이론 모델 LQR vs 시뮬레이션 모델 LQR
동기
제어 이론을 배우며 궁금했던 점은 ‘이론으로 푼 수식이 실제 로봇도 잘 제어할 수 있을까?’ 였다. 보통 예제에서는 마찰을 무시하거나 이상적인 조건을 가정하지만, 실제 로봇이나 시뮬레이터는 물리적 제약이 있다.
LQR을 시뮬레이션에 적용할 기회가 생긴 김에, 단순히 제어가 잘 된다에서 멈추지 않고 교과서적인 이론 모델로 설계한 제어기와 시뮬레이션 환경을 역으로 분석해서 만든 데이터 기반 모델을 붙여 보았을 때 이론은 시뮬레이션의 복잡함을 어디까지 버텨낼 수 있을지 알아보고자 했다.
이를 위해 Mujoco의 표준 도립진자 환경에서 동일 조건으로 구현/비교하고, 결과를 재현 가능한 코드와 로그로 남긴다.
실험 세팅
아래 카트-폴 모델을 사용하여 운동 방정식을 통해 수식을 작성하였다.
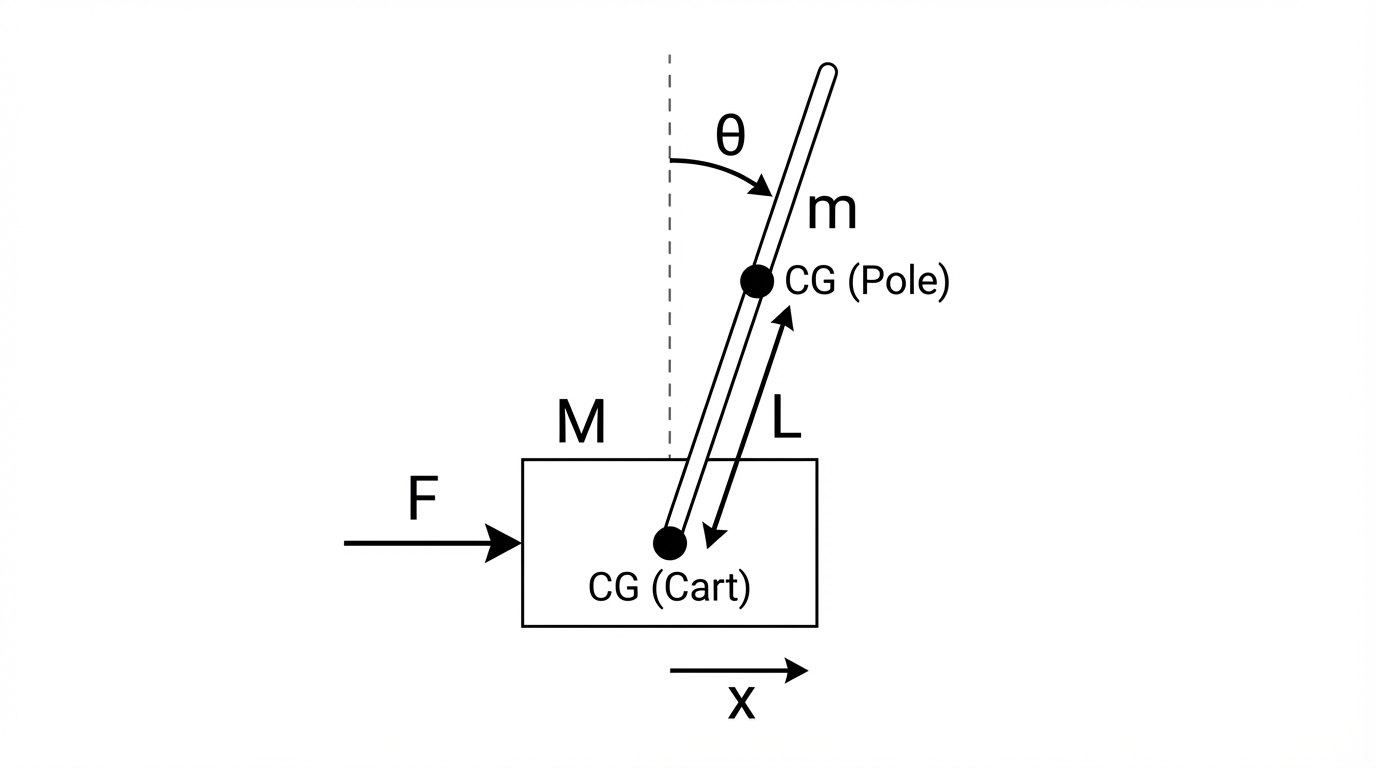
$x : \text{카트 위치},\ \theta : \text{막대 각도(직립이 } \theta=0\text{)},\ u : \text{환경 action}$
$M : \text{카트 질량}$
$m : \text{막대 질량}$
$l : \text{힌지}\rightarrow\text{막대 COM 거리}$
$I : \text{막대 COM 기준 관성(힌지 축 기준)}$
$g : \text{중력가속도} $
$F : \text{카트에 작용하는 수평 힘(외력)} $
$F’ = \mathrm{gear}\,u \ \text{(제어 힘)}$
관성 포함 비선형 운동방정식
$(M+m)\ddot{x} + m l\left(\ddot{\theta}\cos\theta - \dot{\theta}^{2}\sin\theta\right) = F$
$(I+m l^{2})\ddot{\theta} + m l\ddot{x}\cos\theta - m g l\sin\theta = 0$
$A = M+m$
$B = m l\cos\theta$
$C = I+m l^{2}$
라고 하면,
$\Delta(\theta) = AC - B^{2} = (M+m)(I+m l^{2}) - (m l\cos\theta)^{2}$
$\ddot{x} = \dfrac{C\left(F + m l\dot{\theta}^{2}\sin\theta\right) - B\left(m g l\sin\theta\right)}{\Delta(\theta)}$
$\ddot{\theta} = \dfrac{-B\left(F + m l\dot{\theta}^{2}\sin\theta\right) + A\left(m g l\sin\theta\right)}{\Delta(\theta)}$
직립 근방에서 선형화
$\sin\theta \approx \theta,\quad \cos\theta \approx 1,\quad \dot{\theta}^{2}\sin\theta \approx 0$
$D = \Delta(0) = (M+m)(I+m l^{2}) - (m l)^{2} = (M+m)I + M m l^{2}$
$\ddot{x} = -\dfrac{m^{2} g l^{2}}{D}\theta + \dfrac{I+m l^{2}}{D}F$
$\ddot{\theta} = \dfrac{(M+m)m g l}{D}\theta - \dfrac{m l}{D}F$
상태 정의 및 선형 상태공간 (A, B)
MuJoCo InvertedPendulum-v5의 관측 순서가
\[\mathrm{obs} = [\,x,\ \theta,\ \dot{x},\ \dot{\theta}\,]\]이므로, 상태를 아래처럼 정의한다.
\[\mathbf{x} = \begin{bmatrix} x \\ \theta \\ \dot{x} \\ \dot{\theta} \end{bmatrix}\]입력은 먼저 카트에 작용하는 수평 힘 $F$로 두면,
\[\dot{\mathbf{x}} = A_c\,\mathbf{x} + B_c\,F\]이고, 위에서 얻은 선형화 식
\[D = (M+m)I + M m l^{2}\] \[\ddot{x} = -\dfrac{m^{2} g l^{2}}{D}\,\theta + \dfrac{I+m l^{2}}{D}\,F\] \[\ddot{\theta} = \dfrac{(M+m)m g l}{D}\,\theta - \dfrac{m l}{D}\,F\]을 이용해 분모를 다음처럼 두고 정리한다.
\[A_c = \begin{bmatrix} 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & -\dfrac{m^{2} g l^{2}}{D} & 0 & 0 \\ 0 & \dfrac{(M+m)m g l}{D} & 0 & 0 \end{bmatrix},\qquad B_c = \begin{bmatrix} 0 \\ 0 \\ \dfrac{I+m l^{2}}{D} \\ -\dfrac{m l}{D} \end{bmatrix}\]이다.
마지막으로 MuJoCo 환경에서의 action $u$를 직접 입력으로 쓰고 싶다면,
\[F = \mathrm{gear}\,u\]이므로
\[\dot{\mathbf{x}} = A_c\,\mathbf{x} + B_u\,u,\quad B_u = B_c\,\mathrm{gear}\]로 바꿔 쓸 수 있다.
지금까지 구한 $A_c, B_c$는 연속 시간을 가정하고 구한 이론 행렬이다. 하지만 시뮬레이션에서는 이산 시간으로 step마다 물리 엔진 계산이 돌아가므로, 추가로 이산화하는 과정이 필요하다.
시뮬레이션 환경을 확인해본 결과, 샘플링 시간이 0.04초인 것을 확인하였다.
$dt=0.04$에 맞게 이산화하면, (입력은 각 step 동안 일정하다고 가정하는 ZOH: Zero-Order Hold)
\[\mathbf{x}_{k+1} = A_d\,\mathbf{x}_k + B_d\,u_k\]형태의 이산시간 선형 모델을 얻는다.
ZOH 이산화
연속시간 모델이
\[\dot{\mathbf{x}} = A_c\,\mathbf{x} + B_u\,u\qquad (B_u = B_c\,\mathrm{gear})\]일 때, ZOH 이산화는 아래의 블록 행렬 지수로 정확하게 계산할 수 있다.
\[\exp\!\left( \begin{bmatrix} A_c & B_u \\ 0 & 0 \end{bmatrix} dt\right) = \begin{bmatrix} A_d & B_d \\ 0 & 1 \end{bmatrix}\]즉,
\[A_d = \left[\exp\!\left( \begin{bmatrix} A_c & B_u \\ 0 & 0 \end{bmatrix} dt\right)\right]_{1:4,\,1:4},\qquad B_d = \left[\exp\!\left( \begin{bmatrix} A_c & B_u \\ 0 & 0 \end{bmatrix} dt\right)\right]_{1:4,\,5}\]로 얻어진다.
입력을 힘 $F$로 두고 싶다면 $\dot{\mathbf{x}} = A_c\mathbf{x} + B_c F$ 에 대해 같은 방식으로
\[\exp\!\left( \begin{bmatrix} A_c & B_c \\ 0 & 0 \end{bmatrix} dt\right) = \begin{bmatrix} A_d & B_d^{(F)} \\ 0 & 1 \end{bmatrix}\]를 계산해 $B_d^{(F)}$를 얻고, $F=\mathrm{gear}\,u$ 관계로 $B_d = B_d^{(F)}\,\mathrm{gear}$로 변환해도 동일하다.
여기까지가 연속 모델 → 이론(이산) 모델을 만드는 과정이다. 이제 다음 단계에서는 (1) 이산화된 이론 행렬 $(A_d^{th}, B_d^{th})$과 (2) 시뮬레이터에서 수치 선형화로 얻은 $(A_d^{fd}, B_d^{fd})$를 각각 사용해 이산 LQR을 설계하고 성능/실패를 비교한다.
시뮬레이션 수치 선형화
Mujoco에 들어가 있는 모델을 그대로 사용하여, 시뮬레이션 환경에 최적화 + 선형화된 $A_d^{fd}, B_d^{fd}$ 를 구했다.
시뮬레이션은 이산화 되어있기 때문에 추가로 이산화를 해줄 필요가 없다.
이산시간 시스템을
\[\mathbf{x}_{k+1} = f(\mathbf{x}_k, u_k)\]라고 보고, 직립 평형점 $(\mathbf{x}^*, u^*)$ 주변에서 유한차분(Finite Difference)으로 자코비안을 근사한다.
\[\begin{aligned} A_d^{fd} &\approx \left.\frac{\partial f}{\partial \mathbf{x}}\right|_{(\mathbf{x}^*,u^*)} \\ B_d^{fd} &\approx \left.\frac{\partial f}{\partial u}\right|_{(\mathbf{x}^*,u^*)} \end{aligned}\]즉, 상태의 각 성분을 아주 조금 $\varepsilon$ 만큼 흔들어 본 뒤, 그때의 다음 상태 변화량으로 기울기를 계산한다.
\[A_d^{fd}[:,i] \approx \frac{f(\mathbf{x}^* + \varepsilon \mathbf{e}_i, u^*) - f(\mathbf{x}^* - \varepsilon \mathbf{e}_i, u^*)}{2\varepsilon},\qquad B_d^{fd} \approx \frac{f(\mathbf{x}^*, u^*+\varepsilon) - f(\mathbf{x}^*, u^* - \varepsilon)}{2\varepsilon}\]아래는 실제 구현에서 핵심만 남긴 스니펫이다(관측 $\mathbf{x}=[x,\theta,\dot x,\dot\theta]$를 그대로 사용했다).
이렇게 얻은 $A_d^{fd}, B_d^{fd}$는 MuJoCo가 가진 실제 요소(마찰, 관성, 수치적분 오차 등)가 반영된 시뮬레이터 기준 선형 모델이다. 따라서 $A_d^{th},B_d^{th}$로 설계한 LQR과 $A_d^{fd},B_d^{fd}$로 설계한 LQR을 같은 조건에서 비교하면,
- 이론 모델 미스매치가 성능에 주는 영향
- 포화/외란 조건에서의 실패 모드 차이
를 정량적으로 분석해 볼 수 있다.
결과 - 이론 이산모델 vs 시뮬 수치 선형화 모델의 $A_d,B_d,K$ 차이
이론 모델 $A_d^{th}, B_d^{th}$과 시뮬레이터 수치 선형화 모델 $A_d^{fd}, B_d^{fd}$을 각각 만들고, 동일한 $Q,R$로 이산 LQR을 설계해 비교했다.
python -m experiments.run을 두 모드(theory / fd)로 각각 실행했고, 각 실행에서 영상 1개 + 로그 1개(json)가 저장되었다.- 동시에 터미널에 $A_d, B_d$와 그로부터 계산된 LQR 이득 $K$를 출력하도록 하여, 두 모델의 차이가 설계 결과에 얼마나 반영되는지 확인했다.
관측 상태는 동일하게 $\mathbf{x}=[x,\theta,\dot{x},\dot{\theta}]$를 사용하며, 아래는 터미널에서 확인한 값이다.
- 이론 모델 (theory)
- $A_d^{th}\approx$ \(\begin{bmatrix} 1.0000 & -0.0023 & 0.0400 & -0.0000 \\ 0.0000 & 1.0240 & 0.0000 & 0.0403 \\ 0.0000 & -0.1171 & 1.0000 & -0.0023 \\ 0.0000 & 1.2053 & 0.0000 & 1.0240 \end{bmatrix}\)
- $B_d^{th}\approx [\,0.006700\ -0.015800\ 0.335309\ -0.793131\,]^\top$
- $K^{th}\approx [\,-0.3554\ -7.1830\ -0.7326\ -1.6947\,]$
- 시뮬 수치 선형화 (FD)
- $A_d^{fd}\approx$ \(\begin{bmatrix} 1.0000 & -0.0023 & 0.0399 & 0.0001 \\ 0.0000 & 1.0234 & 0.0002 & 0.0387 \\ 0.0000 & -0.1123 & 0.9967 & 0.0053 \\ 0.0000 & 1.1573 & 0.0076 & 0.9450 \end{bmatrix}\)
- $B_d^{fd}\approx [\,0.006652\ -0.015364\ 0.331717\ -0.760593\,]^\top$
- $K^{fd}\approx [\,-0.3706\ -7.9560\ -0.7996\ -1.6728\,]$
정리하면, $A_d, B_d, K$ 의 상대오차가 순서대로 $3.95\%, 3.8\%, 10.46\%$ 있었고 $A_d,B_d$가 완전히 동일하지 않기 때문에(시뮬 내부의 마찰/관성/수치적분 때문에), 같은 $Q,R$을 쓰더라도 최종 LQR 이득 $K$가 달라진다. 이 차이가 이후의 외란/포화 조건에서 성능 차이(회복시간, 각도 RMS, 포화 빈도)로 이어지는지 실험으로 확인해보려 한다.
이론 이산화 vs 시뮬 이산화
eval_sweep.py와 plot_results.py라는 스크립트를 2개 만들어서 두 데이터를 추출/비교했다.
eval_sweep 파일로 amp, seed, success, terminated_any, T, u_energy, sat_rate, sat_steps, sat_any, theta_max_post, theta_rms_post, recovery_time, steps, dt, u_max, t0, duration, kind, theta0 등을 계산하여 csv에 저장하였다.
plot_result 파일로 위 데이터의 그래프를 그렸다.
다음과 같은 조건으로 데이터를 계산했다.
python -m experiments.eval_sweep \
--amps 0,0.5,1,2,3,4,5 \
--seeds 20 \
--disturbance-kind impulse --t0 200 \
--theta0 0.2 \
--out logs/summary.csv
이후 plot을 통해 각 amp별 10번씩 시뮬레이션을 수행하여 결과를 시각화 해보았다.
 |
 |
 |
 |
 |
 |
그래프 간단 설명
-
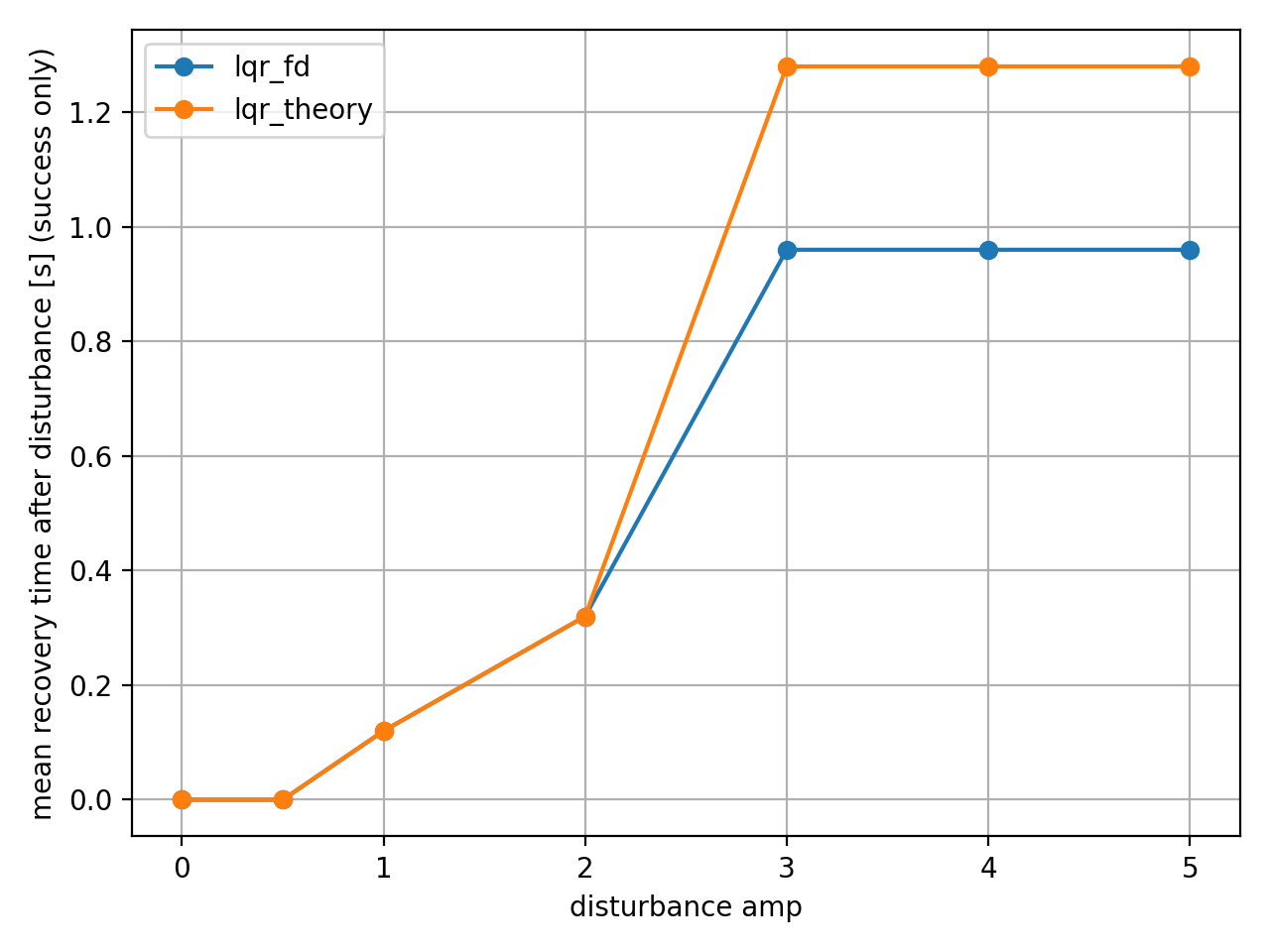
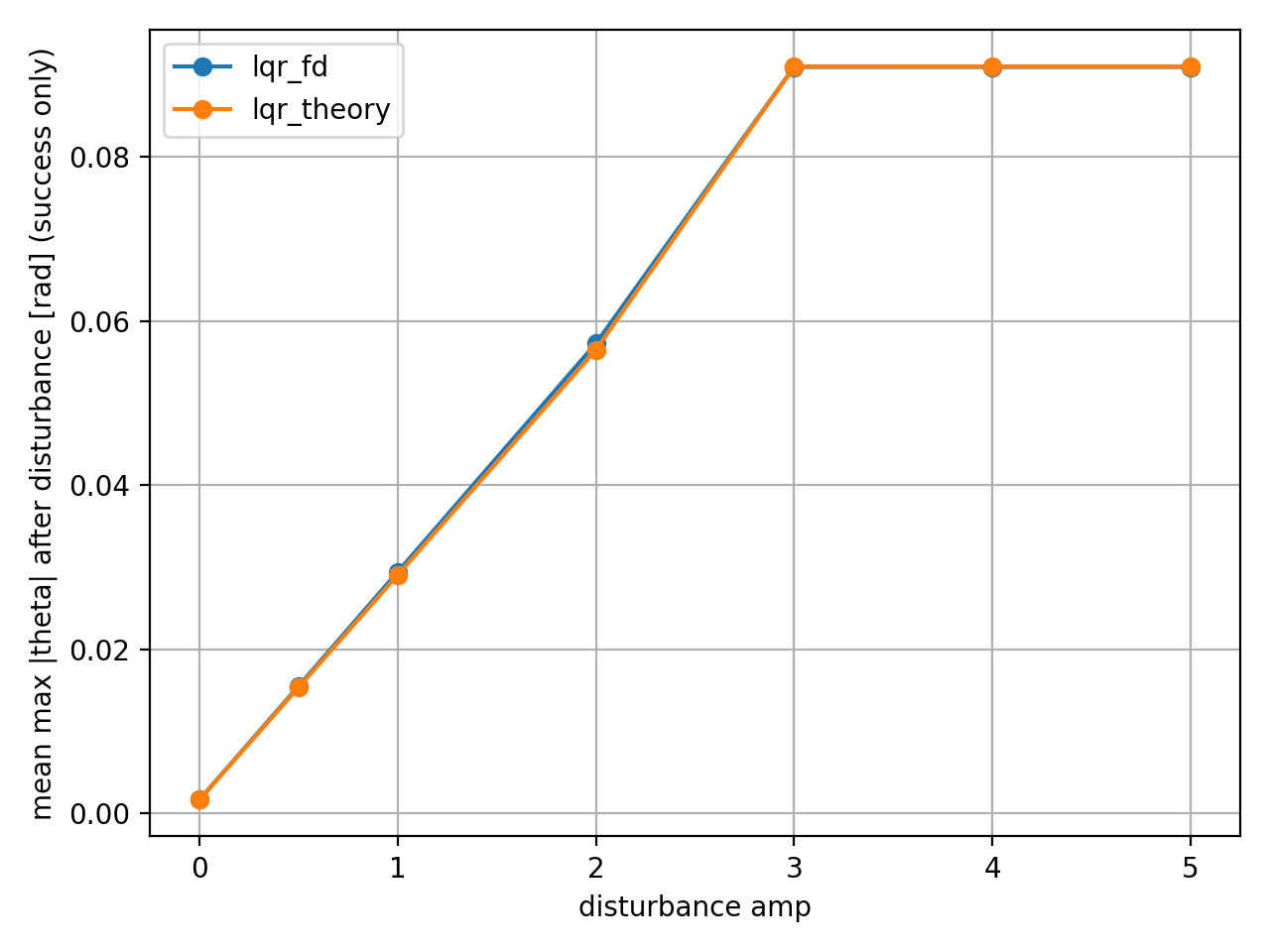
recovery_time: 외란이 끝난 시점 이후로, $\vert \theta \vert$가 기준 임계값 $\theta_{\text{tol}}$ 아래로 들어가서 연속 $N$ 스텝 동안 유지될 때까지 걸린 시간 [s]. (성공 에피소드만 집계)
- amp=3 기준에서 LQR_fd : 0.96s, LQR_theory : 1.2s로 시뮬 이산화 조건에서 0.32s(약 25%) 빨랐다.
-
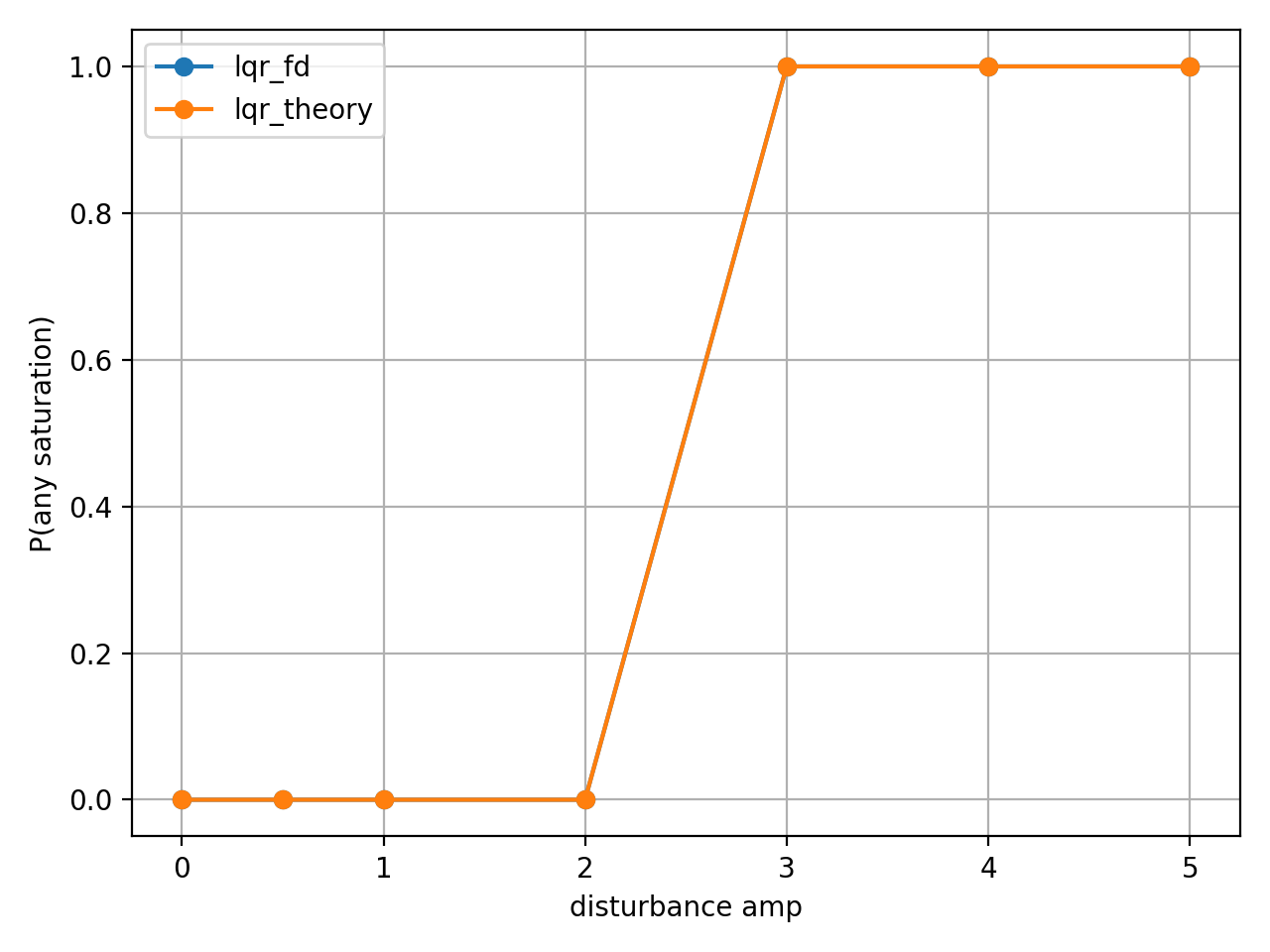
sat_any_rate: 에피소드 동안 한 번이라도 입력이 포화($\vert u \vert \ge u_{\max}$)에 걸린 경우의 비율
- amp=3 부터 입력이 포화된 경우가 생기기 시작했다.
-
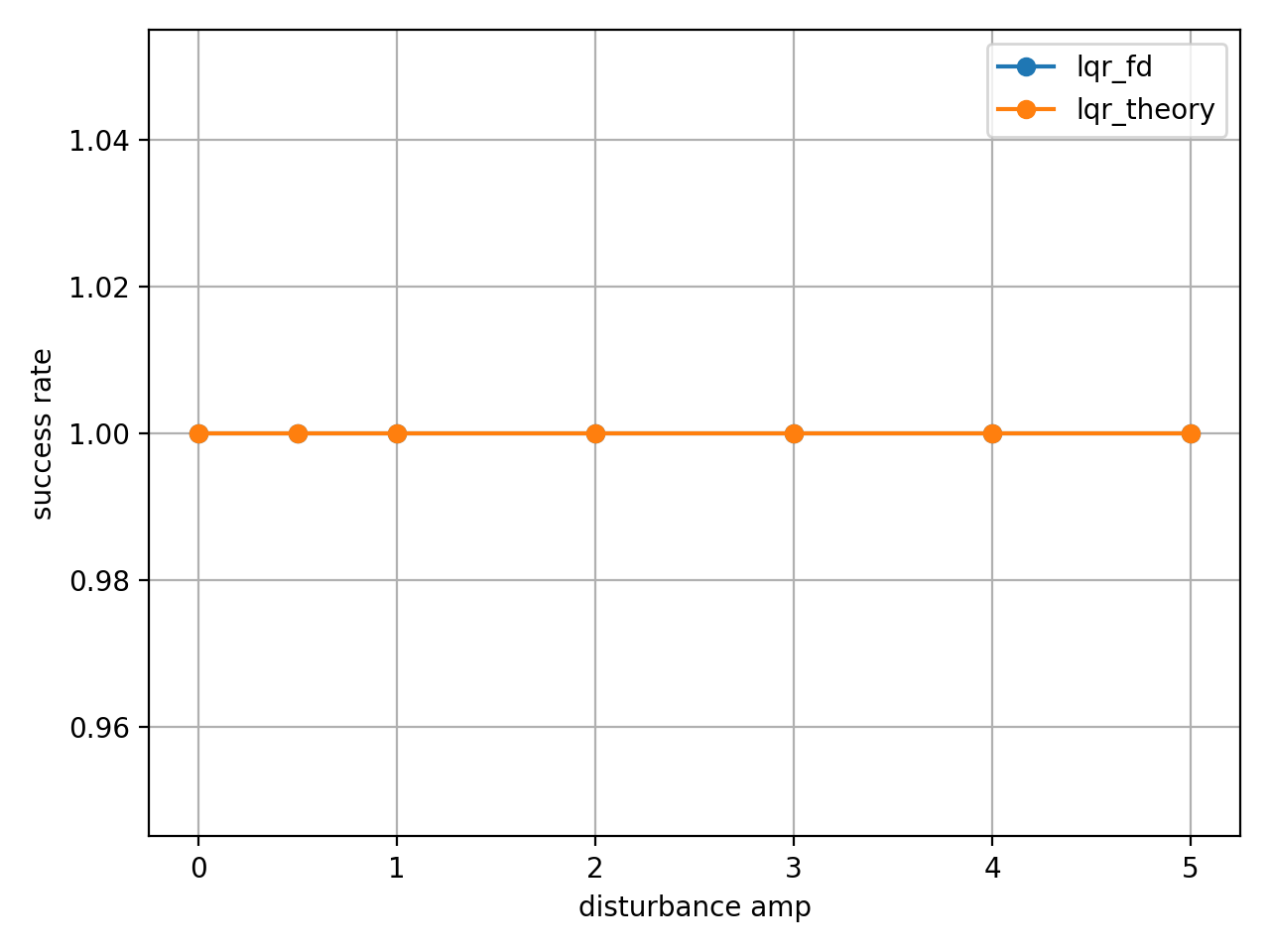
success_rate: 종료 조건을 만족하지 않고(각도/레일 범위 이탈 등) 설정한 최대 스텝까지 안정적으로 유지한 에피소드 비율.
- 특정 amp에서 포화되기는 했지만, 아직까지는 모두 제어에 성공했다.
-
theta_max_post: 외란 이후 구간에서의 $\vert \theta \vert$ 최대값의 평균 [rad]. (성공 에피소드만 집계)
-
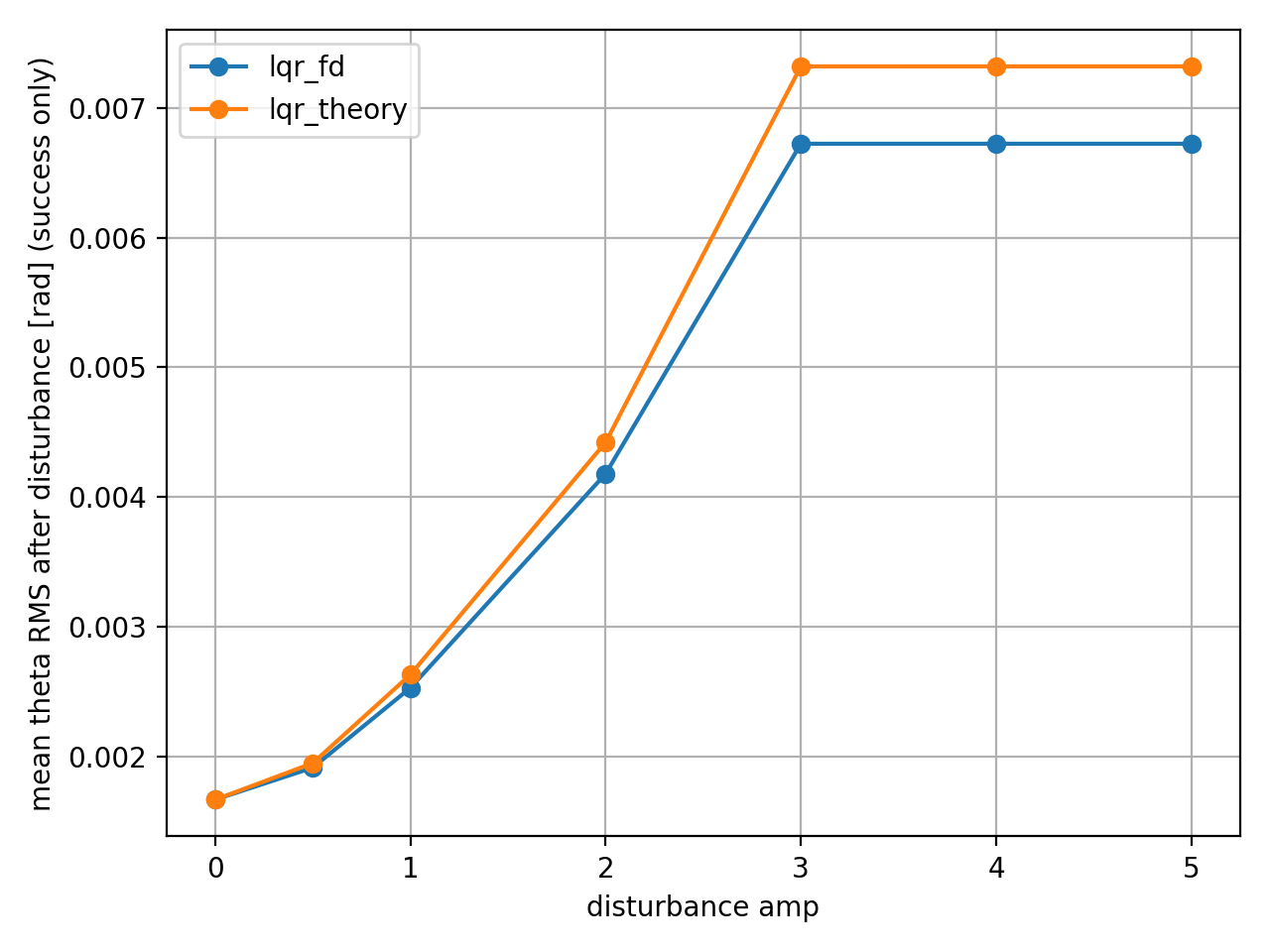
theta_rms_post: 외란 이후 구간에서의 $\theta$ RMS(제곱평균제곱근) 값의 평균 [rad]. (성공 에피소드만 집계)
- LQR_fd : 0.006723 rad, LQR_theory : 0.007318 rad 으로 fd가 약 8.1% 더 작았다.
-
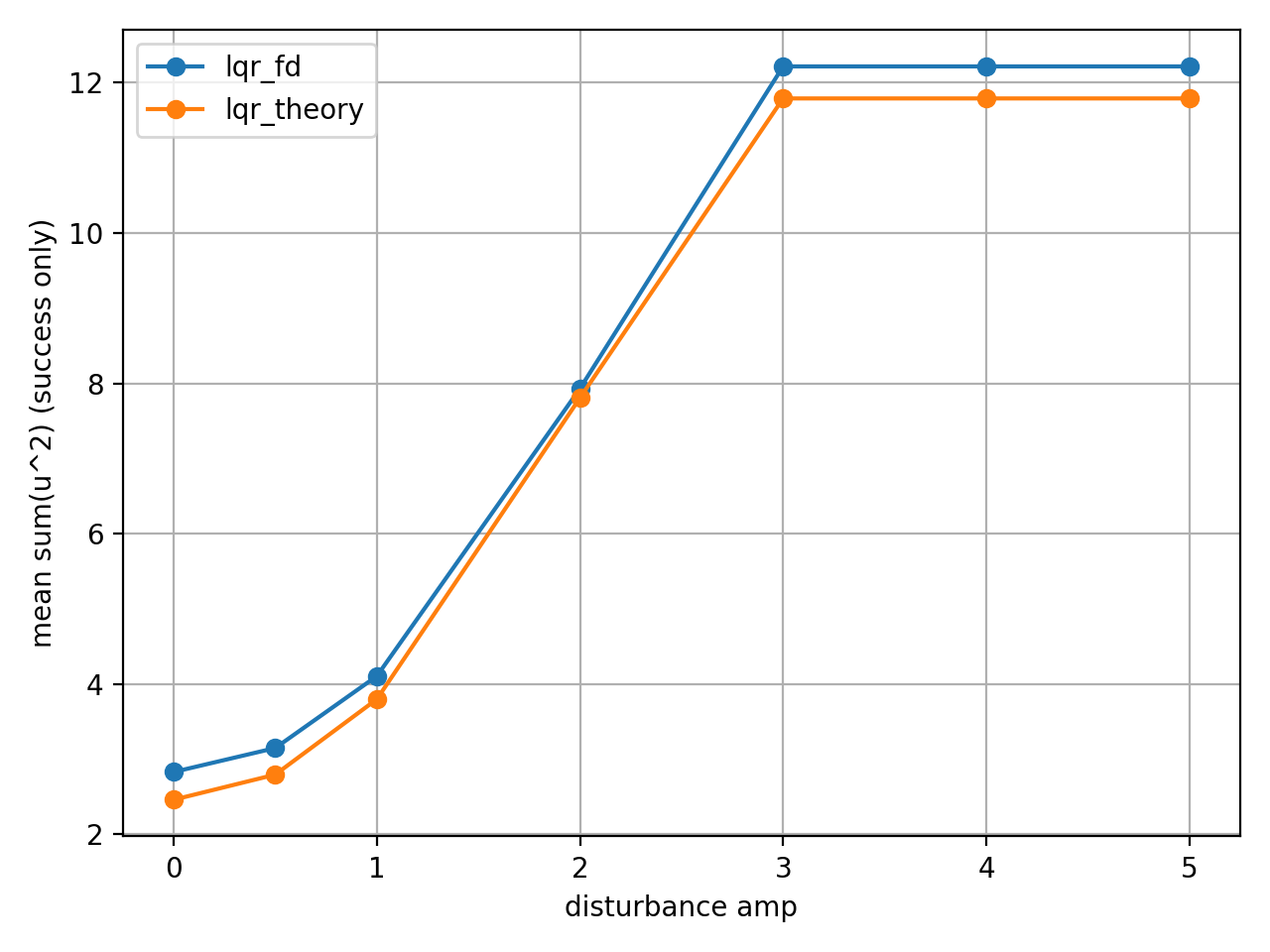
u_energy: 전체 구간에서 제어 입력 에너지로 $\sum_k u_k^2$ 를 사용한 값의 평균.
- LQR_fd : 12.217 rad, LQR_theory : 11.791 rad 으로 fd가 약 3.6% 더 컸다.
- fd가 더 공격적으로 에너지를 사용하고 더 빨리 안정권으로 복귀한다.
중간 결론
- sat_any 그래프는 한 번이라도 포화면 1을 찍기 때문에 amp=3 이상에서 의미가 없어졌다. 대신 sat_steps와 sat_rate를 추가로 추출해서 같은 포화일 때, 얼마나 더 또는 덜 포화에 걸리는지 확인이 필요하다.
- amp를 0부터 5까지 주었지만 amp=3 이상부터 결과가 같게 나온것을 보니 시뮬레이션 내부적으로 제어 입력 클램핑이 amp=3 까지로 제한되어 있음을 예상할 수 있다.
-
지금 말할 수 있는 것
- 동일한 성공률 100% 조건에서, 포화가 발생하는 amp>3 구간에서, FD 기반의 LQR이 더 빠르게 회복하고, 각도 RMS가 더 작지만, 에너지를 더 쓴다.
-
아직 낼 수 없는 결론
- amp가 커져도 계속 잘 버틴다.
개선
-
amp=3에서 시뮬레이션 내부적으로 제한이 걸리기 때문에, 내가 직접 외력을 정의해서 카트에 가해주는 방식으로 외란을 변경했다.
-
한 번이라도 포화되었는지를 보는 sat_any를 구체화해서 포화된 비율(rate)과 연속적으로 포화된 스텝 수를 나타내는 그래프를 그렸다.
-
총 비용 J를 계산해서 amp별로 그래프에 나타내었다.
-
외력을 impulse 형태가 아닌 wind의 형태로 5 step 동안 지속적으로 작용하도록 하였다.
-
포화가 일어나는 지점 근방의 amp로 세밀하게 나누어 그래프를 그렸다.
python -m experiments.eval_sweep \
--amps 250,260,270,280,290 \
--seeds 10 \
--disturbance-kind window --duration 5 \
--t0 100 \
--theta0 0.0 \
--out logs/summary.csv
결과
 |
 |
 |
 |
 |
 |
 |
 |
-
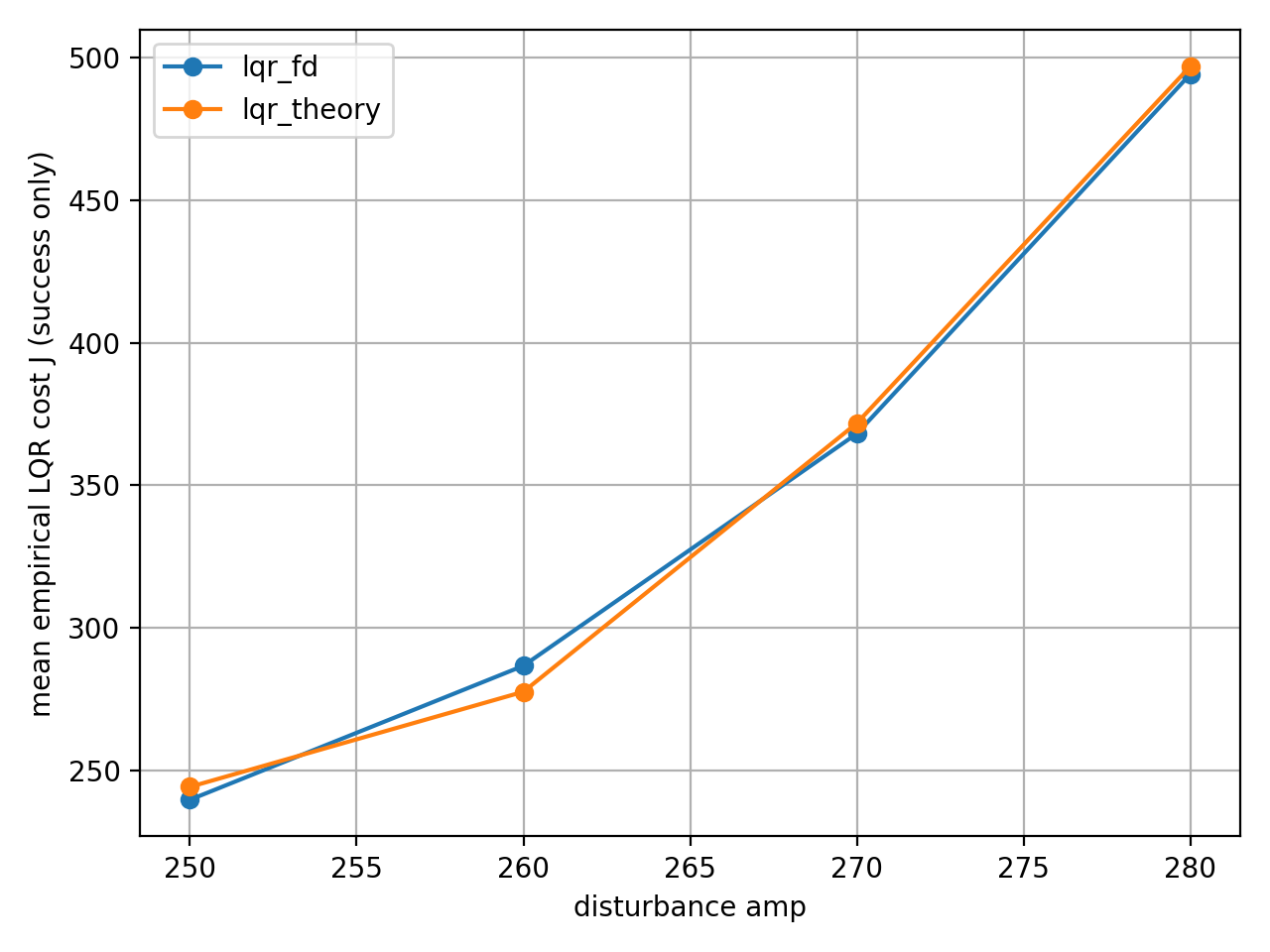
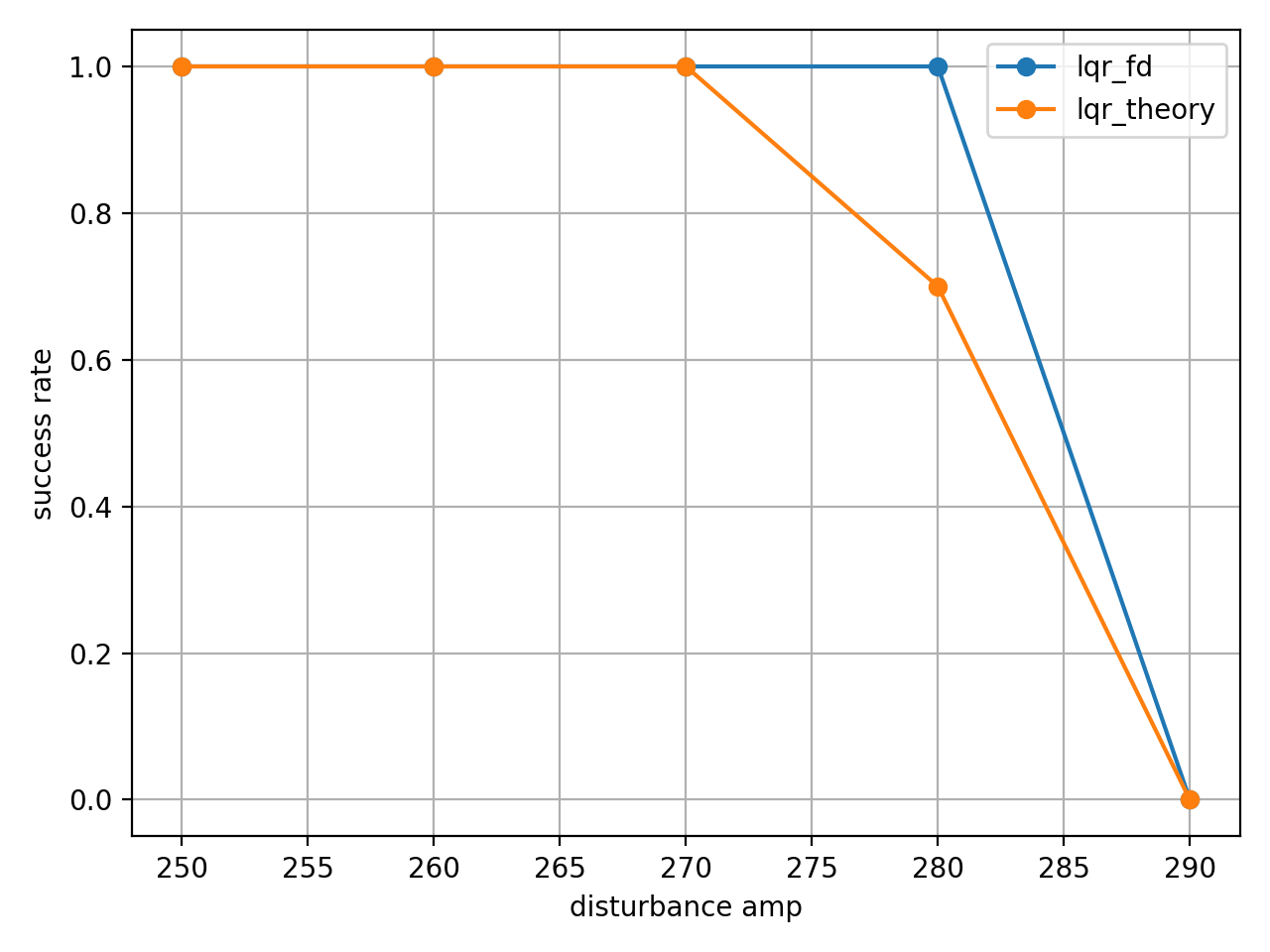
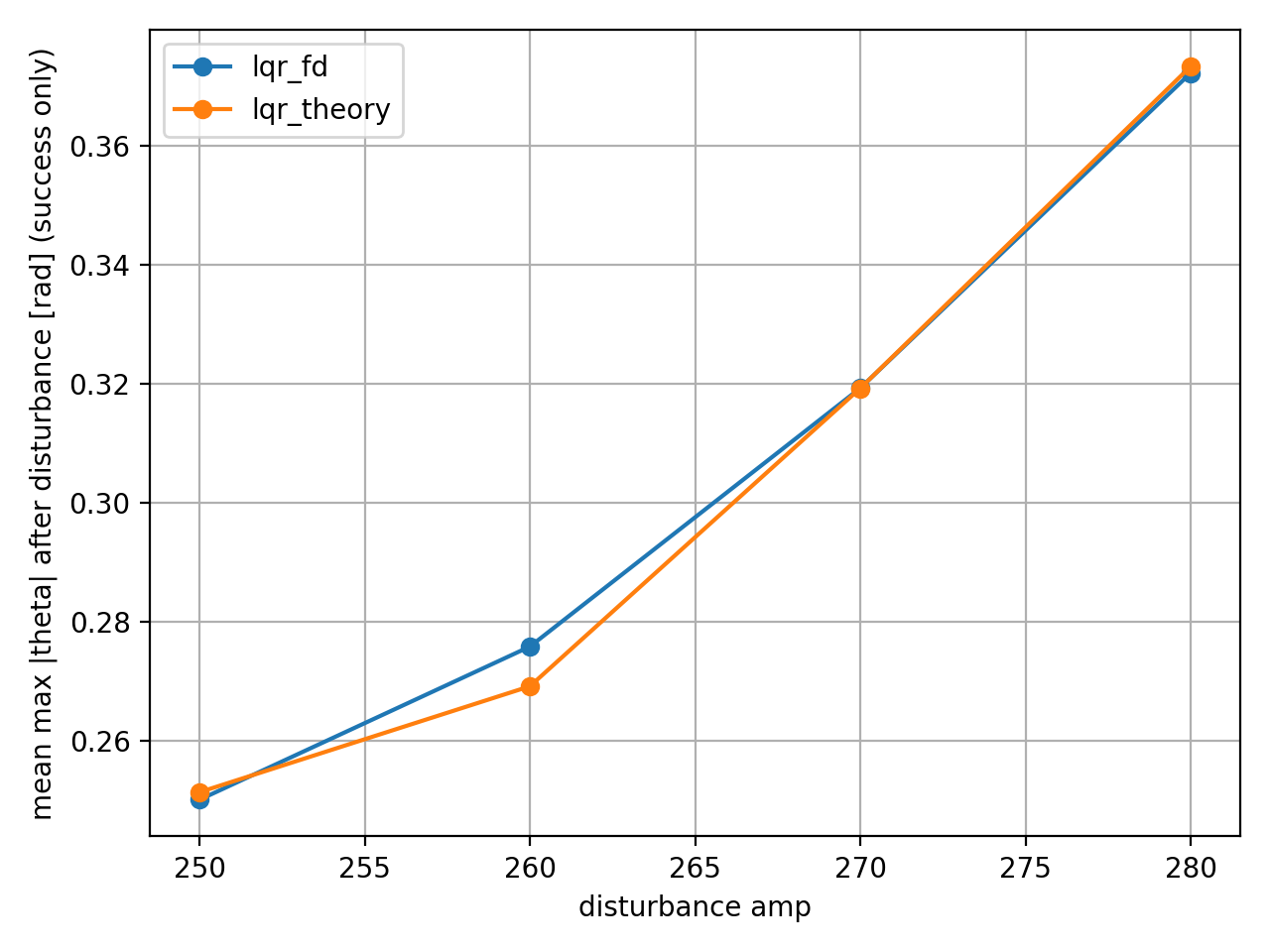
이론적 모델은 한계 상황에서 무너졌으나, 데이터 기반 모델은 살아남았다.
- 외란 강도 amp=280에서 이론 LQR은 약 30%의 실패율을 보였으나, 시뮬 LQR은 100% 생존하며 더 높은 강건성을 보였다.
-
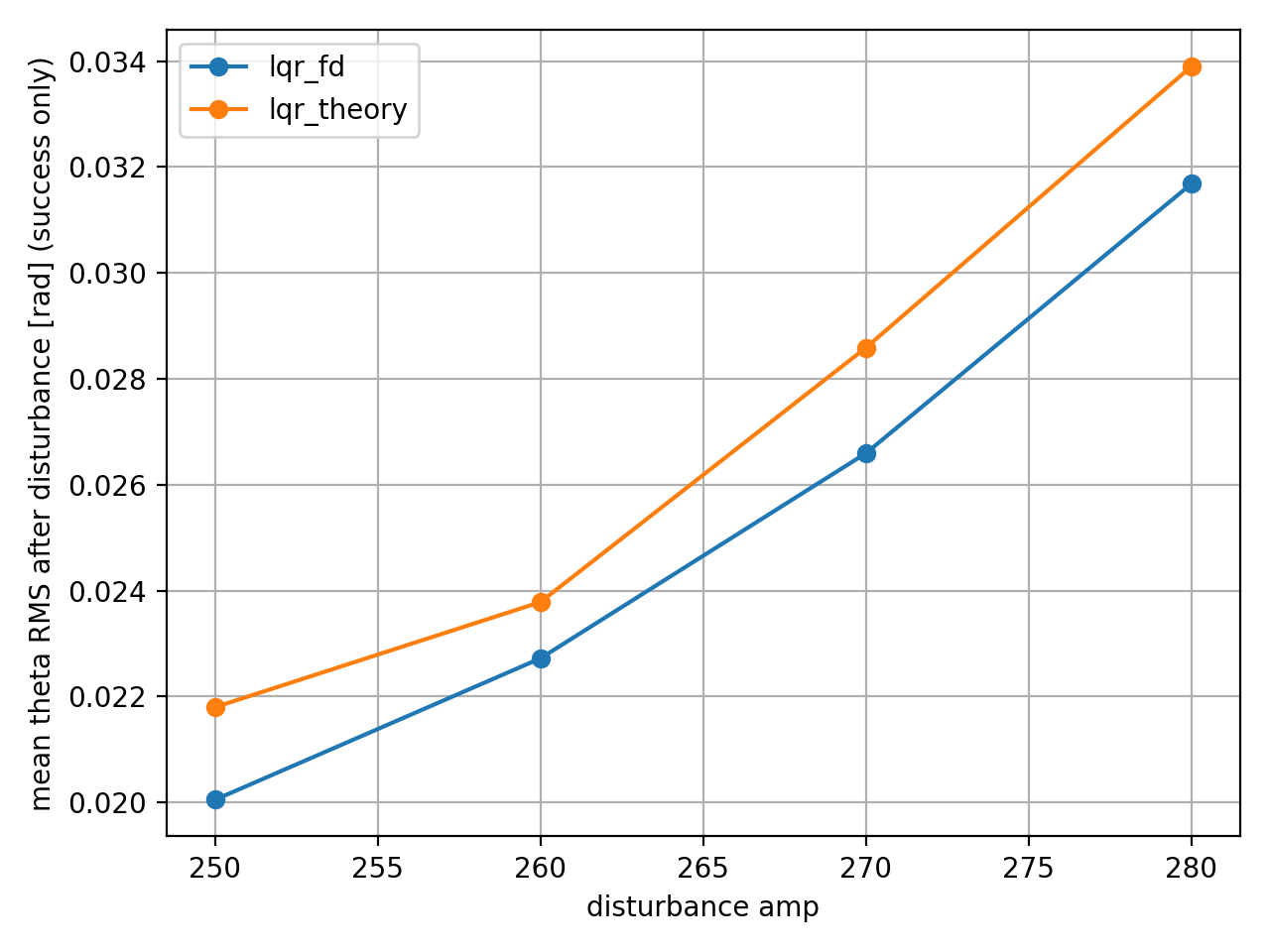
살아남았더라도 제어의 질은 달랐다.
-
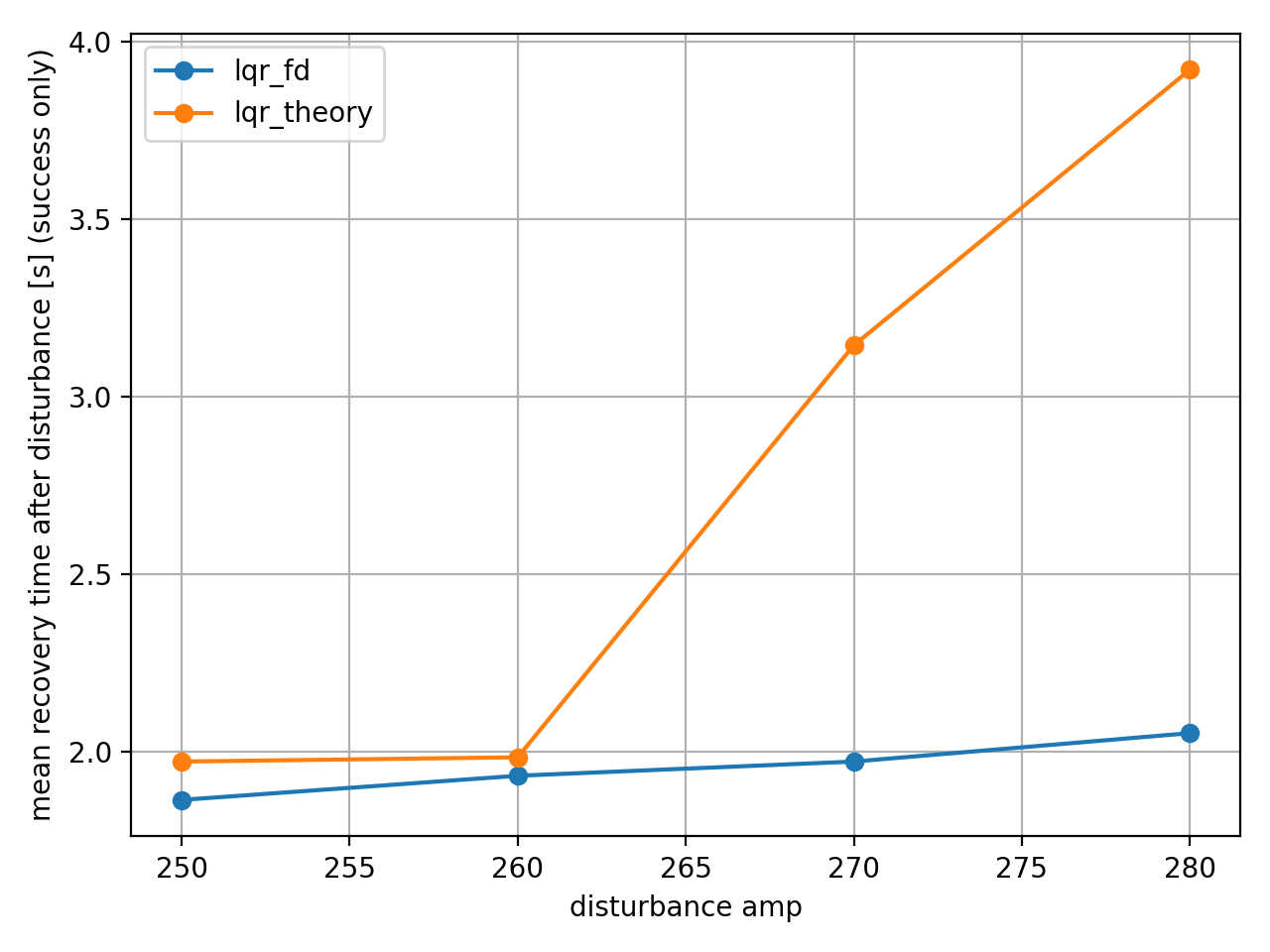
시뮬 LQR은 외란 강도가 증가해도 2초 내외로 회복했으나, 이론 LQR은 amp=270 이상에서 회복 시간이 급격히 증가했다.
-
두 제어기의 최대 이탈 각도는 유사했음에도 불구하고, RMS 값은 차이가 컸다. 이론 LQR이 감쇠가 부족하여 도립으로 복귀하는 과정에서 불필요한 진동이 있었다는 것을 알 수 있다. 이 진동이 길게 지속되어 RMS에 값이 누적되었다.
-
-
amp=280에서 두 제어기의 최대 각도가 거의 동일하게 나타난 것은 성공한 경우만의 평균이기 때문이다.
- raw data 분석 결과, 이론 LQR은 실패한 경우에서 각도가 0.48rad 이상 올라갔으나, 성공 케이스는 시뮬 LQR과 비슷한 0.37rad 수준에서 멈췄다.
-
왜 LQR만으로는 부족할까? (MPC를 사용하는 이유)
-
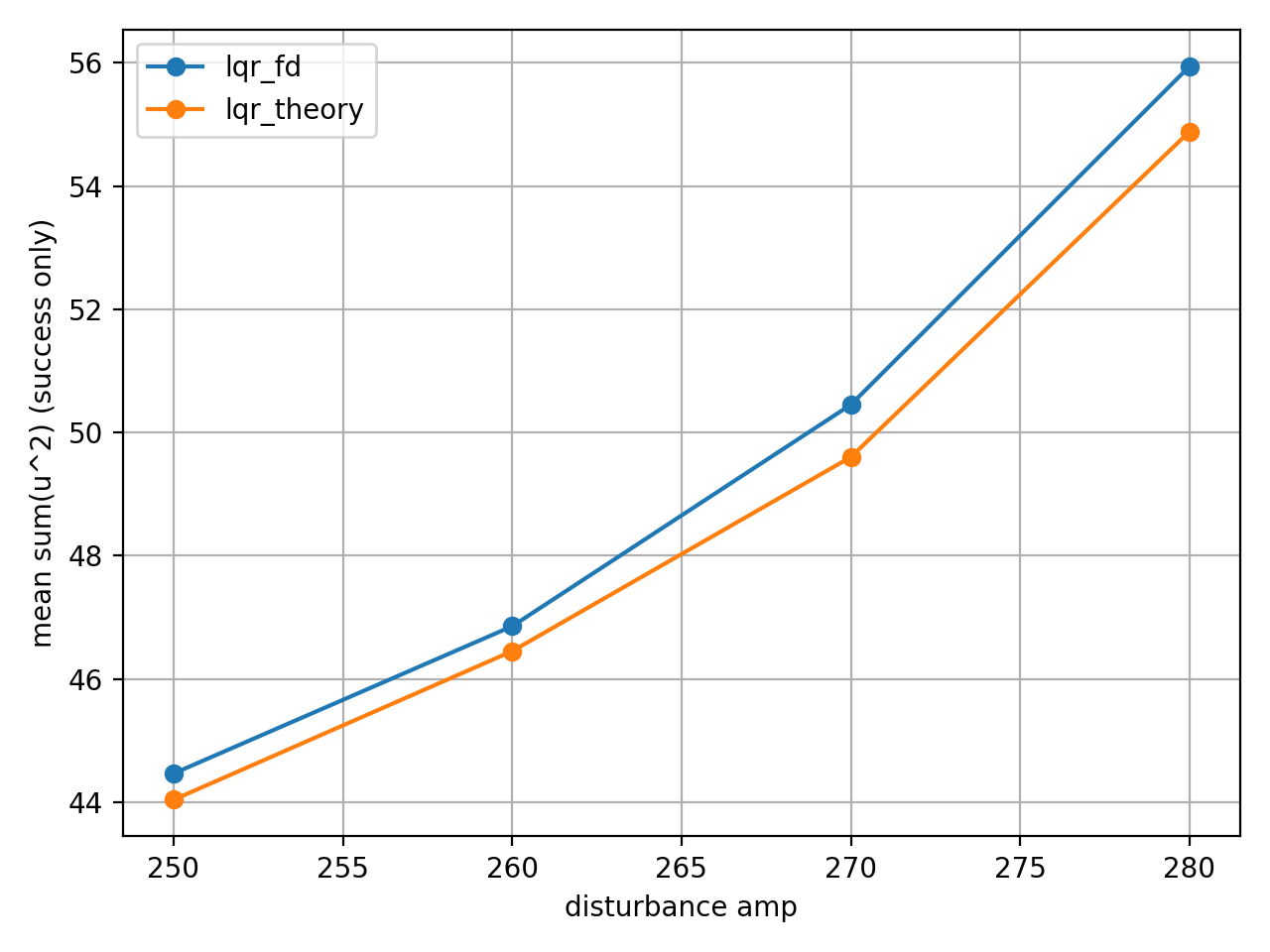
시뮬 LQR은 이론 LQR 대비 약 2~5% 더 많은 에너지를 소비했다. 그 결과 적극적인 제어 입력을 가해 과도 응답 구간을 단축시켰다.
-
두 제어기의 총 비용 $J$는 비슷했지만, 미세한 잔류 진동이 $J$ 값에 크게 반영되지 않았기 때문이다. 실질적인 제어 안정감은 $J$ 값의 차이보다 컸다.
-
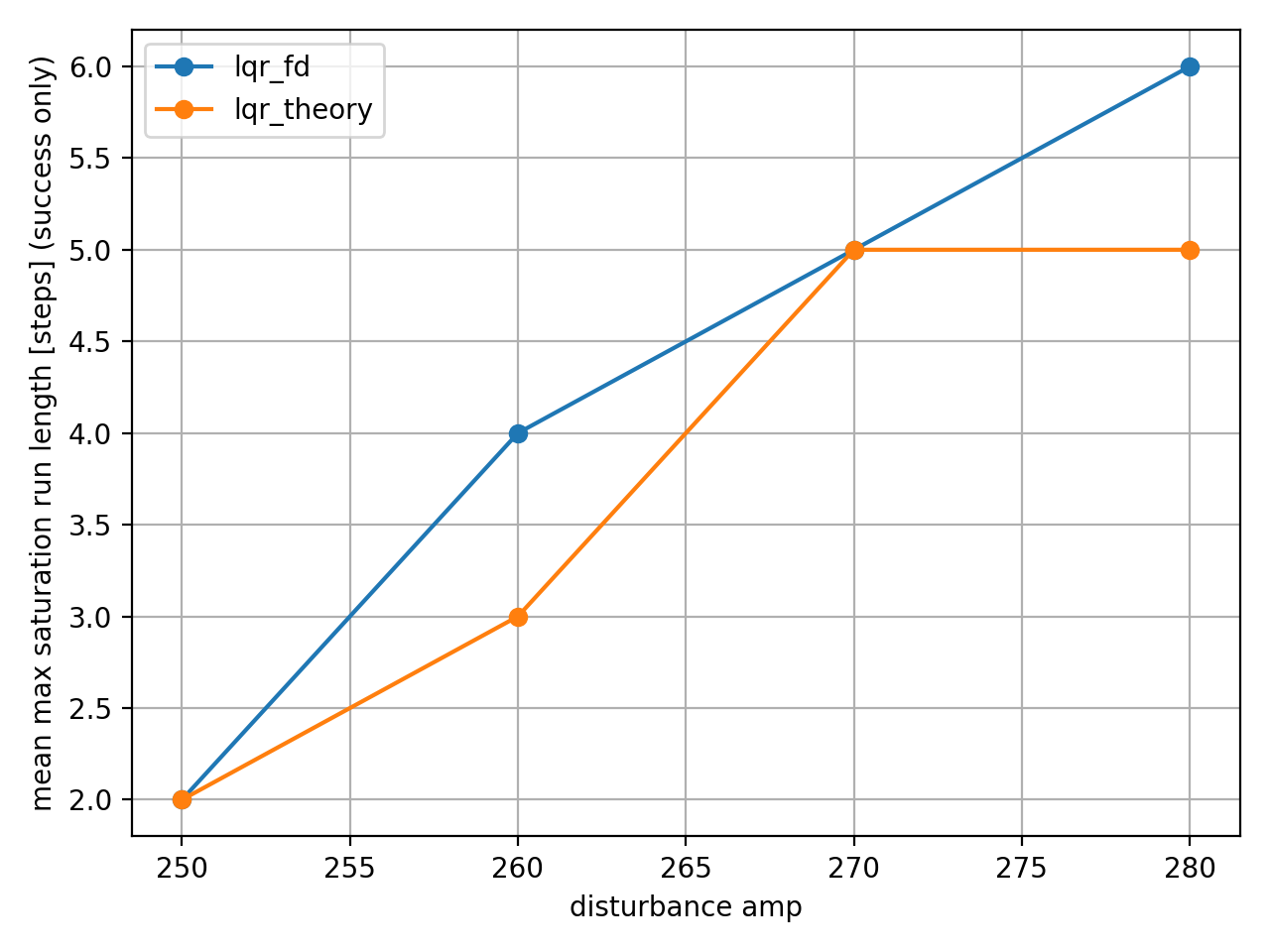
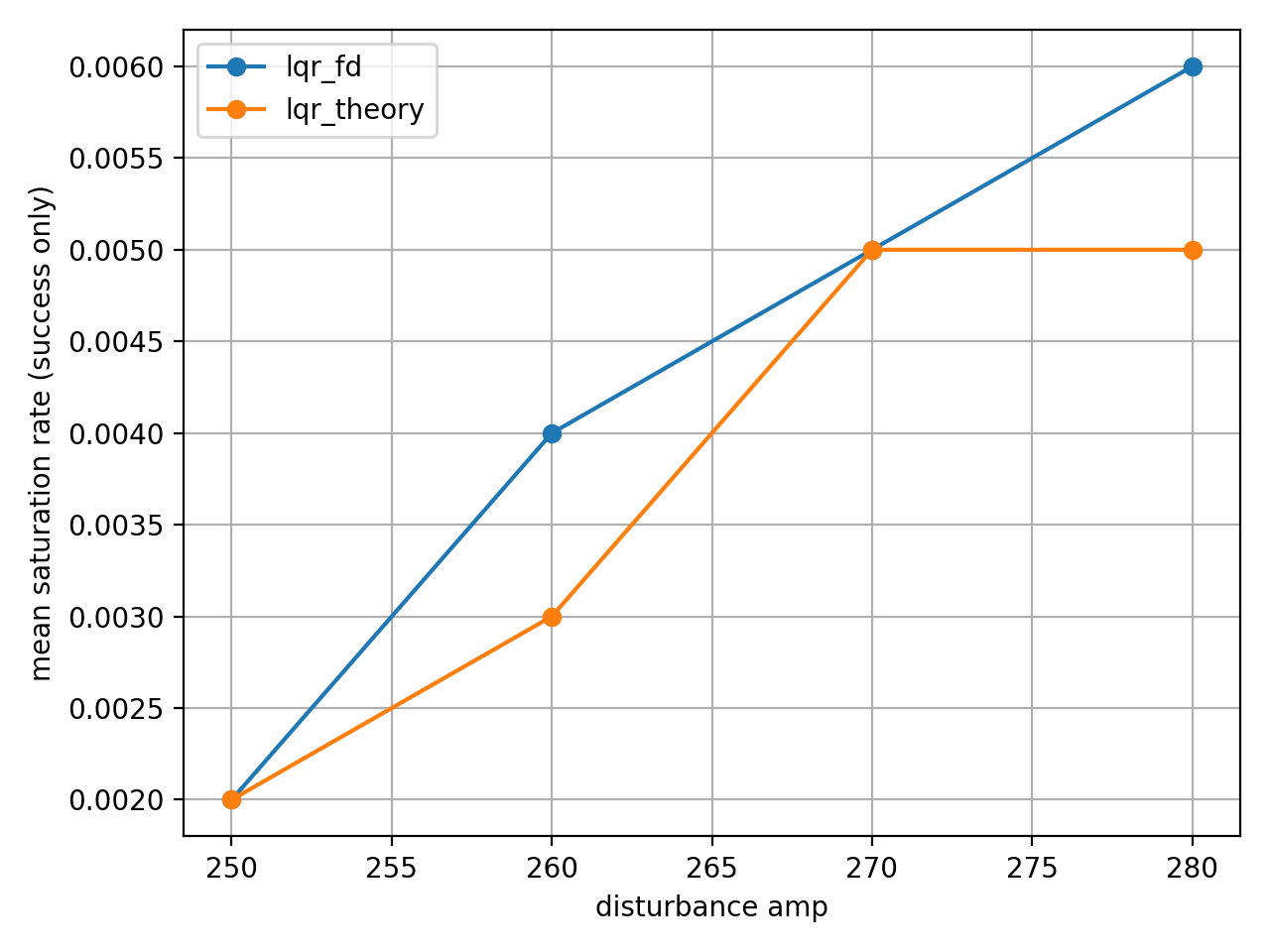
amp=270 이상에서 두 제어기 모두 외란이 들어오는 5 step 동안 입력 포화 상태였다. LQR은 이런 입력 제한을 고려하지 못하므로, amp=290 이상의 외란에서는 물리적 한계로 인해 제어 불능 상태가 되었다.
-