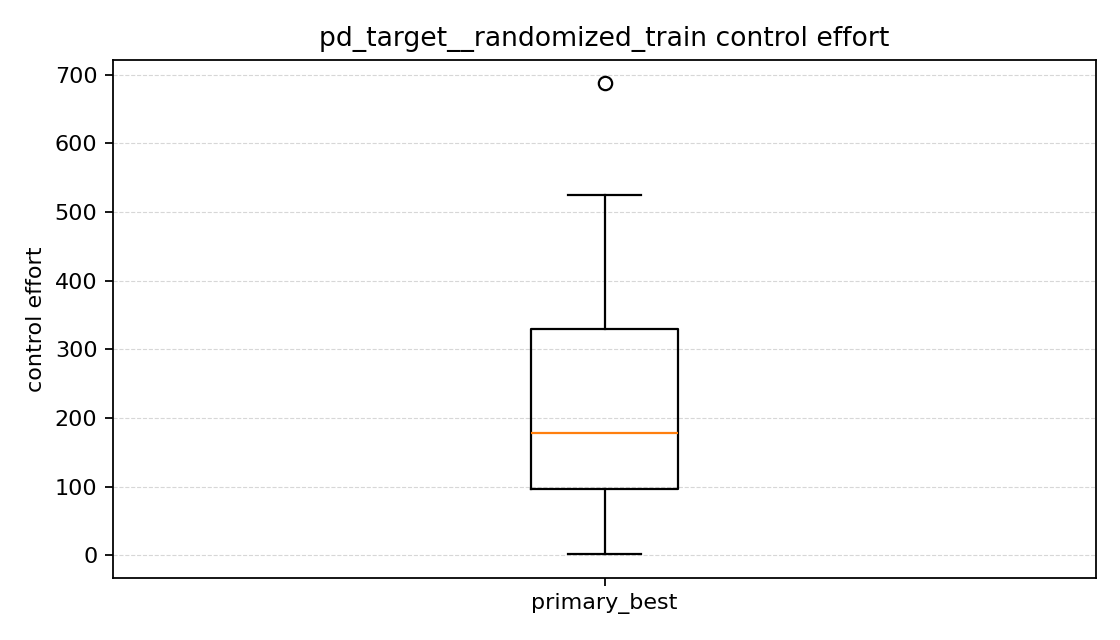
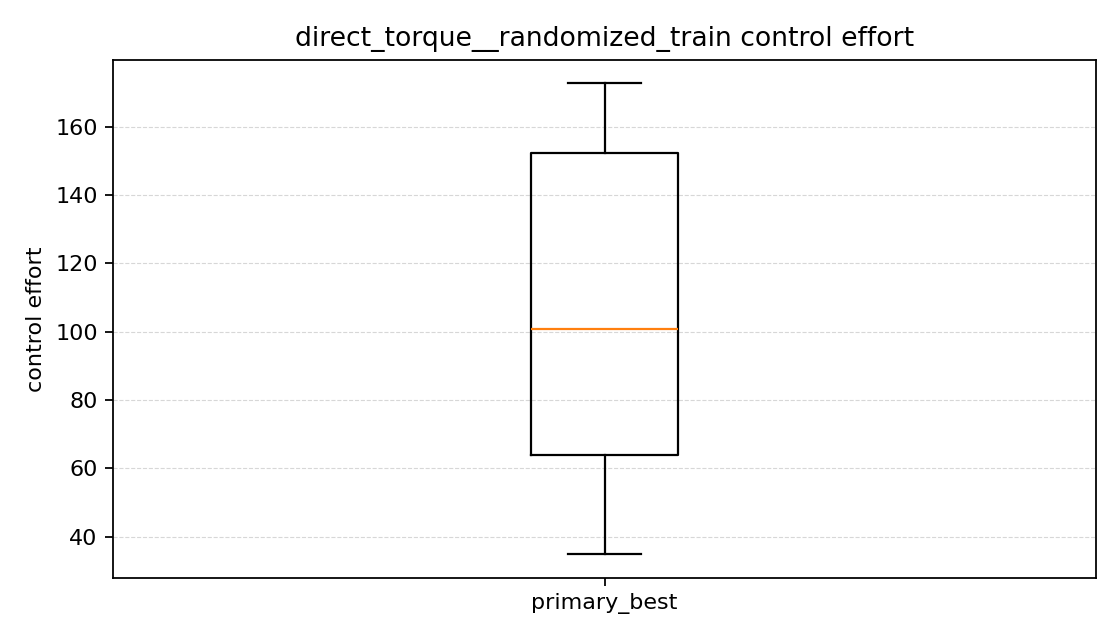
- 목표 각도 변화량 방식이 control effort는 더 컸다.
- 직접 토크 방식은 control effort가 더 낮았다.
처음에는 힘을 덜 쓰는 쪽이 더 좋은 것 같기도 했지만, 이번 결과에서는 직접 토크 방식이 힘을 덜 쓴 대신 목표에 잘 도달하지도 못했다. 그래서 이번 비교에서는 “힘을 적게 썼다”보다 “실제로 목표에 갔는가”가 더 중요하게 느껴졌다.
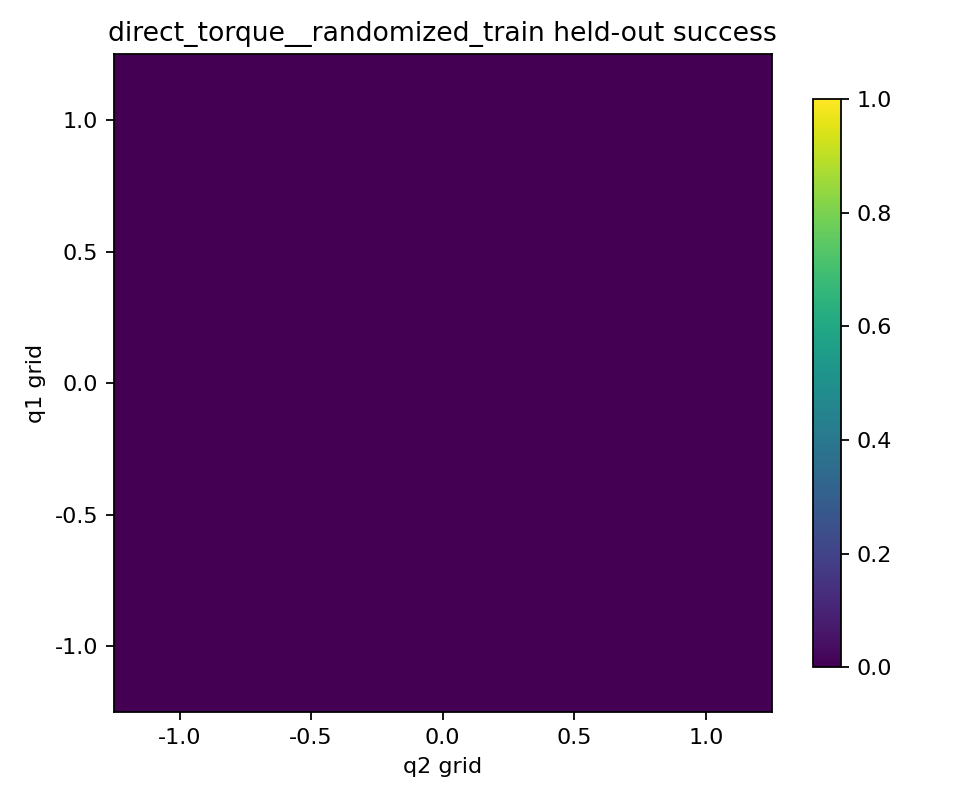
held-out 성공 heatmap을 보면
held-out 성공 heatmap은 두 실험 차이를 더 직관적으로 보여줬다.
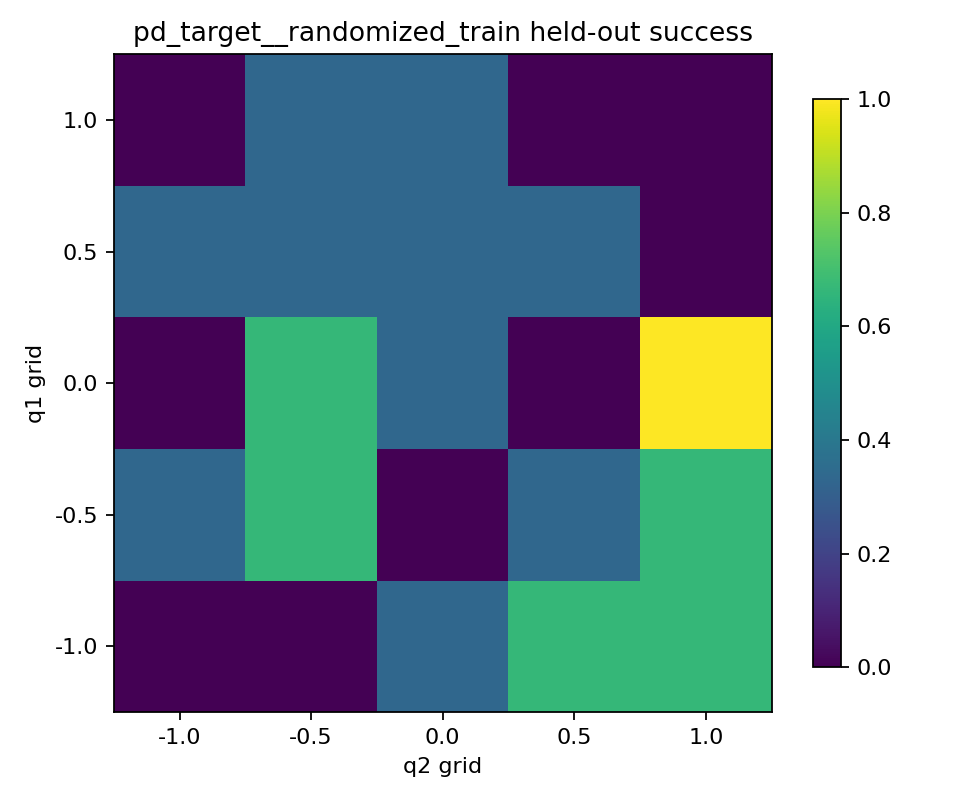
- 목표 각도 변화량 방식은 25개 고정 목표 중 일부에서는 분명히 성공했다.
- 특히 몇몇 영역은 절반 이상 성공한 칸도 있었고, 어떤 칸은 거의 항상 실패하는 식으로 차이가 보였다.
- 직접 토크 방식은 heatmap 전체가 전부 실패였다.
즉 직접 토크 방식은 안 본 목표에서 약한 정도가 아니라, 이번 설정에서는 아예 제대로 대응하지 못한 쪽에 더 가까워 보였다.
failure reason도 같이 보면
episode 종료 이유를 같이 세어 보니 차이가 더 분명했다.
- 목표 각도 변화량 방식
- primary:
success 18,joint_limit 37,time_limit 5 - held-out:
success 23,joint_limit 45,time_limit 7
- primary:
- 직접 토크 방식
- primary:
joint_limit 21,velocity_limit 39 - held-out:
joint_limit 27,velocity_limit 48
- primary:
내가 보기에는 이 차이가 꽤 중요했다. 뒤의 숫자들은 실패 횟수인데, 목표 각도 변화량 방식은 적어도 성공으로 끝난 episode가 있었고, 실패하더라도 주로 joint limit 쪽으로 끝났다. 반면 직접 토크 방식은 성공이 없었고, 특히 velocity limit으로 끝나는 경우가 많았다. 즉 직접 토크 방식 쪽이 더 거칠고 불안정하게 움직였다고 해석할 수 있었다.
액션 방식 비교에 대한 결론
이번 비교만 놓고 보면, 같은 randomized_train 조건에서는 직접 토크 방식보다 목표 각도 변화량 방식이 PPO 학습에 훨씬 더 유리했다. 성공률, final distance, held-out heatmap, failure reason을 같이 보면 직접 토크 방식은 아직 “더 어렵지만 해볼 만하다” 수준보다, 이번 설정에서는 거의 제대로 학습이 안 된 쪽에 더 가까웠다.
다만 여기서 바로 “직접 토크 방식은 항상 안 된다”라고까지 말할 수는 없다고 느꼈다. reward나 토크 제한, 학습 step, PPO 설정을 더 조정하면 달라질 수도 있기 때문이다. 그래도 적어도 이번 비교에서는, 예전에 내가 목표 각도 변화량 방식을 먼저 고른 이유가 결과로도 어느 정도 확인됐다고 볼 수 있었다.
왜 target 조건도 따로 비교해 보려고 했나?
이전 포스팅에서도 목표 위치는 episode마다 계속 바뀌었지만, 그때는 “한 점만 배우는 정책”과 “여러 목표를 보면서 배우는 정책”을 따로 나눠서 본 적은 없었다. 그래서 학습이 되는지 정도는 볼 수 있었지만, target 조건이 바뀌면 정책 성격이 어떻게 달라지는지는 알 수 없었다.
이번 확장판에서는 이 부분을 조금 더 분리해서 보고 싶었다. 한 점만 반복해서 학습하면 그 한 점에서는 훨씬 잘 가게 되는지, 반대로 여러 목표를 랜덤하게 보면서 학습하면 안 본 목표들에서도 더 잘 대응하게 되는지를 확인하고 싶었다.
그래서 이번에는 action은 이미 더 잘 맞았던 목표 각도 변화량 방식으로 고정하고, target 조건만 바꿔 보기로 했다. 비교하려는 조건은 두 가지다.
fixed_single학습 내내 사실상 한 점 목표만 보게 하는 조건randomized_train학습 중 목표가 계속 바뀌는 조건
내가 특히 보고 싶은 것은 두 가지였다. 첫째, 한 점만 배운 정책이 자기 문제에서는 얼마나 강해지는지 보는 것이다. 둘째, 여러 목표를 보며 학습한 정책이 정말 held-out 목표들에서도 더 잘 되는지 확인하는 것이다. 즉 이번 target 비교는 “어떤 목표 분포로 학습시키는 게 더 좋은가?”를 보기 위한 실험이라고 정리할 수 있다.
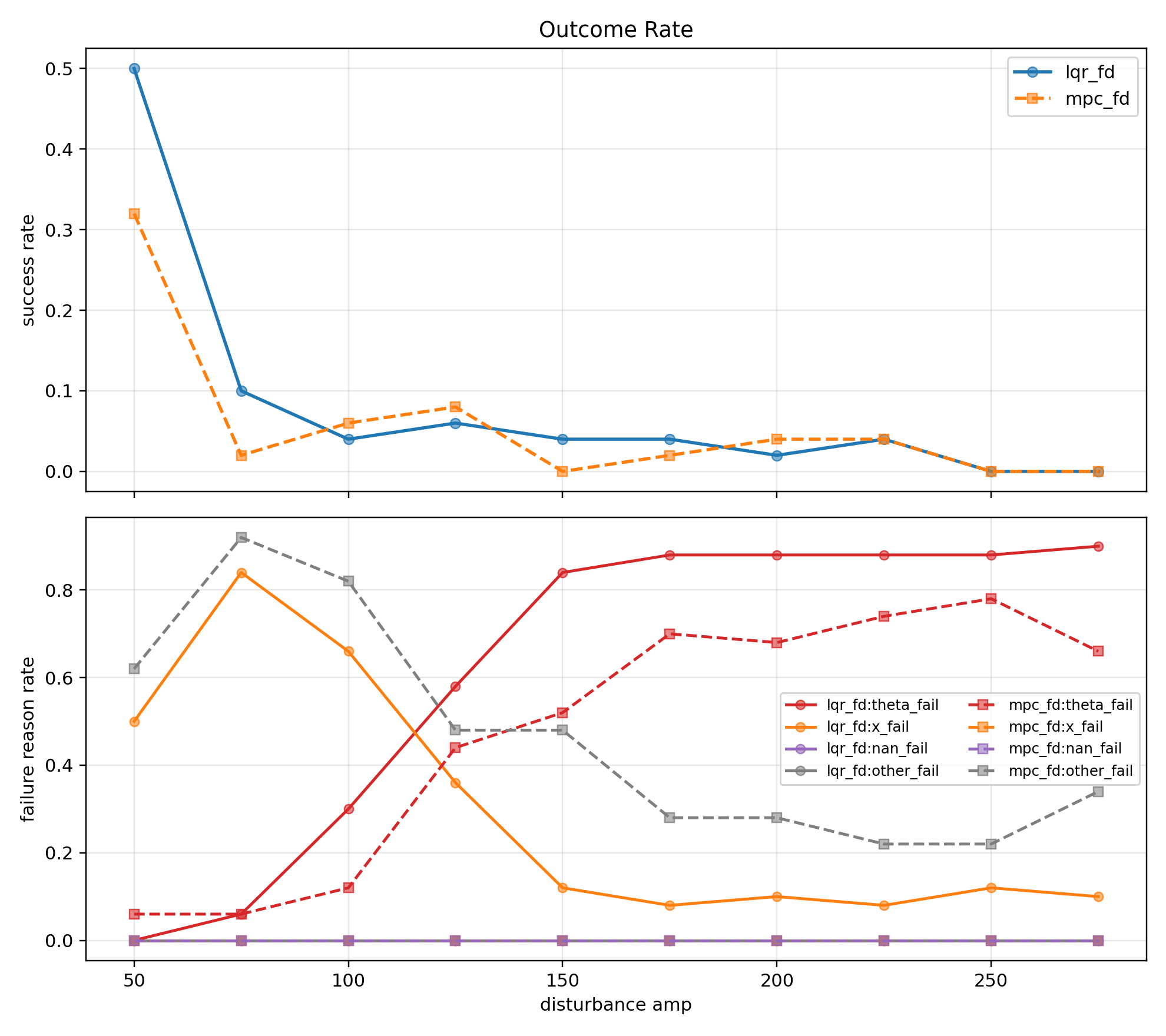
target 조건 비교 실험 결과
이번에는 action은 둘 다 목표 각도 변화량 방식으로 고정하고, target 조건만 바꿔서 비교했다.
pd_target__fixed_singlepd_target__randomized_train
각 실험은 seed 7, 11, 21로 돌렸고, 각 seed마다 100000 step 학습했다. 그 뒤 run별 평가를 돌리고, 마지막에 aggregate 결과를 모아서 비교했다.
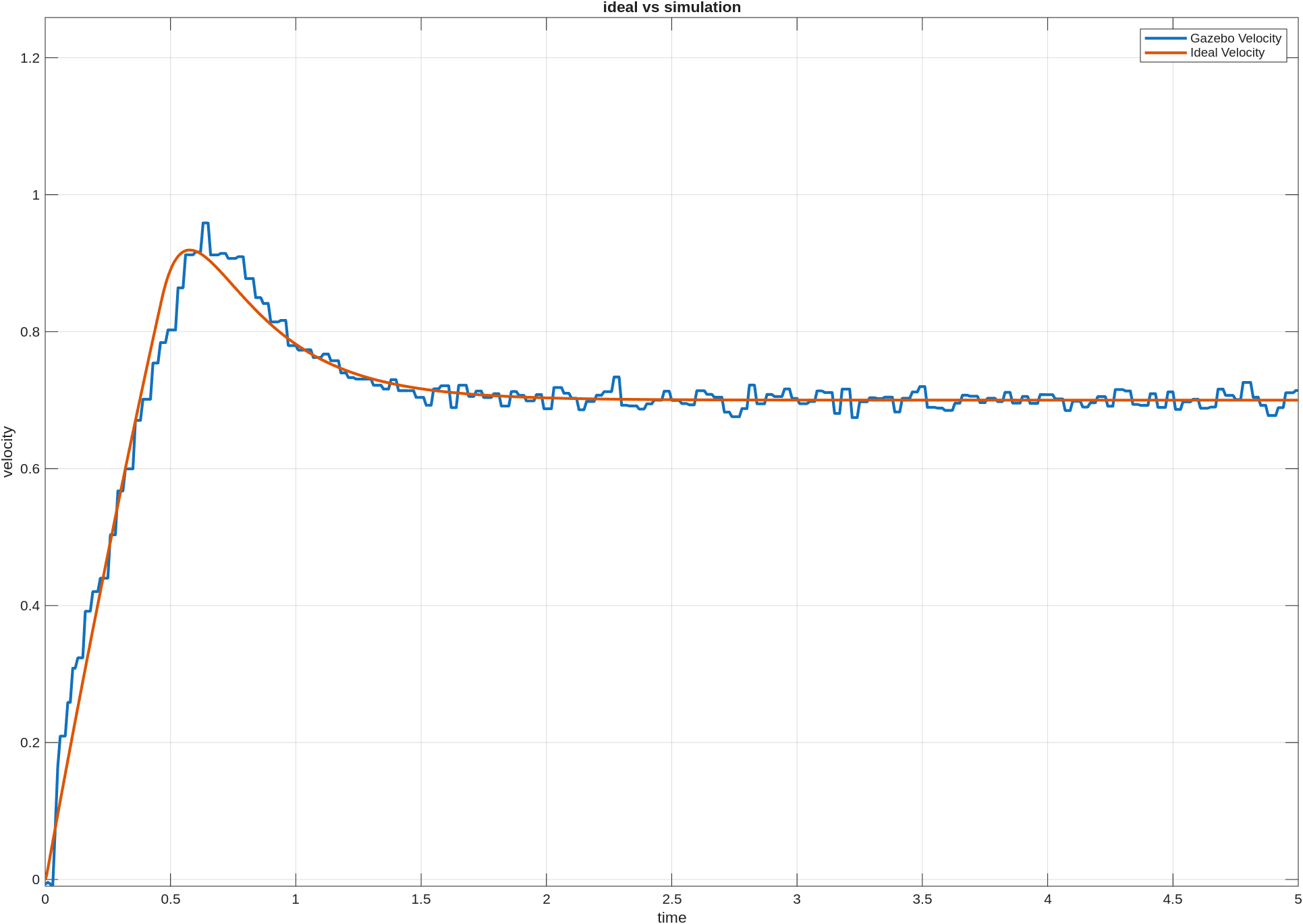
여기서 fixed_single은 정말 한 점만 향하도록 학습시키는 조건이었다. 코드에서는 고정 관절각 q_goal = [0.3, 0.8]을 먼저 정하고, 그 자세에서의 발끝 위치를 목표점으로 썼다. 실제 목표 좌표는 대략 (1.187, -1.409)였다. 즉 fixed_single 실험은 학습 내내 이 한 점을 향해 가는 정책을 만든다고 이해하면 된다.
다만 이번 비교에서는 primary를 읽을 때 조금 조심해야 했다. fixed_single의 primary는 한 점 목표에서의 평가이고, randomized_train의 primary는 랜덤 목표들에서의 평가라서, primary 성능 차이에는 문제 난이도 차이도 함께 들어간다. 그래서 이번에는 primary는 “자기 문제에서 얼마나 잘했는가”를 보는 용도로 보고, 진짜 일반화 비교는 held-out 쪽을 더 중요하게 보기로 했다.
aggregate 숫자부터 보면
| 실험 | primary best success rate | held-out success rate | primary best mean final distance | held-out mean final distance |
|---|---|---|---|---|
| fixed single | 86.7% |
56.0% |
0.072 |
0.256 |
| randomized train | 30.0% |
30.7% |
0.538 |
0.378 |
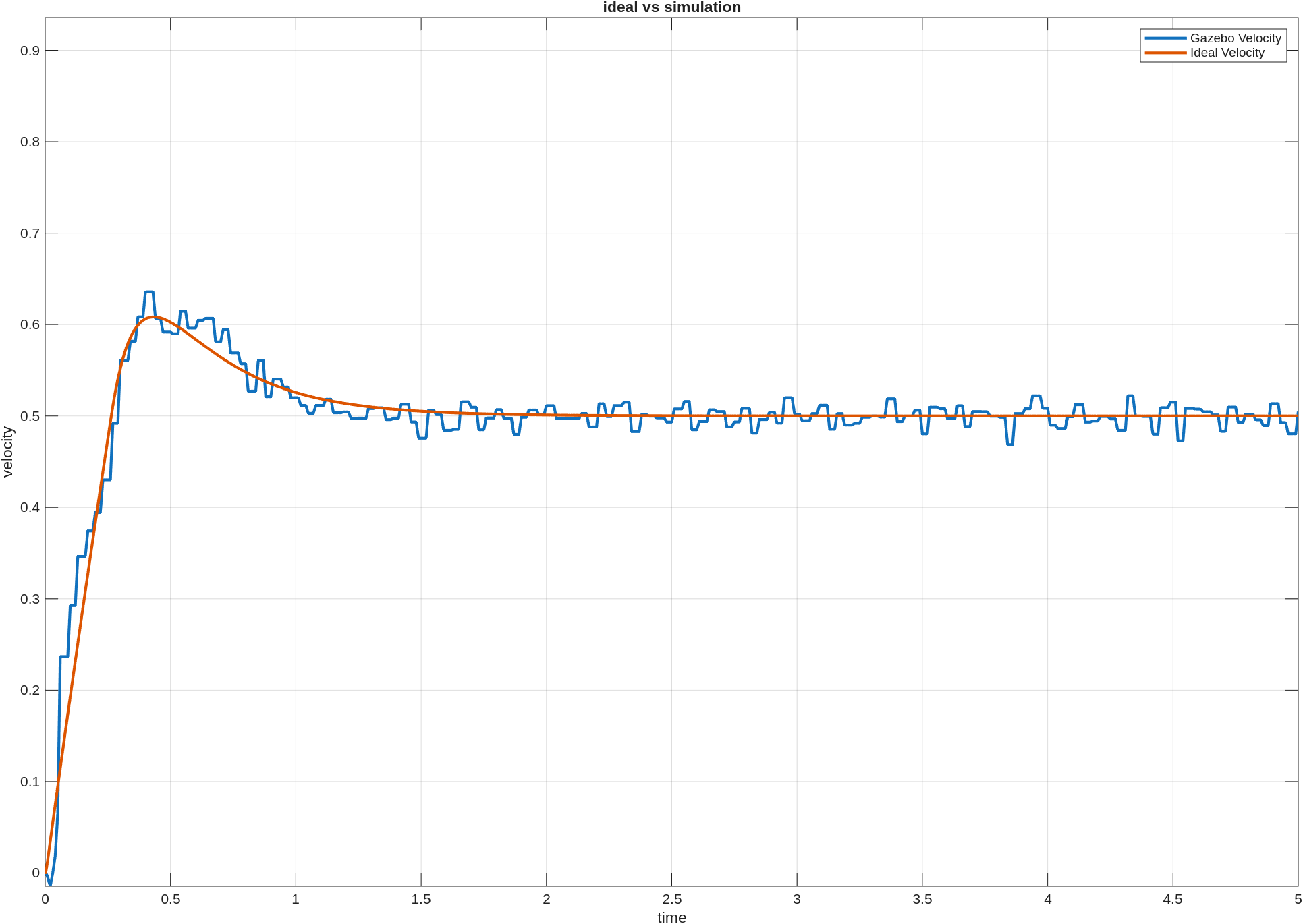
처음에는 randomized_train이 여러 상황에 대해서 학습을 진행하니까 held-out에서 더 좋을 수도 있겠다고 생각했는데, 결과는 그렇지 않았다. fixed_single은 자기 문제에서는 당연히 훨씬 강했고, held-out에서도 오히려 더 높은 success rate와 더 낮은 final distance를 보였다.
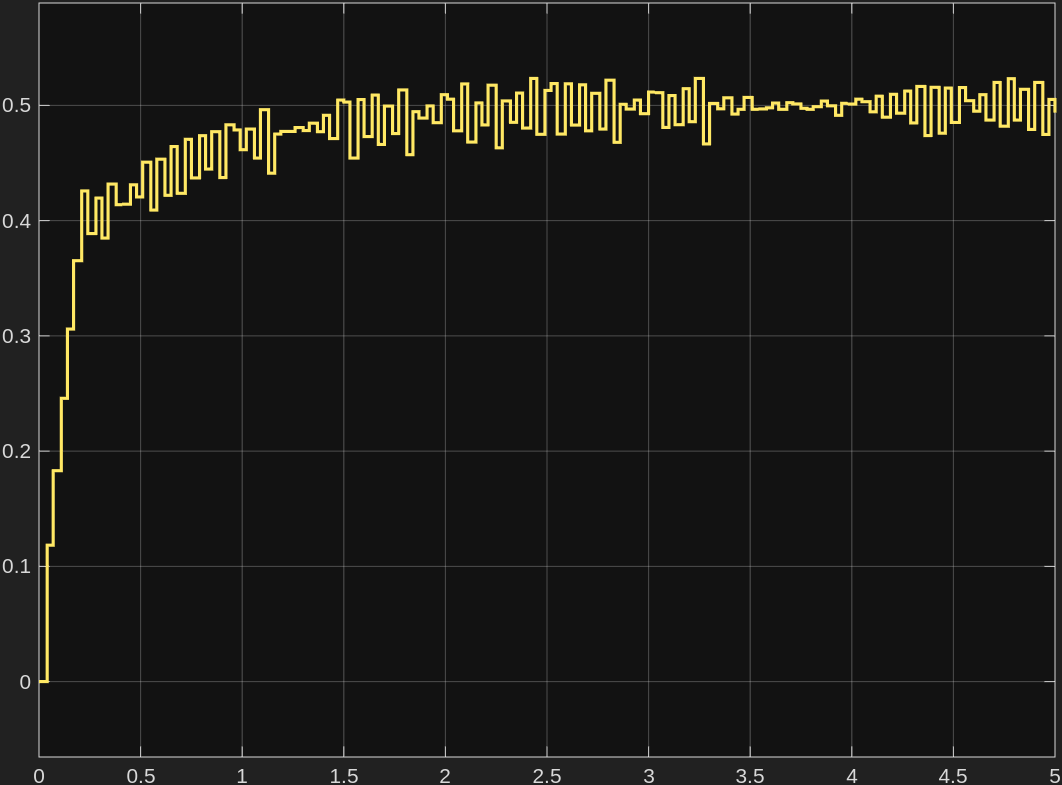
성공률 그래프를 보면
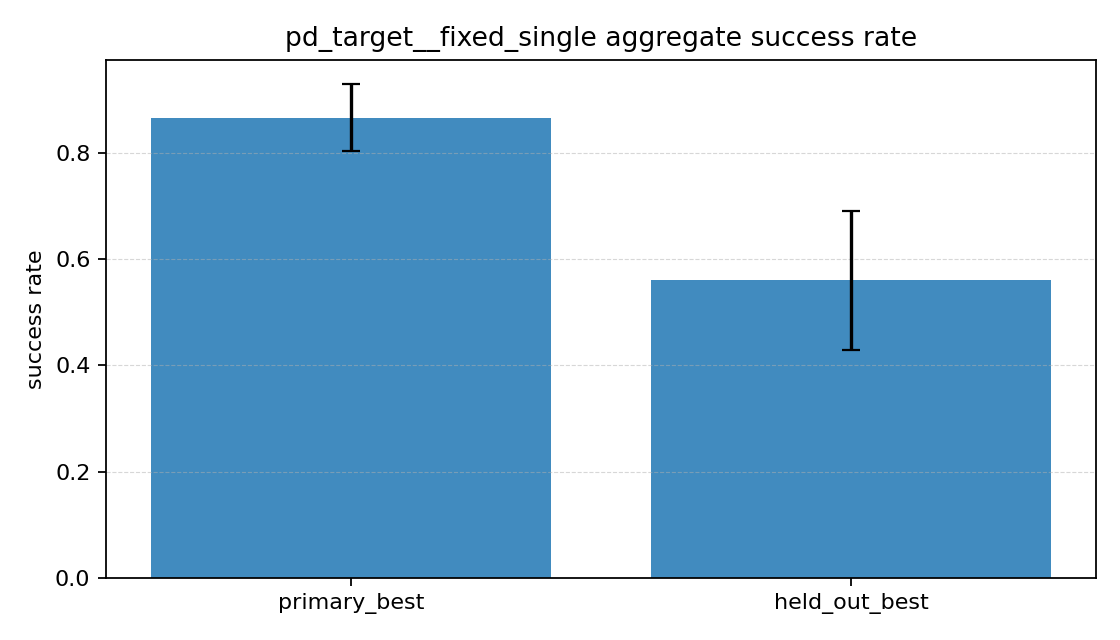
fixed_single은 primary에서 거의0.87까지 올라갔다.randomized_train은 primary가0.30정도였다.- held-out에서도
fixed_single이0.56,randomized_train이0.31정도로 차이가 났다.
primary는 문제 자체가 다르니 당연한 차이가 일부 섞여 있다고 봤다. 하지만 held-out에서도 fixed_single이 더 높았다는 점은 예상과 조금 달랐다. 이번 설정에서는 여러 목표를 랜덤하게 보면서 학습한 것이 곧바로 더 좋은 일반화로 이어지지는 않았다.
최종 거리 그래프를 보면
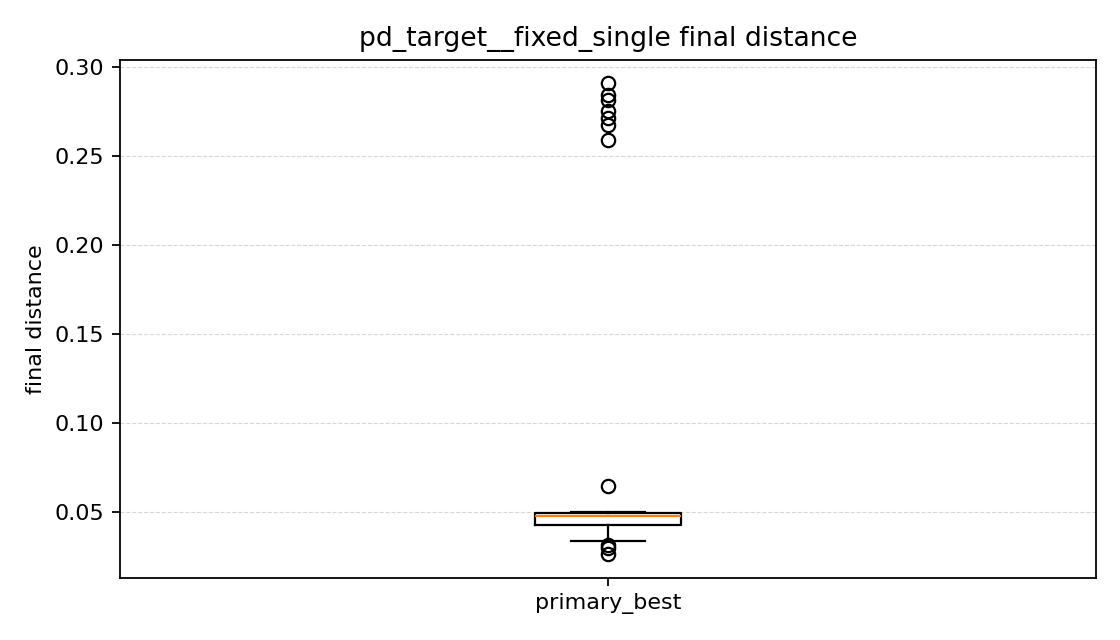
이 그래프도 박스플롯이라서 액션 비교 때와 같은 식으로 읽었다.
이번 결과에서는 fixed_single 쪽 박스와 주황선이 훨씬 아래에 있었다. 즉 대부분의 episode가 목표 근처에서 끝났고, 중앙값도 아주 낮았다. 한 점을 반복해서 학습한 만큼, 적어도 자기 문제에서는 훨씬 정확하게 가는 정책이 만들어졌다고 볼 수 있었다.
randomized_train은 박스가 더 위쪽에 있고 분포도 넓었다. 어떤 경우에는 어느 정도 가까이 가기도 했지만, 전체적으로 보면 목표에서 더 먼 상태로 끝나는 episode가 훨씬 많았다. held-out 평균 final distance도 fixed_single이 0.256, randomized_train이 0.378이라서, 이번 실험에서는 안 본 목표들에서도 fixed_single이 더 유리했다.
제어 effort 그래프를 보면
제어 effort는 각 episode 동안 나온 토크의 크기를 계속 더해서 만든 값이다(액션과 동일).
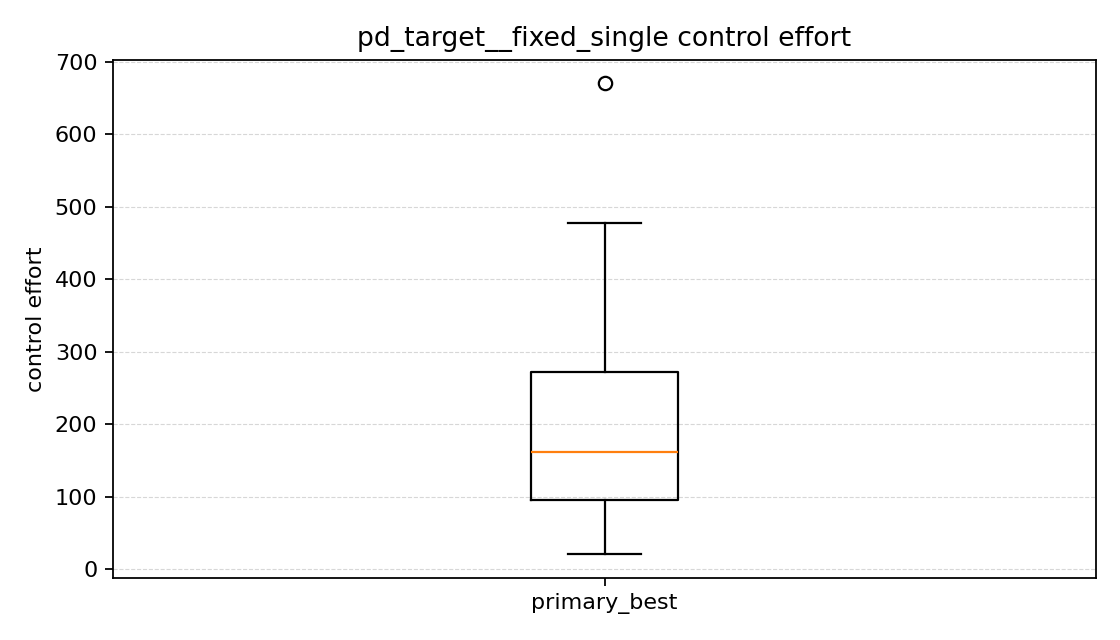
이번에는 fixed_single 쪽이 control effort도 조금 더 낮았다. primary 기준 평균 control effort는 fixed_single이 약 201.1, randomized_train이 약 218.6이었다. held-out에서도 fixed_single이 약 176.3, randomized_train이 약 200.3으로 더 낮았다.
즉 이번 비교에서는 fixed_single이 더 잘 갔을 뿐 아니라, 토크를 크게 낭비하지도 않았다. 여러 목표를 상대하는 쪽이 더 일반적일 것이라고 생각했지만, 현재 reward와 학습 step에서는 오히려 그만큼 더 어려운 문제를 풀게 되면서 제어 effort도 조금 더 커진 것으로 보였다.
held-out 성공 heatmap을 보면
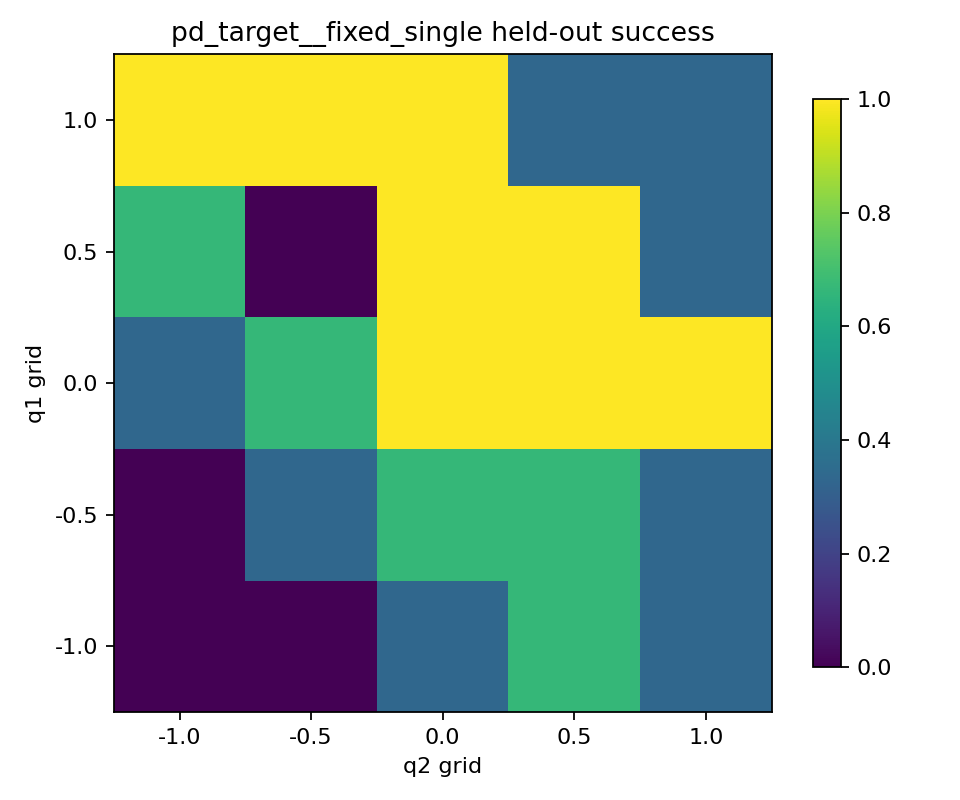
이 그래프는 두 실험 차이를 꽤 직관적으로 보여줬다.
fixed_single은 held-out 25개 목표 중 밝은 칸이 더 많았다.randomized_train도 일부 칸에서는 성공했지만, 어두운 칸이 더 많고 전체적으로 덜 안정적이었다.
조금 더 들여다보면 fixed_single의 밝은 칸들은 아무 데나 있는 것이 아니라, 학습 때 반복해서 보던 고정 목표와 발끝 위치가 비교적 가까운 쪽에서 더 많이 나타났다. 다만 여기서 주의할 점은, heatmap 축이 (x, y) 좌표가 아니라 (q1, q2) 관절각 grid라는 점이다. 그래서 “학습한 관절각 q_goal = [0.3, 0.8] 근처 칸만 밝다”처럼 단순하게 읽으면 맞지 않을 수 있다.
실제로는 같은 발끝 위치와 비슷한 Cartesian 목표를 여러 관절각 조합으로 만들 수 있기 때문에, 학습한 관절각과 joint-space에서 아주 가깝지 않아도 heatmap에서 밝게 나오는 칸이 있었다. 예를 들어 fixed_single이 학습한 한 점 목표 (1.187, -1.409)와 Cartesian 거리상 가까운 held-out 목표들 중에는 (q1, q2) = (0.5, 0.5), (1.0, -0.5), (0.0, 1.0), (1.0, -1.0) 같은 칸들이 있었고, 이런 칸들은 실제로 1.0으로 잘 성공했다.
즉 이번 heatmap은 “한 점만 학습한 정책이 안 본 모든 목표를 고르게 잘 간다”기보다, 학습한 한 점과 위치상 비슷한 목표들에는 더 잘 퍼지고, 멀거나 joint limit에 불리한 영역에서는 여전히 약하다는 쪽으로 읽는 게 더 맞아 보였다. 이런 점을 보면, held-out 평가도 결국 학습한 목표와 완전히 무관한 것이 아니라, 학습했던 한 점의 영향이 남아 있는 상태에서 일반화를 보고 있다고 이해할 수 있었다.
failure reason도 같이 보면
episode 종료 이유를 같이 세어 보니 차이가 더 분명했다.
- fixed single
- primary:
success 52,joint_limit 7,time_limit 1 - held-out:
success 42,joint_limit 23,time_limit 10
- primary:
- randomized train
- primary:
success 18,joint_limit 37,time_limit 5 - held-out:
success 23,joint_limit 45,time_limit 7
- primary:
이번 비교에서는 randomized_train이 더 자주 joint limit에 걸렸다. 즉 여러 목표를 동시에 상대하는 동안 아직 충분히 안정적인 움직임을 배우지 못한 경우가 더 많았다고 볼 수 있었다. 반대로 fixed_single은 한 점을 강하게 익힌 덕분인지 성공으로 끝나는 episode가 훨씬 많았다.
target 조건 비교에 대한 결론
이번 결과만 놓고 보면, 현재 설정에서는 randomized_train이 fixed_single보다 더 좋은 일반화를 보여주지 못했다. 오히려 fixed_single이 자기 문제에서는 훨씬 강했고, held-out에서도 더 높은 success rate와 더 낮은 final distance를 보였다.
다만 이걸 바로 “항상 한 점만 학습하는 것이 더 낫다”라고 해석할 수는 없다고 느꼈다. 지금은 success 정의도 단순하고, reward와 학습 step도 아직 초보적인 설정이다. 그래서 이번 결과는 “여러 목표를 랜덤하게 주면 무조건 더 좋은 일반화가 나온다”는 기대가 지금 설정에서는 성립하지 않았다는 정도로 이해하는 것이 더 맞아 보였다.
왜 reward도 따로 비교해 보려고 했나?
액션과 target 비교까지 해 보니, 이제 남은 큰 축은 reward라고 느껴졌다. 이전 포스팅과 이번 확장 실험 초반에는 reward를 거의 그대로 두고 action 방식과 target 조건만 바꿔 봤다. 그 덕분에 “무엇을 바꿔서 어떤 차이가 났는지”는 보기 쉬웠지만, 반대로 reward 자체가 지금 결과를 얼마나 끌고 가고 있는지는 아직 제대로 본 적이 없었다.
내가 궁금했던 것은 이런 점이었다. 목표에 가까워지는 것만 강하게 밀어주는 reward를 쓰면 더 빨리 가기는 할지 몰라도 움직임이 거칠어질 수 있다. 반대로 속도 항이나 action 항까지 같이 두면 성공률은 조금 떨어져도 더 안정적이고 덜 과격한 움직임을 만들 수도 있다. 즉 reward를 어떻게 짜느냐에 따라, policy가 “무엇을 더 중요하게 배우는지”가 달라질 수 있다고 느꼈다.
그래서 다음에는 action은 이미 더 잘 맞았던 목표 각도 변화량 방식으로 고정하고, target도 비교 기준으로 쓰기 쉬운 조건으로 고정한 뒤, reward 구성만 바꿔서 보려고 한다. 내가 보고 싶은 것은 세 가지다.
- 위치 오차만 보는 reward가 정말 더 빨리 학습되는지
- 속도 항을 넣으면 움직임이 얼마나 더 안정적으로 바뀌는지
- action 항까지 넣으면 제어 effort나 움직임 거칠기가 줄어드는지
즉 이번 reward 비교는 “같은 문제를 풀더라도 policy가 어떤 성격의 움직임을 배우게 할지”를 reward가 어떻게 바꾸는지 확인하기 위한 실험이라고 정리할 수 있다.
reward는 어떤 케이스로 나눴나?
이번 reward 비교에서는 action과 target은 고정하고, reward 구성만 세 가지로 나눠 보기로 했다.
- action: 목표 각도 변화량 방식
- target:
randomized_train
즉 같은 문제를 풀게 두고, policy가 무엇을 더 중요하게 배우는지만 reward로 바꿔 보려는 실험이다.
이번에 나눈 reward 케이스는 아래 세 가지다.
position only- 위치 오차 항만 남기고
- 속도 항과 action 항은
0으로 둔다 - 목표에 가까워지는 것만 가장 직접적으로 밀어주는 reward다
position + velocity- 위치 오차 항과 속도 항을 같이 둔다
- action 항은
0으로 둔다 - 목표에 가는 것뿐 아니라 너무 빠르게 흔들리는 움직임도 조금 줄여 보려는 설정이다
position + velocity + action- 위치 오차, 속도, action 항을 모두 둔다
- 지금까지 기본으로 쓰던 reward와 같은 구성이다
- 목표에 가되, 움직임과 입력이 너무 과격하지 않게 하려는 의도가 들어 있다
정리하면 이번 비교는 reward를 단순하게 할수록 더 빨리 가는 쪽으로 배울지, 아니면 속도와 action 항을 함께 둘 때 더 안정적이고 덜 거친 정책이 나오는지를 보려는 실험이다.
reward 비교 실험 결과
각 실험은 seed 7, 11, 21로 돌렸고, 각 seed마다 100000 step 학습했다. 그 뒤 run별 평가를 돌리고, 마지막에 aggregate 결과를 모아서 비교했다.
aggregate 숫자부터 보면
| 실험 | primary best success rate | held-out success rate | primary best mean final distance | held-out mean final distance |
|---|---|---|---|---|
| position only | 33.3% |
42.7% |
0.480 |
0.240 |
| position + velocity | 23.3% |
18.7% |
0.560 |
0.485 |
| position + velocity + action | 30.0% |
30.7% |
0.538 |
0.378 |
숫자만 먼저 보면 의외의 결과가 나왔다. 위치 오차만 보는 position only가 성공률과 held-out 최종 거리에서 제일 좋았다. 반대로 속도 항만 추가한 position + velocity는 세 실험 중 가장 성능이 낮았다. position + velocity + action은 그 중간쯤에 있었다.
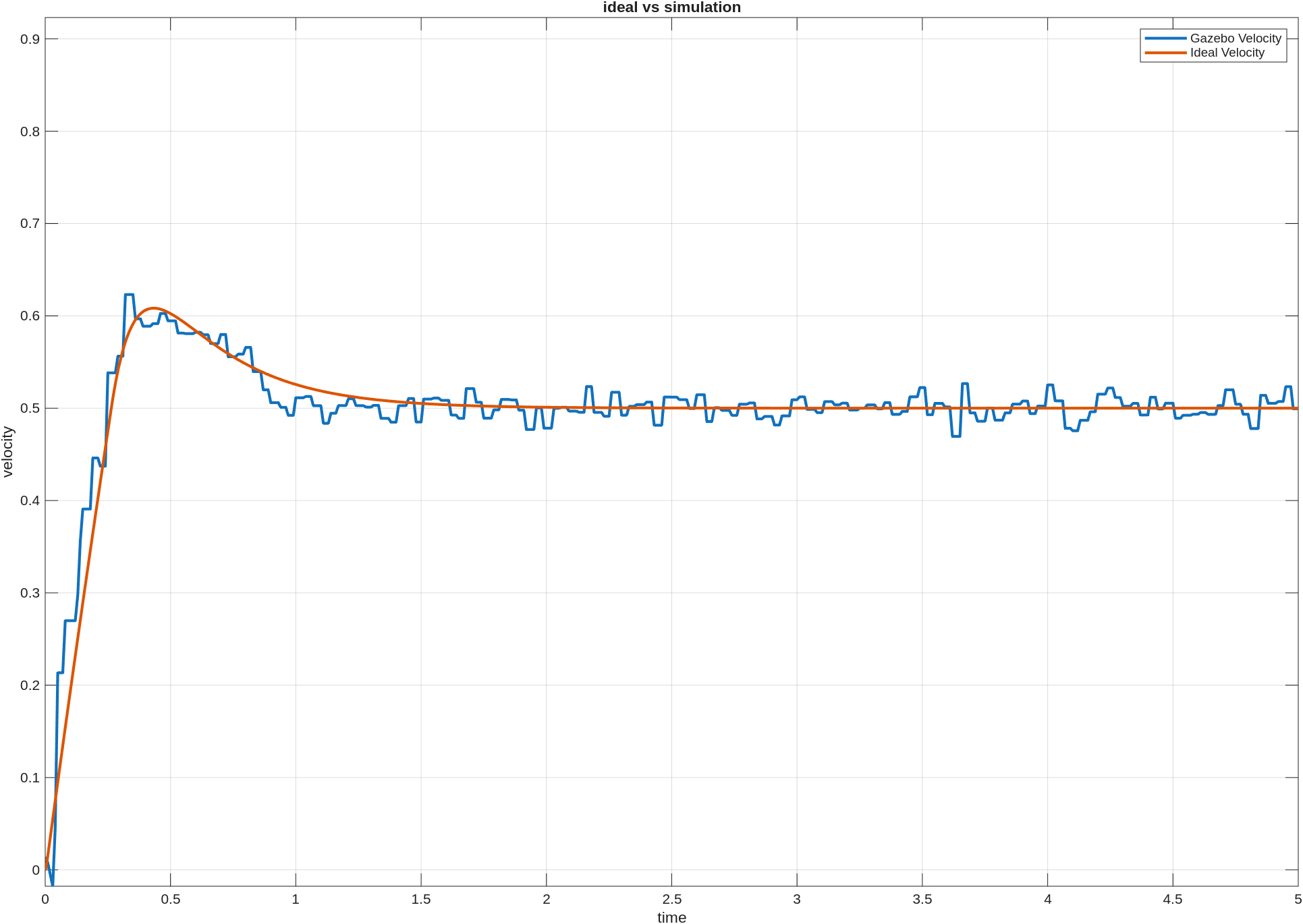
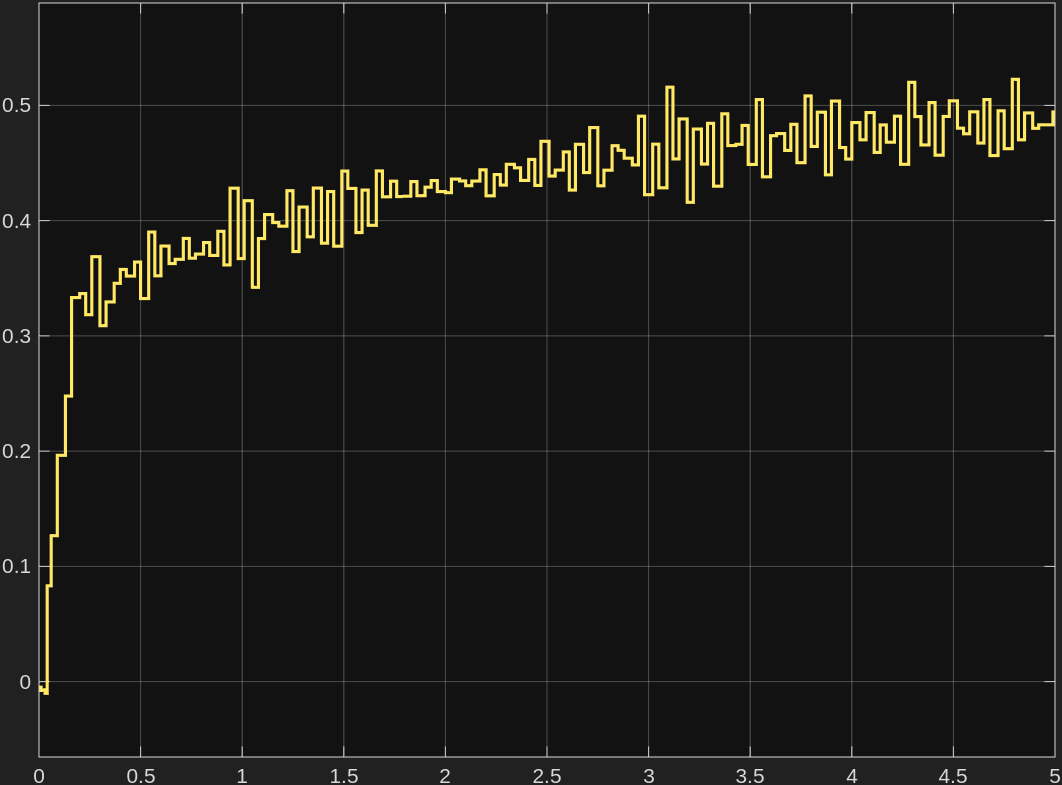
성공률 그래프를 보면
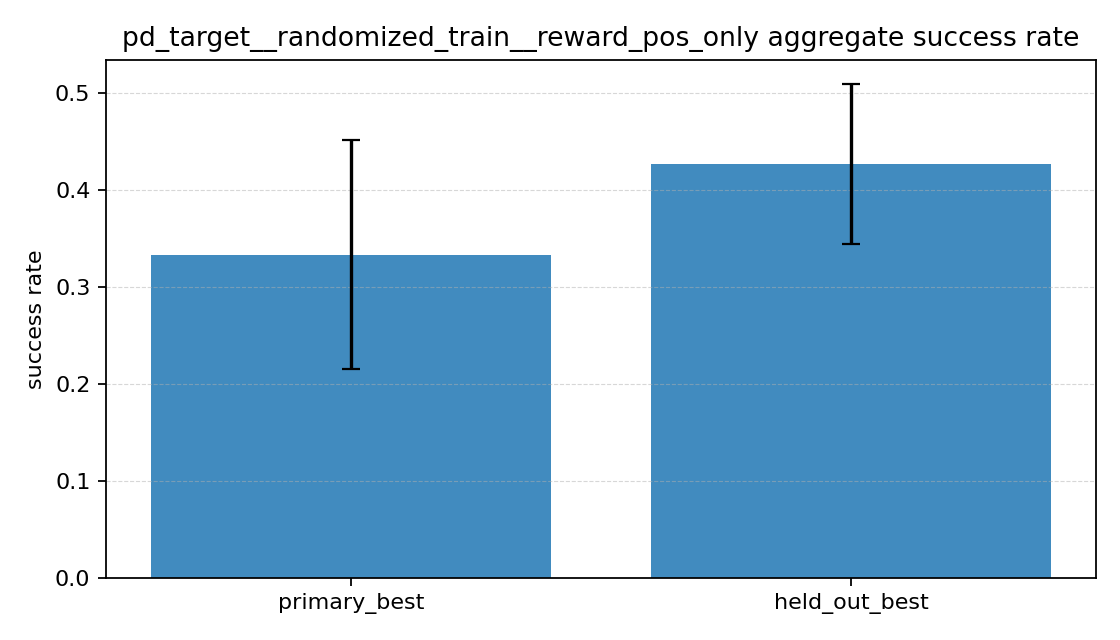
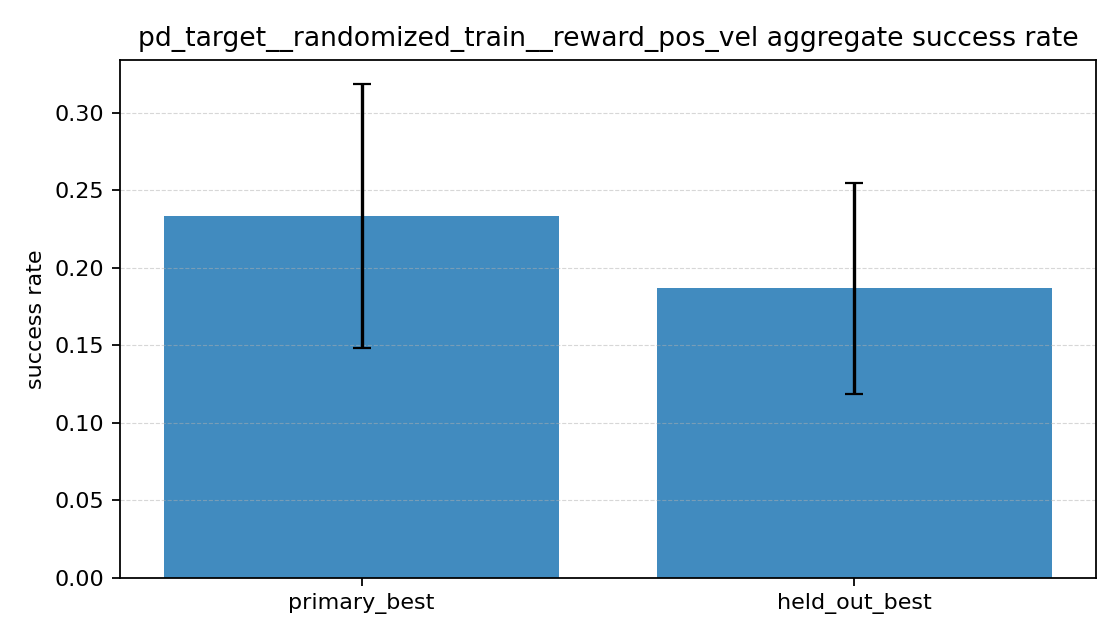
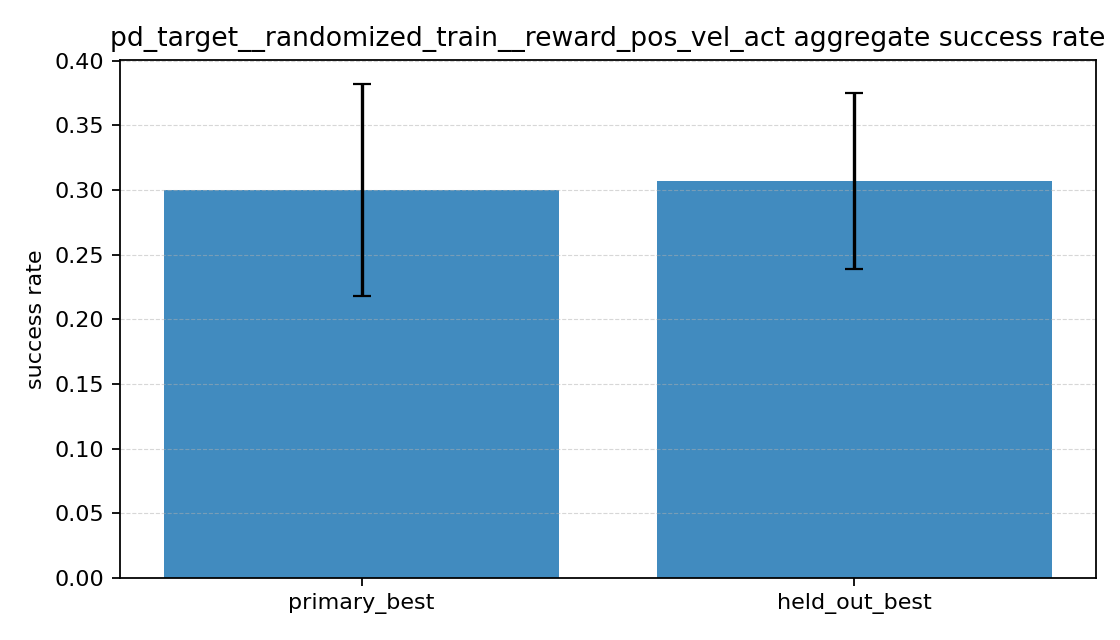
position only는 primary보다 held-out success가 오히려 더 높았다.position + velocity는 primary와 held-out 둘 다 가장 낮았다.position + velocity + action은 둘 사이의 중간 정도였다.
처음에는 reward를 단순하게 하면 거칠게 움직여서 성능이 낮아질 수도 있겠다고 생각했는데, 이번 설정에서는 적어도 success rate 기준으로는 그렇지 않았다. 오히려 위치 오차만 강하게 밀어준 쪽이 더 자주 목표에 도달했다. 반면 속도 항을 추가한 position + velocity는 기대했던 “조금 더 안정적인 성공”보다, 성공 자체가 줄어든 쪽에 더 가까워 보였다.
최종 거리 그래프를 보면
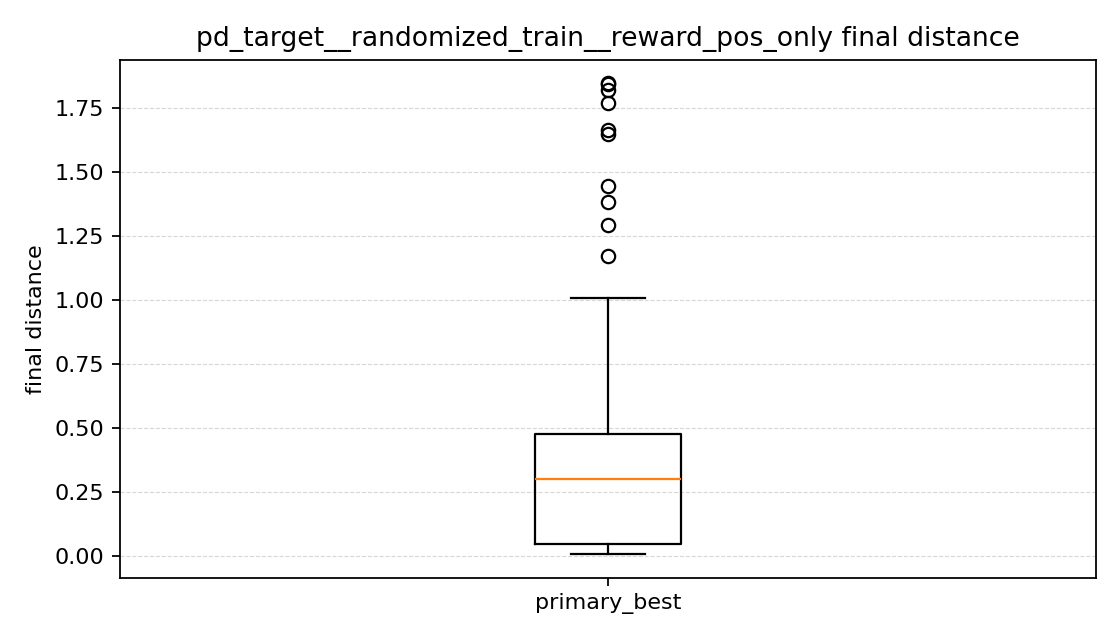
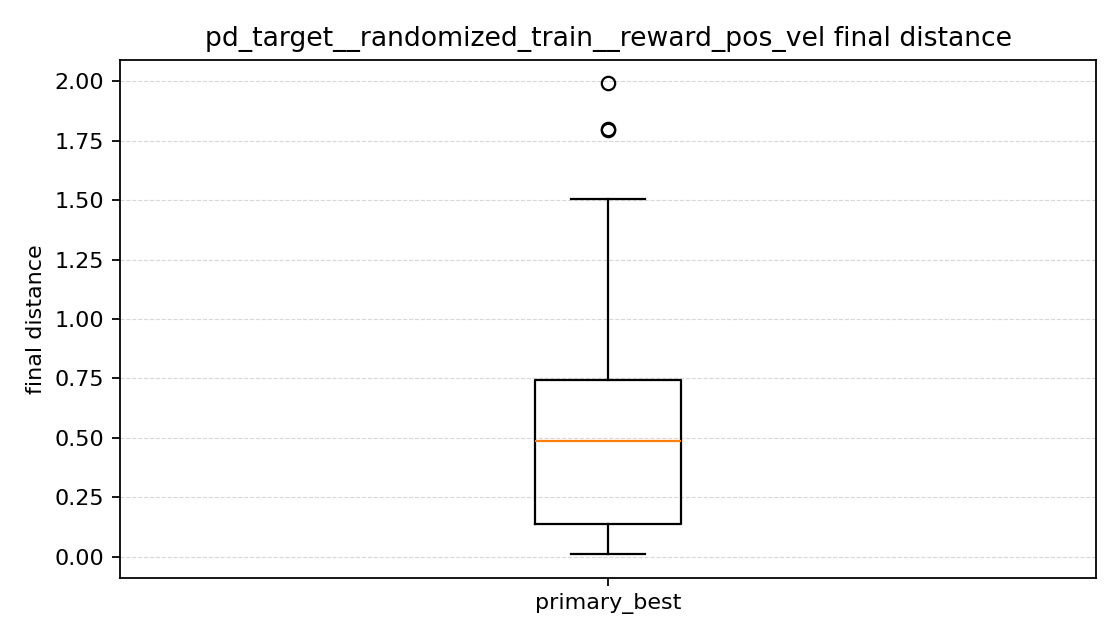
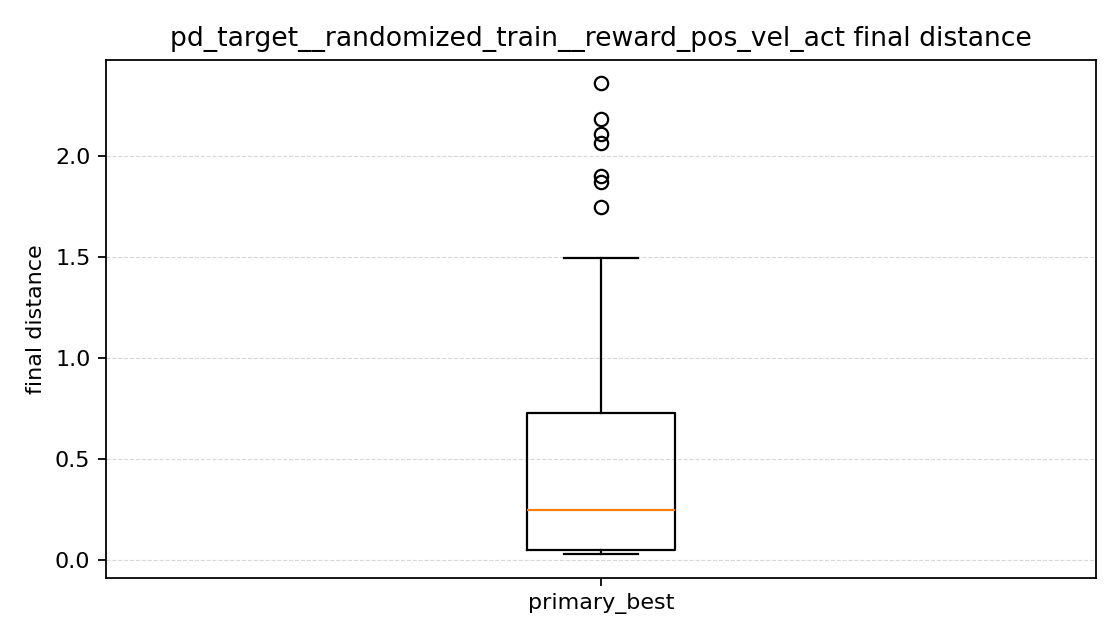
이번 결과에서는 position + velocity의 중앙값이 가장 높아서, 보통의 episode를 놓고 보면 목표에서 가장 멀리 끝나는 편이었다. 즉 속도 항만 넣는다고 해서 이번에는 더 안정적으로 가까이 가는 정책이 만들어지지는 않았다.
position only와 position + velocity + action은 조금 흥미로웠다. 중앙값만 보면 position + velocity + action이 더 낮아 보여서, 잘 되는 episode들만 놓고 보면 오히려 더 가까이 가는 경우도 있었다. 그런데 평균 final distance는 position only가 더 낮았다. 내가 보기에는 position + velocity + action 쪽이 보통은 잘 가더라도, 위쪽으로 크게 튀는 실패가 더 남아 있어서 평균이 올라간 것으로 보였다.
즉 최종 거리 그래프를 보면, position only는 성능이 좋은 episode와 아주 안 좋은 episode가 같이 있는 편이고, position + velocity + action은 중앙값은 낮지만 큰 실패가 아직 남아 있었다. position + velocity는 전체적으로 그 둘보다 더 멀리서 끝나는 경우가 많았다.
제어 effort 그래프를 보면
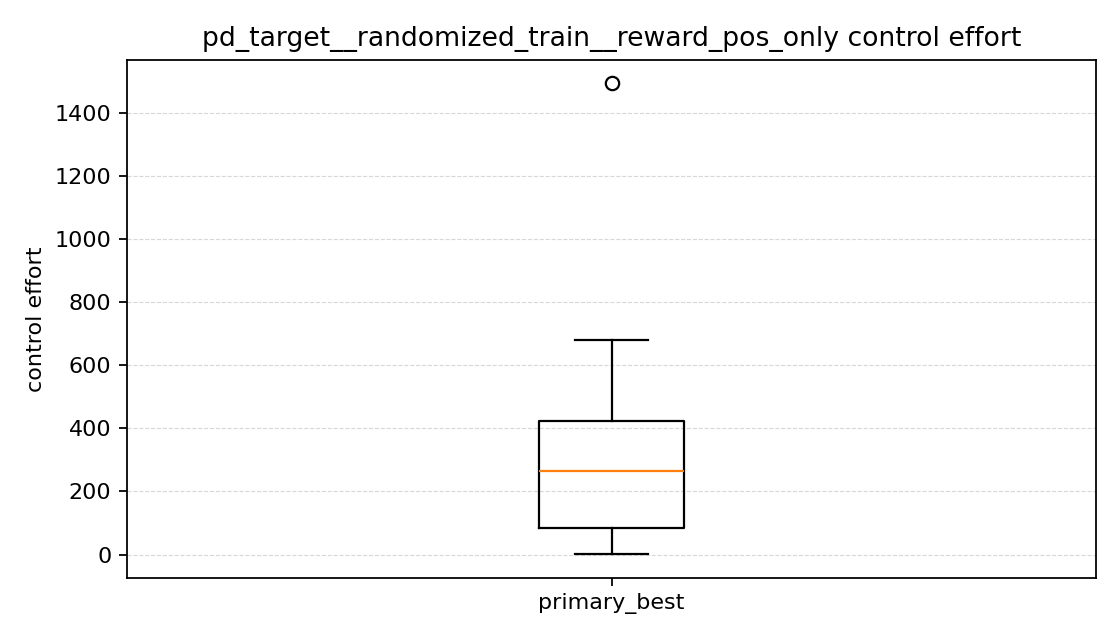
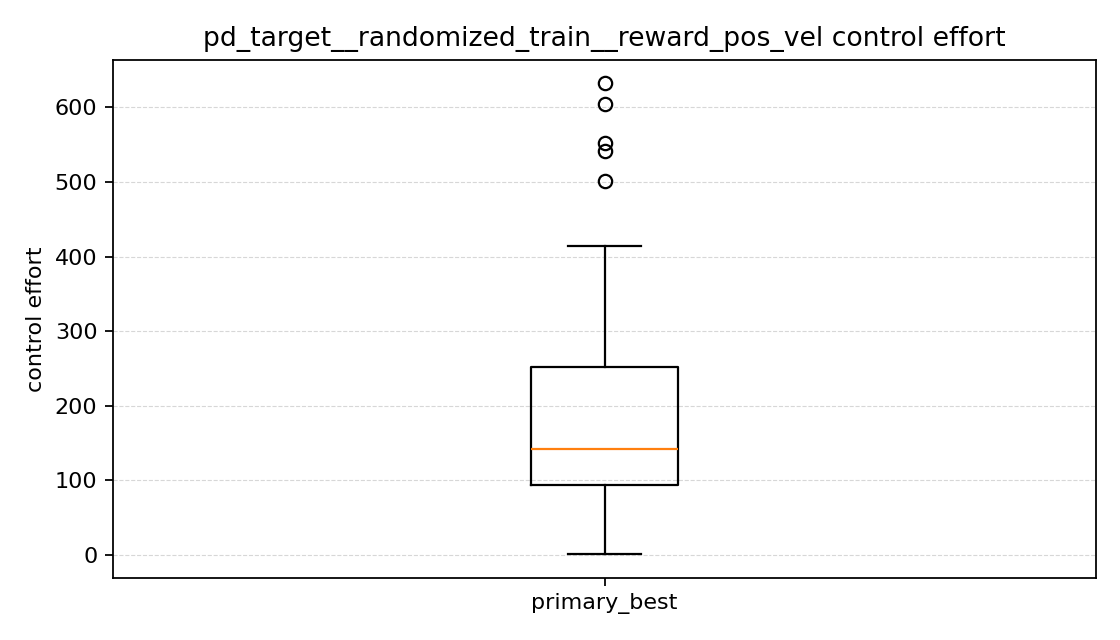
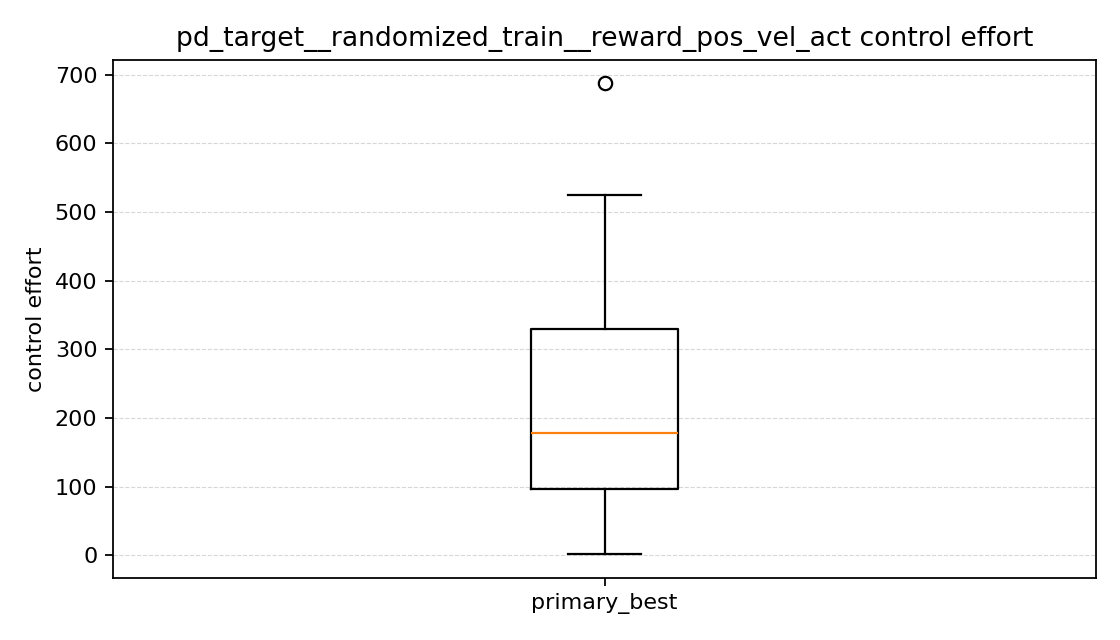
이 부분은 예상과 더 비슷했다.
position only는 control effort가 가장 컸다(y축 범위가 완전히 다르다).position + velocity는 control effort가 가장 낮았다.position + velocity + action은 그 중간이었다.
primary 기준 평균 control effort는
position only: 약293.3position + velocity: 약185.5position + velocity + action: 약218.6
였다. 여기서 내가 처음 헷갈렸던 점은, action 항으로 감점을 줬는데 왜 position + velocity + action의 control effort가 position + velocity보다 더 큰가 하는 점이었다.
지금 코드에서는 이 둘이 같은 값을 보는 것이 아니었다. reward의 action 항은 정규화된 action 크기 ||a||^2에 감점을 주고, control effort는 실제 토크의 누적량 ||tau||^2 * dt를 더해서 계산한다. 그런데 목표 각도 변화량 방식에서는 action이 바로 토크가 아니라, 먼저 목표 각도 변화로 바뀐 뒤 PD 제어기가 실제 토크를 만든다. 그래서 action을 조금 더 얌전하게 써도, 실제 토크 누적량이 꼭 같이 줄어드는 것은 아니었다.
여기서 action smoothness는 매 step에서 action이 이전 step과 얼마나 달라졌는지를 제곱해서 계속 더한 값이다. 그래서 값이 작을수록 action이 덜 튀고 더 부드럽게 바뀐다고 이해하면 된다.
이번 결과를 보면 이 차이가 실제로 나타났다. position + velocity + action은 position + velocity보다 action smoothness는 더 낮았지만, episode 길이는 더 길고 success도 더 많았다. 즉 더 부드럽게 움직이기는 했지만, 목표에 가기 위해 토크를 더 오래 쓰면서 누적 control effort는 오히려 조금 올라간 것으로 보였다. 반대로 position + velocity는 control effort는 더 낮았지만, joint limit에 더 자주 걸리고 더 빨리 끝나는 경우가 많아서 누적 토크가 작게 나온 면도 있었다.
즉 이번 그래프는 “action 항을 넣었는데도 토크를 더 썼다”기보다, action penalty는 action 크기를 줄이는 항이고 control effort는 실제 토크 누적량이라서 서로 직접 같은 값이 아니며, 이번에는 더 오래 버티고 더 자주 성공한 쪽이 토크를 더 오래 써서 effort가 조금 커졌다고 해석하는 게 더 맞아 보였다.
held-out 성공 heatmap을 보면
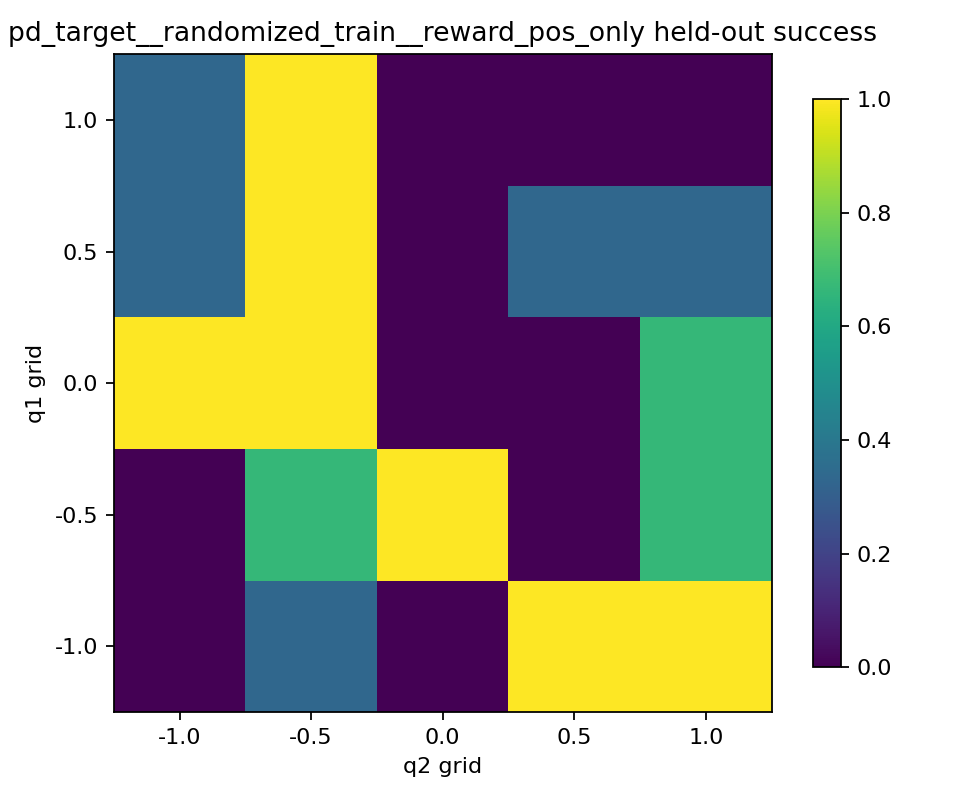
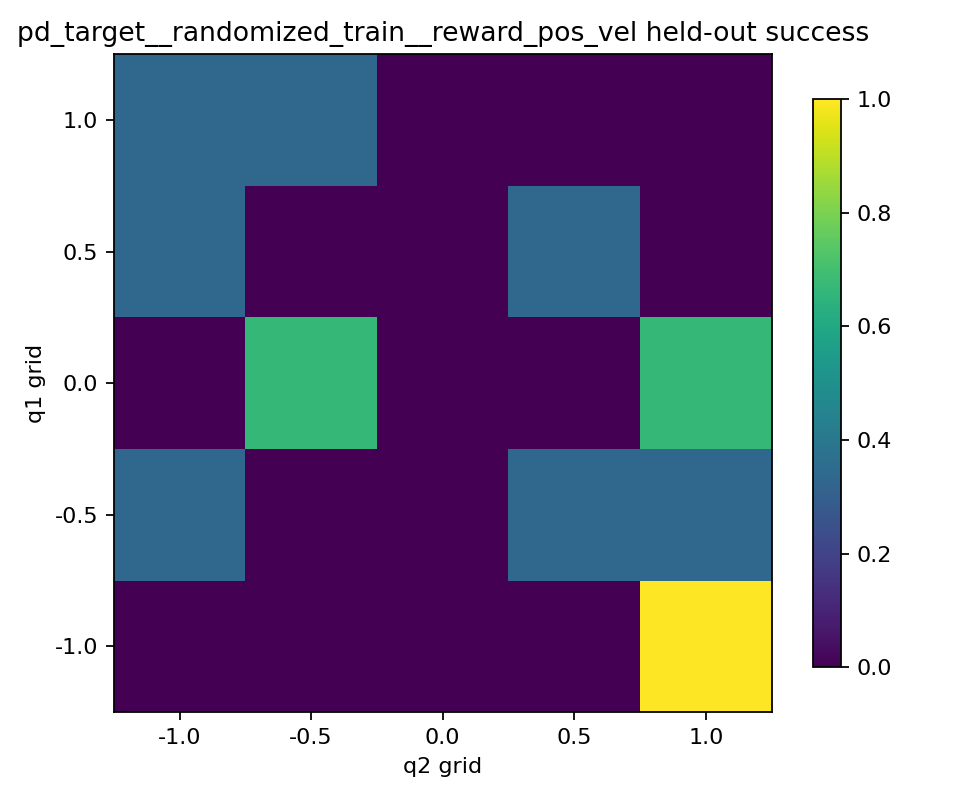
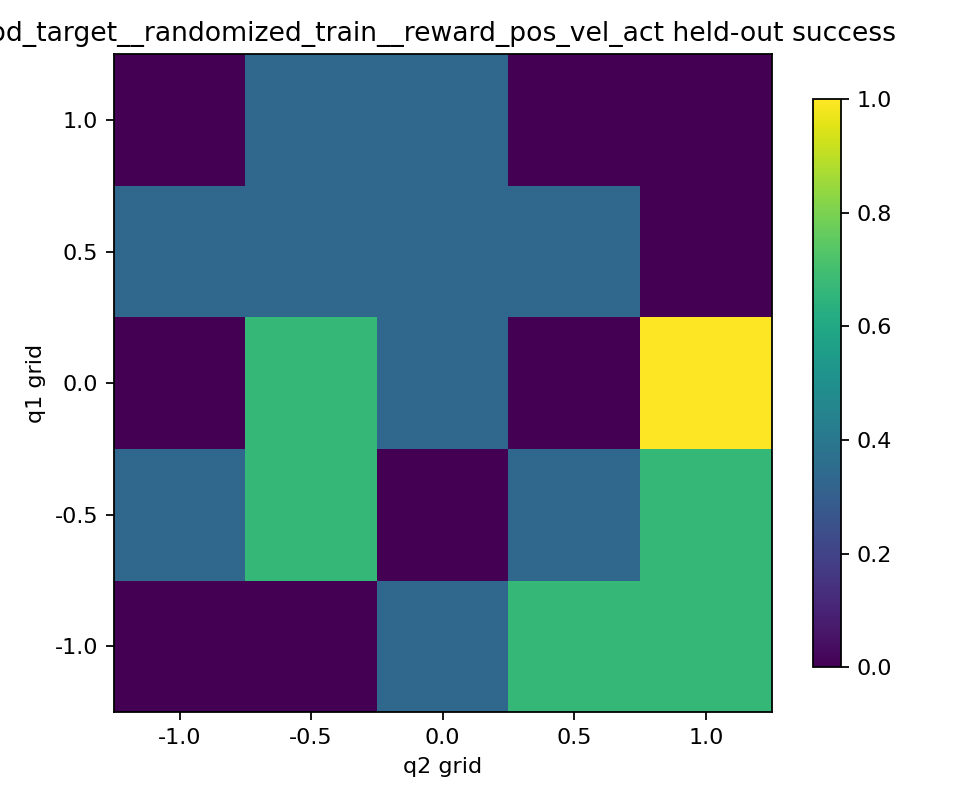
heatmap을 보면 세 reward의 성격 차이가 더 분명했다.
position only는 밝은 칸과 어두운 칸이 강하게 갈렸다.position + velocity는 전체적으로 어두운 칸이 많았다.position + velocity + action은position only보다 덜 극단적이지만, 더 넓게 퍼진 성공 칸들이 보였다.
즉 position only는 몇몇 held-out 목표에서는 아주 잘 성공하지만, 안 되는 곳은 확실히 안 되는 식으로 조금 더 거칠고 불연속적인 느낌이었다. 반면 position + velocity + action은 최고 성능 칸은 적더라도, 중간 정도로 성공하는 칸이 더 넓게 퍼져 있어서 전체적으로는 조금 더 고른 분포처럼 보였다.
position + velocity는 이 둘 사이의 장점을 잘 못 살린 느낌이었다. 조심스럽게 움직이기는 하지만, 그렇다고 넓게 일반화된 성공 영역을 만들지도 못했다.
failure reason도 같이 보면
episode 종료 이유를 같이 세어 보니 reward 차이가 또 다르게 보였다.
- position only
- primary:
success 20,joint_limit 29,time_limit 11 - held-out:
success 32,joint_limit 31,time_limit 12
- primary:
- position + velocity
- primary:
success 14,joint_limit 44,time_limit 2 - held-out:
success 14,joint_limit 61
- primary:
- position + velocity + action
- primary:
success 18,joint_limit 37,time_limit 5 - held-out:
success 23,joint_limit 45,time_limit 7
- primary:
여기서 눈에 띈 건 position + velocity가 성공이 가장 적으면서도 joint limit 종료는 가장 많았다는 점이다. 원래는 속도 항을 넣으면 좀 더 안정적으로 움직일 수도 있겠다고 생각했는데, 이번 설정에서는 오히려 충분히 목표에 들어가기 전에 자세가 말려서 joint limit에 걸리는 경우가 더 많아진 것처럼 보였다.
반대로 position only는 time limit도 꽤 있었지만, 성공 수 자체는 가장 많았다. position + velocity + action은 success와 failure reason이 둘 사이의 중간쯤에 있었다.
reward 비교에 대한 결론
이번 결과만 놓고 보면, 현재 설정에서는 reward를 단순하게 만든 position only가 가장 높은 success와 가장 좋은 held-out final distance를 보였다. 즉 적어도 이번 2-link reaching 문제에서는 “reward를 더 많이 다듬을수록 무조건 더 잘 된다”는 결과는 나오지 않았다.
다만 제어 effort까지 같이 보면 얘기가 조금 달라진다. position only는 가장 잘 가는 대신 토크를 가장 많이 썼고, heatmap도 더 끊겨있었다. 반대로 position + velocity + action은 success 자체는 조금 낮지만, effort는 줄고 held-out heatmap은 조금 더 고르게 퍼지는 모습이 있었다.
그래서 내 느낌으로는 이번 reward 비교는 이렇게 정리하는 게 맞다.
- pure success만 보면
position only가 가장 강했다 - effort와 분포의 균형까지 보면
position + velocity + action이 더 절충적인 선택처럼 보였다 position + velocity만 넣은 버전은 이번 설정에서는 장점이 가장 약했다
최종 결론
이번 확장 포스팅의 목표는 이전 포스팅에서 만들었던 2-link leg RL 문제를 그대로 유지하면서, 실험 구조를 더 엄밀하게 바꿔 보는 것이었다. 처음에 내가 세운 큰 목표는 네 가지였다.
- 기존 문제를 유지한 채 연구처럼 비교 가능한 구조를 만들기
- action 방식을 비교해 보기
- target 조건을 비교해 보기
- seed를 여러 개 돌리고 결과를 aggregate로 정리해서 한 번 잘 나온 결과와 반복해서 비슷하게 나오는 결과를 구분해 보기
지금 돌아보면, 이 목표들은 거의 다 이룬 상태라고 느낀다. 이번 확장 실험에서는 이전 포스팅 내용을 건드리지 않고 별도 패키지로 구조를 다시 잡았고, env / baselines / train / utils / results를 분리했다. 그리고 seed 7, 11, 21을 기준으로 같은 실험을 반복해서 돌리고, run별 결과와 aggregate 결과를 따로 저장하도록 정리했다. 적어도 “한 번 PPO를 돌려봤다” 수준이 아니라, 같은 문제를 다른 조건에서 비교해 볼 수 있는 작은 실험 플랫폼은 만든 셈이다.
실험 결과를 기준으로 보면 action 비교에서는 목표 각도 변화량 방식이 직접 토크 방식보다 훨씬 안정적으로 학습됐다. 직접 토크 방식은 이번 설정에서 거의 성공을 만들지 못했고, velocity limit으로 자주 끝났다. 그래서 내가 처음 목표 각도 변화량 방식을 더 안전한 선택이라고 생각했던 이유가 결과로도 어느 정도 확인됐다.
target 비교에서는 처음 예상과 조금 다른 결과가 나왔다. 여러 목표를 랜덤하게 보면서 학습한 randomized_train이 held-out에서도 더 좋을 수도 있다고 생각했는데, 실제로는 fixed_single이 자기 문제에서는 물론 held-out에서도 더 높은 success rate와 더 낮은 final distance를 보였다. 이 결과를 보고, “randomized target이면 무조건 더 일반화된다”는 기대는 지금 설정에서는 성립하지 않는다는 점을 배웠다. 동시에 fixed_single의 일반화도 완전히 자유로운 것이 아니라, 학습한 한 점과 위치상 비슷한 held-out 목표들에 더 잘 퍼지는 형태라는 점도 heatmap으로 확인할 수 있었다.
reward 비교에서는 reward를 더 복잡하게 만든다고 무조건 더 좋은 결과가 나오는 것은 아니라는 점이 보였다. 순수 success와 held-out final distance만 보면 position only가 가장 강했다. 하지만 제어 effort와 heatmap의 모양까지 같이 보면 position + velocity + action이 더 절충적인 선택처럼 보였다. 즉 이번 실험에서는 “무조건 정답 reward”를 찾았다기보다, reward를 어떻게 설계하느냐에 따라 정책이 어떤 성격을 갖게 되는지가 실제로 달라진다는 점을 확인한 것이 더 중요했다.
그래서 이번 확장 실험을 한 정리하면, 2-link swing-foot reaching 문제에서 PPO 자체가 되는지 확인하는 단계를 넘어서, action / target / reward를 바꾸면 정책의 성능과 성격이 어떻게 달라지는지 비교해 본 과정이었다고 말할 수 있다. 적어도 지금까지는 계획했던 핵심 비교 축인 action, target, reward 세 가지를 모두 돌려 봤고, seed 반복과 held-out 평가까지 포함해서 결과를 정리했다는 점에서 이번 확장 목표는 대부분 달성했다고 생각한다.
다만 아직 남은 한계도 분명하다. success 정의는 여전히 “5cm 안에 한 번 들어오면 끝”이라서 안정적으로 멈췄는지는 보지 못한다. held-out도 평가용 고정 target 25개를 따로 둔 것은 맞지만, 학습 중 비슷한 위치가 우연히 나올 가능성까지 완전히 제거한 것은 아니다. 또 robustness 실험이나 노이즈, 모델 오차 같은 조건은 아직 보지 않았다. 그래서 이번 결과를 바로 “이 방식이 항상 정답이다”라고 일반화할 수는 없고, 현재 설정 안에서 어떤 선택이 더 잘 맞았는지 확인한 1차 비교 실험으로 이해하는 것이 맞아 보인다.
그럼에도 불구하고 이번 확장판은 나한테 꽤 의미 있었다. 이전 포스팅이 “강화학습을 한 번 내 문제에 붙여보는 단계”였다면, 이번 확장 포스팅은 “같은 RL 문제를 어떤 기준으로 비교하고 해석해야 하는지 배우는 단계”였다고 느꼈다. 그래서 이번 실험은 단순히 결과 숫자를 더 많이 만든 것이 아니라, RL 프로젝트를 연구처럼 보이게 만드는 요소가 무엇인지 직접 체험해 본 기록이라고 정리하고 싶다.
]]>