[기초] 2-Link Leg를 RL 문제로 바꾸기
코드베이스는 여기에 정리해 두었다.
목표
이번 주의 목표는 내가 만든 2-link 다리 동역학 문제를 RL 문제로 바꾸는 것이다.
즉, 기존의 기구학/동역학/PD 제어 코드를 그대로 두고, 그 바깥을 Gymnasium 환경 형태로 감싸서 PPO가 학습할 수 있는 입력과 출력 구조를 만드는 것이 핵심이다.
MDP 정의
강화학습을 공부하다 보면 가장 먼저 나오는 말 중 하나가 MDP였다. MDP는 강화학습 문제를 정리하는 가장 기본적인 틀이었다. 에이전트가 현재 상태를 보고 행동을 고르면, 환경이 다음 상태와 보상을 돌려주는 흐름을 MDP라는 형태로 표현하는 것이었다.
내가 이해한 기준으로 보면 MDP는 결국 다섯 가지로 정리된다. 현재 환경이 어떤 상태인지 나타내는 state, 에이전트가 선택하는 action, 그 행동 이후 상태가 어떻게 바뀌는지를 나타내는 transition, 그 행동이 얼마나 좋았는지를 알려주는 reward, 그리고 episode가 언제 끝나는지를 정하는 termination 조건이다. 그래서 이번 주에는 내 2-link 다리 문제를 이 틀에 맞춰 다시 적어보는 것부터 시작했다.
State / Observation / Action / Transition / Reward / Termination / Return
- state: 내부 물리 상태는
q, qdot와 목표 발 위치target_pos로 본다. - observation: 정책에는
[q1/pi, q2/pi, qdot1/qdot_max, qdot2/qdot_max, (x_foot-x_target)/reach, (y_foot-y_target)/reach]만 준다. - action: 정책은 각 관절의 목표 각도 변화량을
[-1, 1]^2범위로 출력하고, env 내부에서q_des = clip(q + delta_q_max * action, q_limits)로 바꾼다. - transition: action을 받아 PD + gravity compensation으로 torque를 만들고, Week 4의
step_dynamics로 다음q, qdot를 계산한다. - reward:
-2.0 * dist^2 - 0.05 * ||qdot||^2 - 0.01 * ||action||^2, 성공 반경 안에 들어오면+5.0. - termination: success, joint limit 위반, NaN, 속도 blow-up이면 episode를 종료하고, 시간 제한은
truncated로 따로 처리한다. - return: 현재 시점부터 episode 종료까지의 할인 reward 합이다.
왜 state를 q, qdot, target_pos로 잡았나?
state는 이 환경이 다음 순간으로 넘어가는 데 필요한 최소 핵심 정보를 담고 있어야 한다.
여기서 q는 현재 다리 자세, qdot는 현재 운동 상태, target_pos는 이번 episode에서 발이 가야하는 목표점 좌표이다.
이 문제는 발을 목표점으로 보내는 문제이기 때문에, 목표 위치 정보가 꼭 필요했다.
목표가 없으면 로봇이 어디로 가야 하는지 정할 수 없어서 q와 qdot만으로는 이 문제를 설명하기 어려웠다.
결국 이 세 가지가 있어야 다음 상태를 계산할 수 있고, 발끝-목표 오차 기반 reward도 정의할 수 있다.
그래서 이번 환경에서는 q, qdot, target_pos를 이 문제를 설명하는 최소한의 state로 봤다.
왜 observation은 state를 그대로 쓰지 않았나?
observation은 정책이 실제로 보는 입력이다.
정책이 꼭 state 전체를 원시 형태로 받아야 하는 것은 아니기 때문에, 이번에는 학습하기 좋은 형태로 가공해서 넣었다.
현재 자세와 움직임은 q, qdot로 표현하고, 목표 정보는 절대 좌표 대신 발끝과 목표 사이의 상대 오차로 바꿨다.
나는 이 값이 “지금 발이 목표에서 얼마나 떨어져 있는지”를 더 바로 보여준다고 느꼈고, 목표 좌표를 그대로 넣는 것보다 이해하기 쉬웠다.
또 각 항을 기준값으로 나눠 정규화했다.
각도, 속도, 위치 오차는 크기와 단위가 서로 달라서 그대로 넣으면 어떤 값은 너무 크고 어떤 값은 너무 작게 들어간다. 이렇게 되면 신경망이 입력 값들을 균형있게 보기 어렵고 숫자가 큰 입력이 더 강하게 작용하게 되어 학습이 잘 안 될 수 있다. 그래서 각 항을 기준값으로 나눠서 비슷한 크기로 맞췄다.
그래서 observation은 state를 단순 복사한 값이 아니라, 정책이 학습하기 쉽도록 정리한 입력 표현이라고 할 수 있다.
왜 action을 토크가 아니라 목표 각도 변화량으로 만들었나?
이번 action은 정책이 직접 토크를 내는 구조가 아니다.
대신 정책은 [-1, 1] 범위의 명령을 내고, 그 명령은 “현재 관절 목표를 어느 방향으로 얼마나 움직일지의 정도”를 뜻한다.
먼저 env 안에서
q_des = q + delta_q_max * action
으로 목표 관절각을 만든다.
그다음 저수준 PD + gravity compensation 제어기(4주차에 만든)가 실제 토크를 계산한다.
이렇게 한 이유는 직접적인 토크값보다 훨씬 안정적이기 때문이다.
처음부터 정책이 곧바로 토크를 다루게 하면, 물리 모델 문제와 학습 불안정성이 생길 수 있다.
직접 토크가 더 어려운 이유는, policy가 낸 값이 거의 바로 물리계에 들어가기 때문이다.
학습 초반에는 policy가 이상한 값을 자주 내는데, 그 값이 바로 토크가 되면 움직임이 너무 거칠어지거나 속도가 갑자기 커질 수 있다.
반면 지금 방식은 먼저 목표 각도를 만들고, 그다음 PD 제어기가 토크를 계산한다.
중간에 한 번 정리되는 단계가 들어가기 때문에 상대적으로 다루기 쉽다.
이번 구조에서는 정책이 고수준 목표(어디로 얼마나 갈지)만 정하고, 실제 토크 생성은 이미 수학적인 PD 제어기가 맡는다.
즉 이번에는 RL이 방향만 정하고, 실제 토크는 기존 제어기가 만들도록 역할을 나눴다.
[-1, 1] action이 실제 토크가 되는 과정
예를 들어 policy가
action = [0.6, -0.4]
를 냈다고 하면
이 값은 아직 토크가 아니라, “첫 번째 관절은 조금 더 앞으로, 두 번째 관절은 조금 덜 움직여라” 같은 정규화된 명령이다.
먼저 현재 자세 q와 delta_q_max를 이용해 목표 자세를 만든다.
q_des = q + delta_q_max * action
예를 들어 현재 q = [0.20, -0.50], delta_q_max = 0.35라면
q_des = [0.41, -0.64]
가 된다.
그다음 PD 제어기가
tau = Kp(q_des - q) - Kd qdot
형태로 토크를 만든다.
실제 코드에서는 여기에 현재 자세에서 필요한 중력 보상도 더해 주고, 마지막에 너무 큰 값은 제한값 안으로 잘라서 동역학 식에 넣는다.
결국 policy는 직접 토크를 계산하는 것이 아니라, 목표 자세를 조금씩 제안하고 실제 torque 생성은 PD 제어기가 맡는 구조이다.
왜 내 동역학 코드는 RL에서 environment transition이 되는가?
RL에서 environment는 action을 받으면 다음 상태를 만들어야 한다.
이번 문제에서는 그 역할을 하는 것이 바로 Week 4에서 만든 forward dynamics와 적분기다.
현재 q, qdot와 policy가 낸 action이 있으면, env 내부에서 먼저 torque를 만든다.
그리고 그 torque를 가지고 step_dynamics를 호출하면 다음 q, qdot가 나온다.
즉 내가 전에 만들었던 동역학 코드가, RL에서는 다음 상태를 만들어 주는 부분으로 그대로 들어왔다고 볼 수 있다.
왜 reward는 “내가 진짜 원하는 것”과 정확히 같지 않은가?
내가 정말 원하는 것은 “발을 목표점으로 안정적으로 잘 보내는 것”이다.
하지만 이것을 한 줄짜리 수식 하나로 정확히 쓰기는 어렵다.
그래서 reward는 보통 그 목표를 대신 표현하는 몇 가지 측정 가능한 항으로 나눈다.
이번에는
- 목표와의 거리
- 너무 큰 속도
- 너무 큰 action
세 가지를 사용했다.
그래서 reward는 “내가 진짜 원하는 행동” 그 자체라기보다, 그쪽으로 가도록 도와주는 점수라고 이해했다.
계수들도 어떤 정답이 있어서 정한 값은 아니다.
이번에는 목표에 가까워지는 것을 가장 중요하게 두고 싶어서 거리 항의 비중을 가장 크게 뒀고, 속도와 action 크기는 움직임이 너무 거칠어지지 않게 하는 보조 항이라는 생각으로 더 작게 넣었다.
termination은 왜 따로 정해야 하나?
termination은 episode가 언제 끝나는지 정하는 규칙이다.
이걸 따로 정하지 않으면 agent는 언제 성공한 것인지, 언제 실패한 것인지, 언제 그냥 시간이 끝난 것인지 구분할 수 없다.
이번 환경에서는 목표 반경 안에 들어오면 success로 종료하고, joint limit을 넘거나 NaN이 나오거나 속도가 지나치게 커지면 failure로 종료한다.
반면 step 수가 다 차서 끝나는 경우는 성공이나 실패라기보다 단순한 시간 종료이기 때문에 truncated로 따로 처리했다.
Baseline 계획
PPO를 바로 돌리기 전에 baseline을 먼저 만든 이유는, 학습이 안 될 때 무엇이 문제인지 분리하기 위해서다.
baseline을 먼저 잡는 것이 표준적인 방법인 것 같다.
- random policy: action space에서 무작위 샘플
- zero policy: 항상 0 action
- IK policy: Week 3 numerical IK로
q*를 찾고,(q* - q) / delta_q_max를 action으로 변환
핵심 체크는 IK > zero/random 순서로 결과나 나오는지다.
이 순서가 안 나오면 PPO를 의심하기 전에 env, reward, termination 등 환경 세팅을 의심해야 한다.
그래서 baseline은 단순 비교용이라기보다, 지금 환경이 제대로 만들어졌는지 확인하는 기준처럼 느껴졌다.
PPO(Proximal Policy Optimization) 계획
이번 주의 첫 알고리즘으로 PPO를 선택했다.
PPO가 연속적인 action 문제에 자주 쓰이고, 처음 실험해 보기에도 비교적 단순한 편이기 때문이다.
policy를 너무 급하게 바꾸지 않고 조금씩만 업데이트해 가면서 reward가 더 좋아지는 방향으로 policy 자체를 직접 학습시키는 알고리즘이라고 이해했다.
observation을 넣으면 action을 내고, 그걸 반복하면서 점점 나아지게 만드는 흐름으로 이해할 수 있어서 첫 알고리즘으로 보기 부담이 덜했다.
이번 실험에서는 두 단계를 나눴다.
- built-in sanity check:
Pendulum-v1 - custom env 학습:
TwoLinkSwingEnv
Pendulum-v1를 넣은 이유는 내 커스텀 env 전에 RL 스택 자체가 도는지 확인하기 위해서다.
즉 Pendulum에서는 되는데 내 env만 안 되면, 문제를 PPO가 아니라 내 환경 설계 쪽으로 좁혀 볼 수 있다.
실제 custom env 학습은 PPO("MlpPolicy", ...)를 사용했고, EvalCallback으로 best model을 따로 저장했다.
평가는 같은 조건으로 20번 돌려서 평균 reward, success rate, final distance를 비교했다.
실행 결과
Baseline
week6/projects/runs/baselines/baseline_summary.json 기준:
| Baseline | Mean reward | Success rate | Mean final distance |
|---|---|---|---|
| random | -176.79 |
5% |
0.554 |
| zero | -160.79 |
0% |
0.659 |
| IK | -14.41 |
90% |
0.106 |
이 숫자는 실행할 때마다 조금 달라질 수 있다.
그래도 공통적으로는 IK baseline이 random이나 zero보다 훨씬 좋은 결과를 보였다.
이 결과에서 가장 먼저 눈에 들어온 것은 IK baseline이 확실히 좋았다는 점이다.
적어도 내가 만든 환경에서, 손으로 만든 기준 정책은 목표를 꽤 잘 따라간다는 것은 확인할 수 있었다.
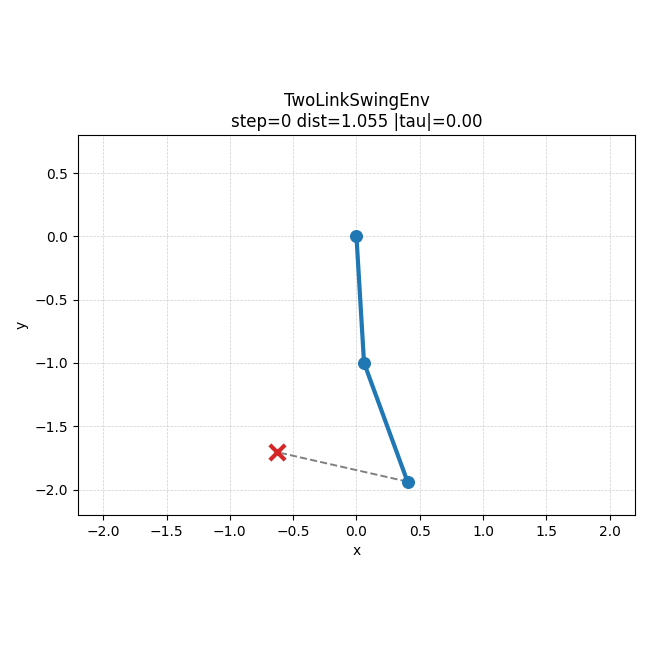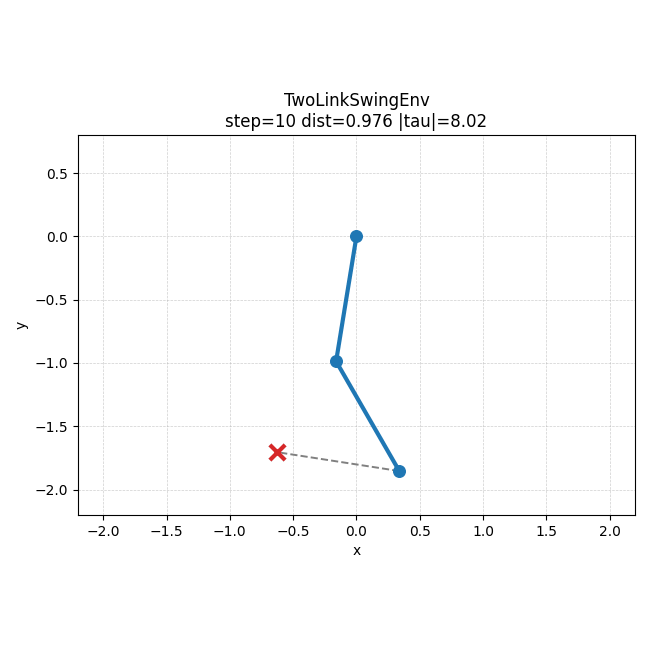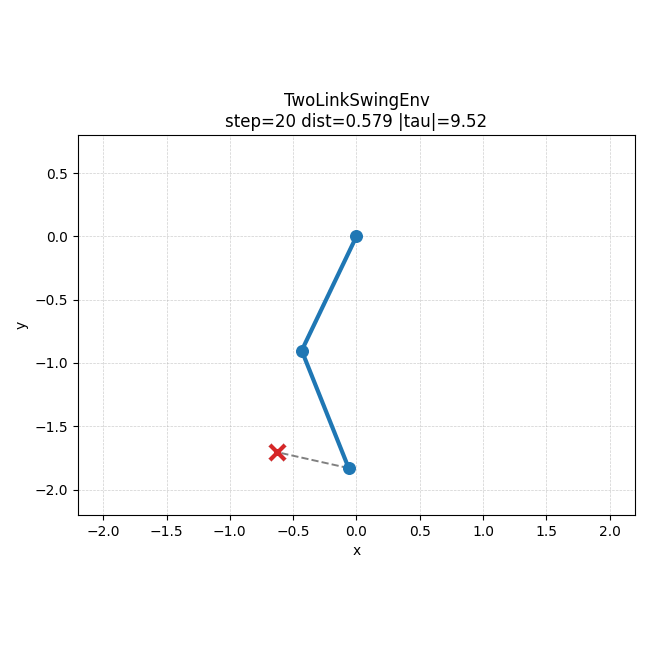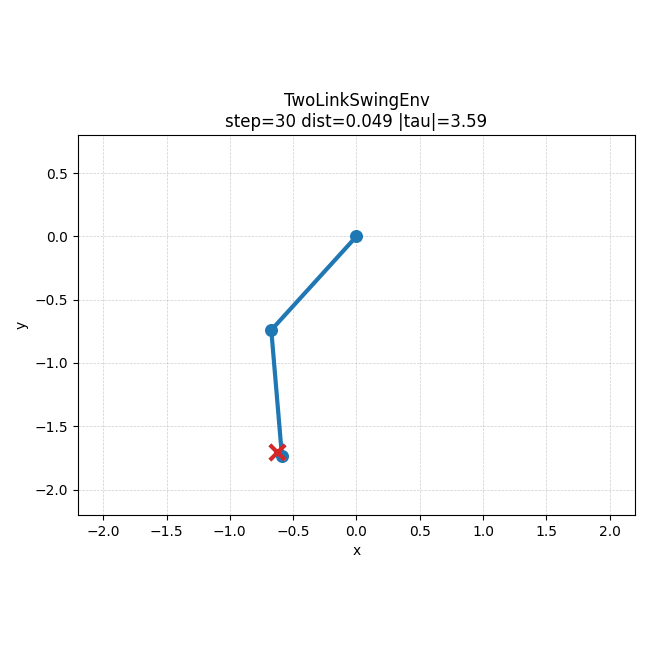
IK baseline rollout을 보면, 이 문제에서는 손으로 만든 기준 정책도 꽤 안정적으로 목표 쪽으로 수렴하는 편이라는 것을 직관적으로 볼 수 있었다.
베이스라인은 PPO 결과를 해석할 때 중요하다.
만약 IK도 안 됐다면, PPO가 못 배우는 이유를 policy 탓으로 볼 수 없기 때문이다.
2링크 구조는 수학적으로 깔끔하게 답이 나오는 상황이기 때문에 PPO 보다 IK 베이스라인이 더 좋은 결과를 낼 것으로 예상했다.
PPO sanity check
week6/projects/runs/pendulum_ppo/summary.json 기준, 짧은 3,000-step 학습에서:
- random mean reward:
-1260.00 - trained mean reward:
-1253.60
큰 차이는 아니지만, PPO 코드가 아예 안 돌아가는 상태는 아니라는 것은 확인할 수 있었다.
즉 설치나 기본 학습 파이프라인 자체가 완전히 깨진 것은 아니었다.
학습 step 수에 따른 경향
이번에는 짧은 12,000-step 결과보다, 실제로 폴더로 남겨 둔 학습 run들을 step 수별로 비교해 보는 쪽이 더 낫다고 느꼈다.
기준은 각 run 폴더 안의 summary.json이고, 여기서 trained의 mean reward, success rate, mean final distance를 비교했다.
아래 표의 숫자들은 학습 중에 바로 본 값이 아니라, 따로 만든 평가 환경(eval env)에서 다시 돌려 본 결과다.
한 episode는 최대 150 step이고, 10 episode를 측정했다.
목표 반경 5cm 안에 들어오면 성공으로 처리했다.
mean final distance는 episode가 끝났을 때 발끝이 목표와 얼마나 떨어져 있었는지를 평균낸 값이다.
| Step | Trained mean reward | Trained success rate | Trained mean final distance |
|---|---|---|---|
50000 |
-34.91 |
30% |
0.415 |
300000 |
-26.53 |
20% |
0.267 |
500000 |
-25.06 |
20% |
0.219 |
5000000 |
-17.58 |
50% |
0.142 |
random policy 쪽 숫자는 매번 조금씩 달랐지만, trained policy 쪽은 step 수를 늘릴수록 전반적으로 좋아지는 경향이 보였다.
특히 mean final distance는 0.415 -> 0.267 -> 0.219 -> 0.142로 계속 줄어들었다.
success rate는 중간에 30% -> 20% -> 20%처럼 깔끔하게 오르지는 않았다.
그래서 RL에서는 step 수를 늘린다고 항상 모든 지표가 예쁘게 같이 오르는 것은 아니라는 것도 같이 보였다.
그래도 가장 긴 5000000 step에서는 success rate가 50%까지 올라갔고, final distance도 가장 작았다.
지금까지 해 본 run들 중에서는 이 결과가 제일 좋았다.
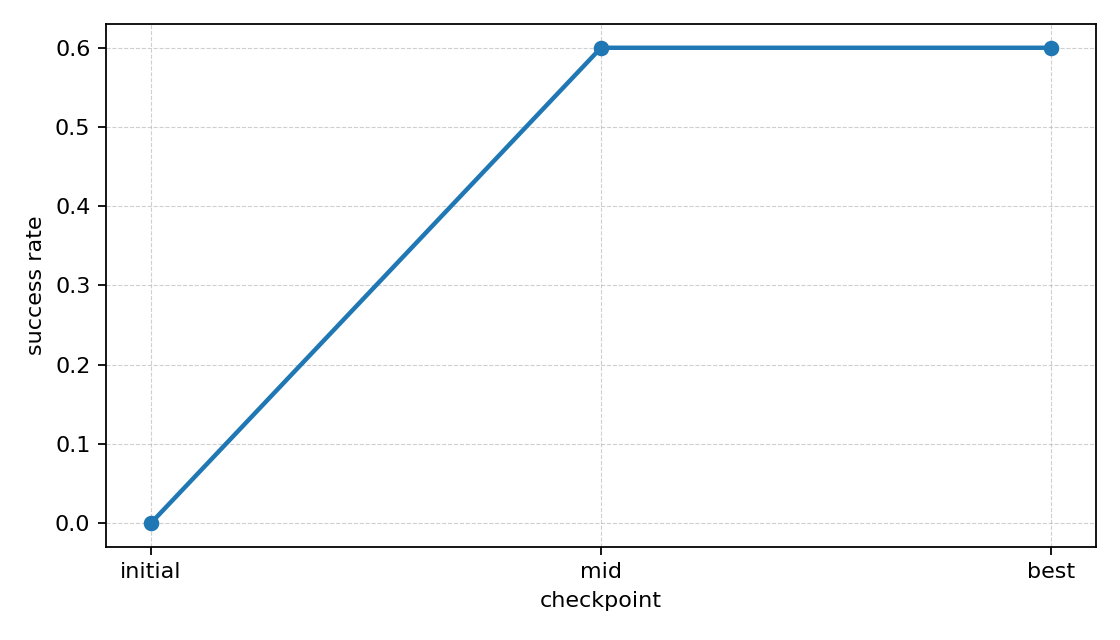
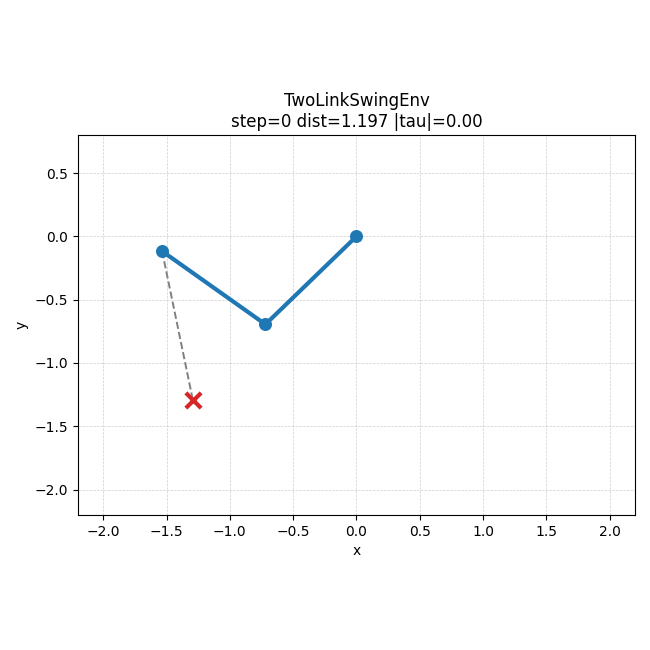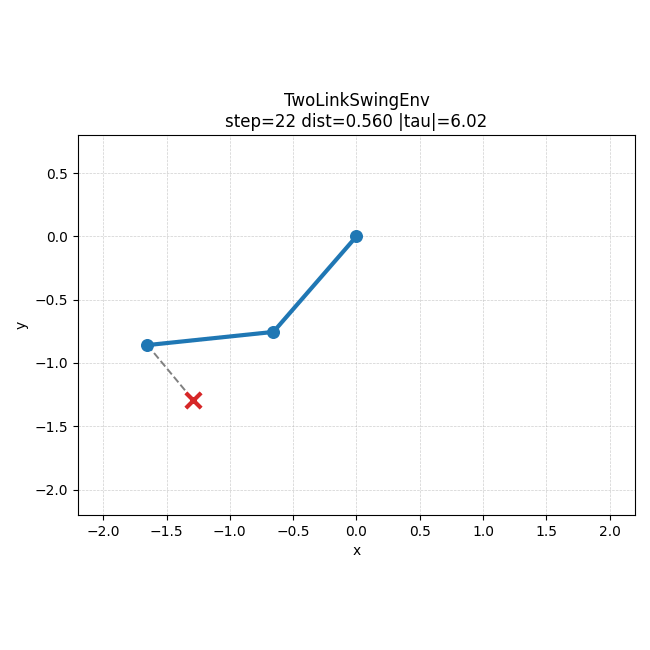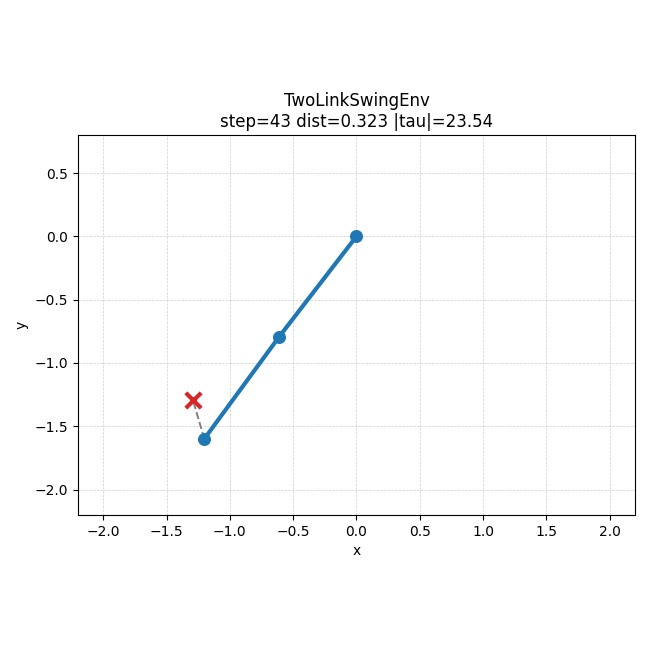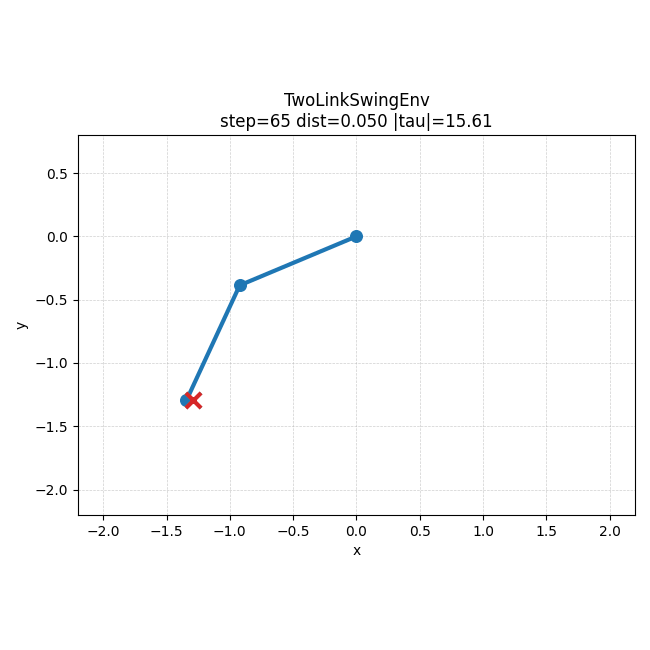
왼쪽은 5000000 step run에서 checkpoint별 success rate가 어떻게 바뀌는지 보여주는 그래프이고, 오른쪽은 같은 run에서 가장 잘 된 rollout 예시다. 숫자로만 볼 때보다, 학습이 진행되면서 실제 움직임도 어느 정도 목표 쪽으로 정리된다는 점을 더 직관적으로 볼 수 있었다.
각 run 안에서의 checkpoint 변화
evaluation_summary.json 기준으로 보면, 각 run 안에서도 initial -> mid -> best가 어떻게 바뀌는지 볼 수 있었다.
| Step | Initial reward / success / dist | Mid reward / success / dist | Best reward / success / dist |
|---|---|---|---|
50000 |
-226.46 / 0% / 0.801 |
-57.25 / 10% / 0.383 |
-256.70 / 30% / 0.634 |
300000 |
-226.46 / 0% / 0.801 |
-51.01 / 25% / 0.464 |
-77.41 / 15% / 0.527 |
500000 |
-226.46 / 0% / 0.801 |
-48.63 / 15% / 0.487 |
-72.57 / 15% / 0.503 |
5000000 |
-226.46 / 0% / 0.801 |
-18.44 / 60% / 0.205 |
-19.32 / 60% / 0.244 |
여기서 느낀 점은 best라는 이름이 붙어 있어도, 나중에 다시 평가했을 때 항상 가장 좋은 숫자가 나오지는 않는다는 점이었다.
학습 중에는 그 시점 eval 기준으로 제일 좋았던 모델이었지만, 나중에 다시 다른 episode들로 평가하면 mid가 더 좋아 보이는 경우도 있었다.
그래서 이번에는 “무조건 마지막이 최고”라기보다, step 수를 늘리면 좋아질 가능성은 있지만 중간 checkpoint도 꼭 같이 봐야 한다고 느꼈다.
이번에 공부하면서 느낀 점
이번 주에는 “PPO를 돌려봤다”보다, 강화학습 실험 결과를 어떻게 읽어야 하는지를 조금 배운 느낌이 더 컸다.
지금 단계에서 내가 정리한 아쉬운 점과 배운 점은 아래 다섯 가지다.
-
IK baseline은 여전히 강한 기준선이었다.
PPO가 분명히 학습되기는 했지만, 지금 2-link 목표점 문제에서는 내가 이미 알고 있는 IK 방식이 훨씬 안정적이었다. 그래서 RL이 항상 기존 방법보다 바로 좋은 것은 아니라는 점을 알게 됐다. -
평가에는 생각보다 운 요소가 남아 있었다.
best모델이라고 해도 다시 평가했을 때mid보다 항상 더 잘 나오지는 않았다. 같은 코드라도 episode 샘플이 달라지면 숫자가 조금 바뀔 수 있어서, 결과를 너무 한 번에 단정하면 안 되겠다고 느꼈다. -
지금 성공 기준은 꽤 단순하다.
현재는 목표 반경 5cm 안에 한 번 들어오면 성공으로 끝난다. 그래서 목표에 닿은 뒤 안정적으로 멈췄는지, 아니면 지나치며 흔들렸는지는 아직 보지 못하고 있다. -
step 수를 늘린다고 항상 마지막 모델이 최고는 아니었다.
학습을 오래 돌리면 전반적으로는 좋아졌지만, 가장 좋은 성능은 중간 checkpoint에서 나오는 경우도 있었다. 그래서 마지막 모델만 보는 것보다initial,mid,best를 같이 보는 게 필요하다는 걸 알게 됐다. -
아직은 정말 엄밀한 테스트까지 한 것은 아니다.
train env와 eval env는 분리했지만, 목표 좌표는 학습 때와 같은 샘플링 규칙에서 다시 뽑아 쓴 구조였다. 즉 학습 때 일부러 빼 둔 held-out target 집합은 아직 없었고, 완전히 새로운 목표 집합이나 노이즈, 모델 오차 같은 테스트도 하지 않았다. 그래서 지금 결과는 “학습 파이프라인이 돌아가고, 실제로 좋아지기도 한다” 정도까지는 말할 수 있지만, 일반화나 강건성까지 분석하기에는 아직 멀었다고 느꼈다.