LQR vs MPC : 제어 실패의 이유 차이가 뭘까
동기
로봇 제어를 공부하면서 LQR-MPC 제어를 사용할 때, 막상 “각 제어 방식이 어느 지점에서 차이를 보이는지”를 내 손으로 검증해본 적은 없었다.
이번 프로젝트의 질문은 단순하다.
- 제약이 없을 때
- 여러 제약으로 인한 포화가 추가되었을 때
- 지연/노이즈 오차가 추가되었을 때
각각에서 LQR, MPC는 어떤 실패모드로 무너지고, 무엇이 강건성을 만들어 내는가?
이를 위해 Mujoco의 표준 도립진자 환경에서 동일 조건으로 구현/비교하고, 결과를 재현 가능한 코드와 로그로 남긴다.
실험 세팅
아래 카트-폴 모델을 사용하여 운동 방정식을 통해 수식을 작성하였다.
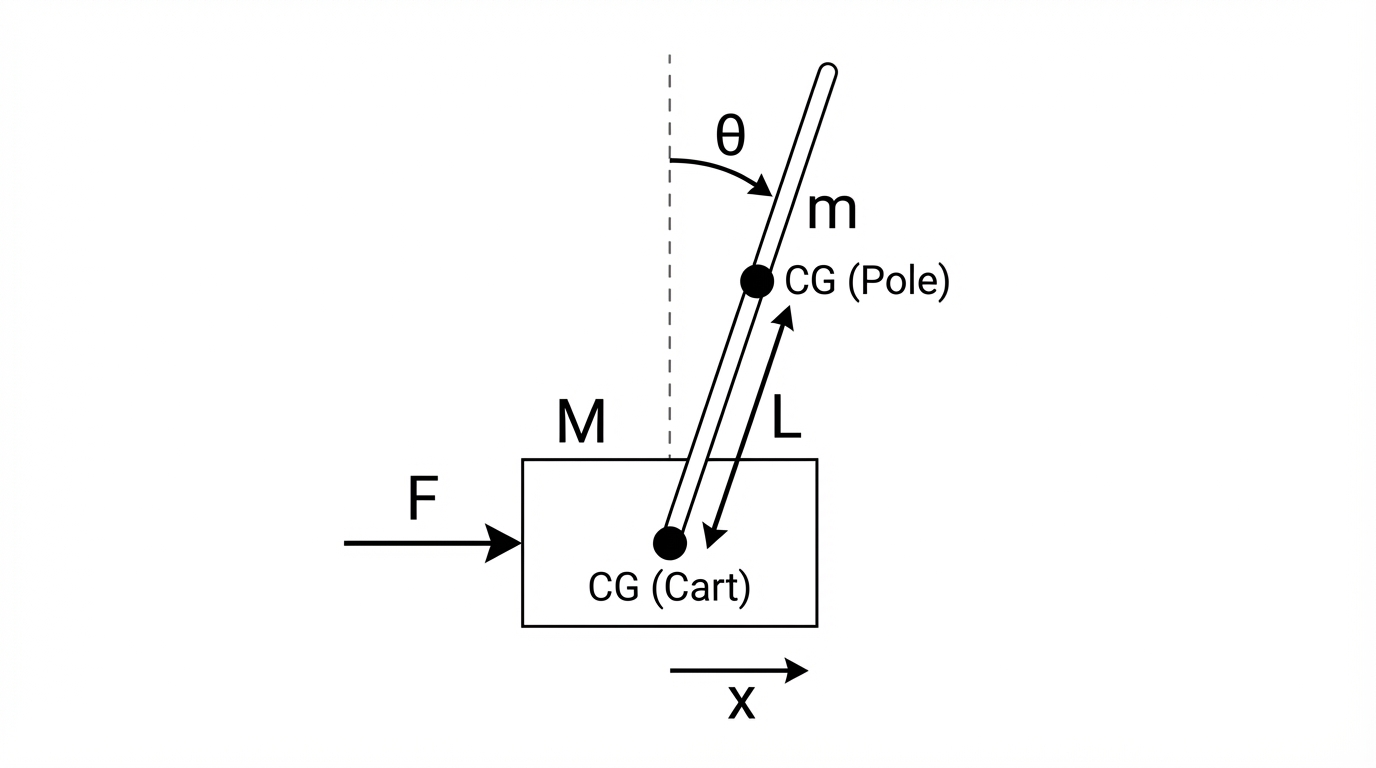
$x : \text{카트 위치},\ \theta : \text{막대 각도(직립이 } \theta=0\text{)},\ u : \text{환경 action}$
$M : \text{카트 질량}$
$m : \text{막대 질량}$
$l : \text{힌지}\rightarrow\text{막대 COM 거리}$
$I : \text{막대 COM 기준 관성(힌지 축 기준)}$
$g : \text{중력가속도} $
$F : \text{카트에 작용하는 수평 힘(외력)} $
$F’ = \mathrm{gear}\,u \ \text{(제어 힘)}$
$\theta$ 가 가장 위험하니 $Q$ 에서 $\theta$ 에 가장 큰 가중치 80을 두었다.
$R$은 입력 제한이 있으니 과도한 입력을 줄이기 위해 0.1로 두었다.
$ Q=\begin{bmatrix}
1.0 & 0 & 0 & 0
0 & 80.0 & 0 & 0
0 & 0 & 1.0 & 0
0 & 0 & 0 & 10.0
\end{bmatrix}$
$R=\begin{bmatrix} 0.1 \end{bmatrix}$
모델은 이전 프로젝트에서 분석한 시뮬레이션 이산화 모델을 그대로 사용하였다.
아래 내용은 이전 프로젝트에서 발췌한 부분
Mujoco에 들어가 있는 모델을 사용하여, 시뮬레이션 환경에 최적화 + 선형화된 $A_d^{fd}, B_d^{fd}$ 를 구했다.
관측 상태는 동일하게 $\mathbf{x}=[x,\theta,\dot{x},\dot{\theta}]$를 사용하며, 아래는 터미널에서 확인한 값이다.
- 이론 모델 (theory)
- $A_d^{th}\approx$ \(\begin{bmatrix} 1.0000 & -0.0023 & 0.0400 & -0.0000 \\ 0.0000 & 1.0240 & 0.0000 & 0.0403 \\ 0.0000 & -0.1171 & 1.0000 & -0.0023 \\ 0.0000 & 1.2053 & 0.0000 & 1.0240 \end{bmatrix}\)
- $B_d^{th}\approx [\,0.006700\ -0.015800\ 0.335309\ -0.793131\,]^\top$
- $K^{th}\approx [\,-0.3554\ -7.1830\ -0.7326\ -1.6947\,]$
- 시뮬 수치 선형화 (FD)
- $A_d^{fd}\approx$ \(\begin{bmatrix} 1.0000 & -0.0023 & 0.0399 & 0.0001 \\ 0.0000 & 1.0234 & 0.0002 & 0.0387 \\ 0.0000 & -0.1123 & 0.9967 & 0.0053 \\ 0.0000 & 1.1573 & 0.0076 & 0.9450 \end{bmatrix}\)
- $B_d^{fd}\approx [\,0.006652\ -0.015364\ 0.331717\ -0.760593\,]^\top$
- $K^{fd}\approx [\,-0.3706\ -7.9560\ -0.7996\ -1.6728\,]$
발췌 부분 끝
실험 결과
본격적으로 LQR과 MPC를 직접 분석해보려고 한다.
제약이 없는 경우
선형 이산 시스템과 2차 비용에서, 제약이 없고 terminal cost가 DARE의 P인 경우,
유한지평 MPC의 첫 입력은 무한지평 LQR의 입력과 일치해야한다.
지금 실험은 제약/노이즈/지연 실험에서 나타나는 차이를 원인별로 분리하기 위해, 시뮬레이션 구현이 이 성질을 재현하는지 검증한다.
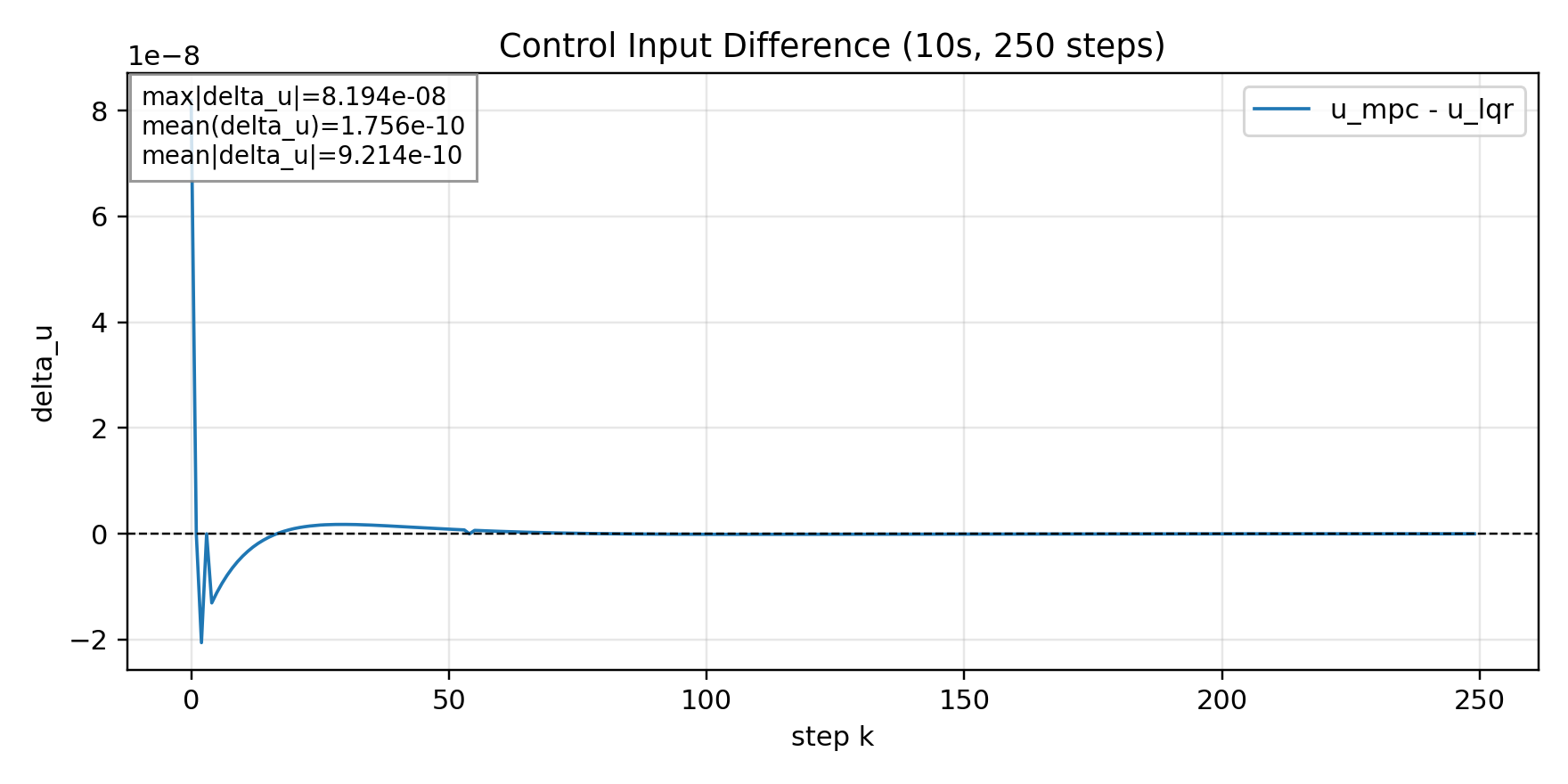
이상적인(무마찰, 무댐핑) 파이썬(sanity 체크용)에서 계산 결과
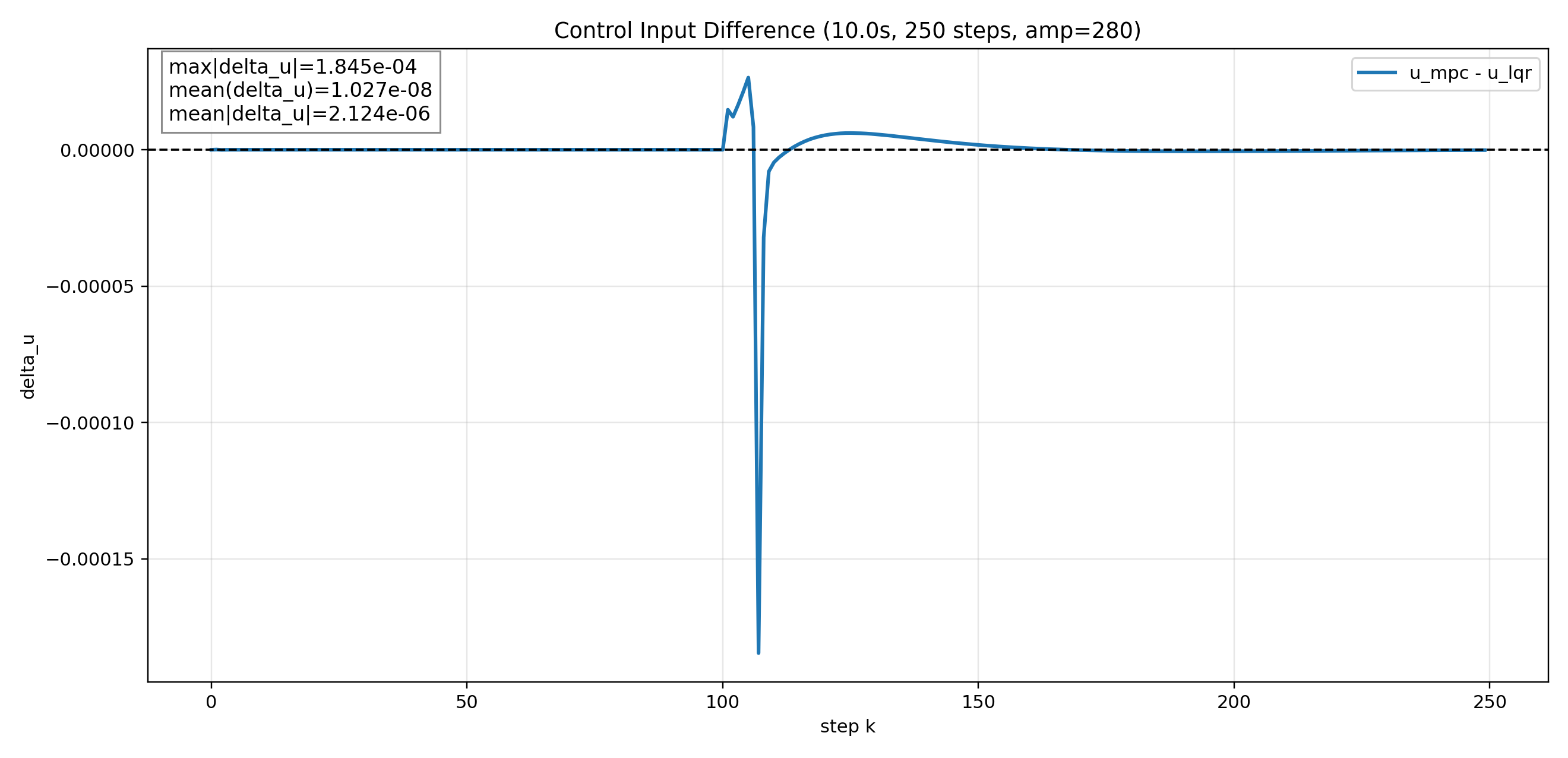
실제 시뮬레이션(Mujoco)에서 계산 결과
동일 모델에 파이썬과 실제 Mujoco 시뮬레이션에 무제약을 적용했다.
두 환경에서 모두 MPC에 입력 제약을 충분히 크게 설정하여 제약이 활성화되지 않도록 했을 때, MPC와 LQR의 제어 입력 차이(u_mpc - u_lqr)가 $10^{-8}$ 수준으로 수치오차 범위 안에서 일치했다.
무제약 구간에서 MPC가 LQR과 동일한 입력을 내는지 확인해서, 앞으로의 실험에서 차이가 발생하면 그것이 제약이나 노이즈 때문임을 분리해서 해석할 수 있는 기준을 확립하였다.
이제 MPC의 실질적인 이점은 제약이 있는 상황에서 나타남을 확인해 볼 차례이다.
제약이 있는 경우
제약
제약을 크게 3가지로 두었다.
$x$ : 레일의 길이 제약
$u$ : 입력의 제약
$\Delta u$ : 입력 변화량의 제약
$u$ 와 $\Delta u$ 는 시뮬레이션 상황이지만, 모터가 낼 수 있는 힘 범위와 순간 힘이 변할 수 있는 양에 한계가 정해져 있다는 것을 반영하였다.
- $u_{\min} \leq u \leq u_{\max}$, where $u_{\min} = -3$, $u_{\max} = 3$
- $x_{\min} \leq x \leq x_{\max}$, where $x_{\min} = -1$, $x_{\max} = 1$
- $\Delta u = 2.6$
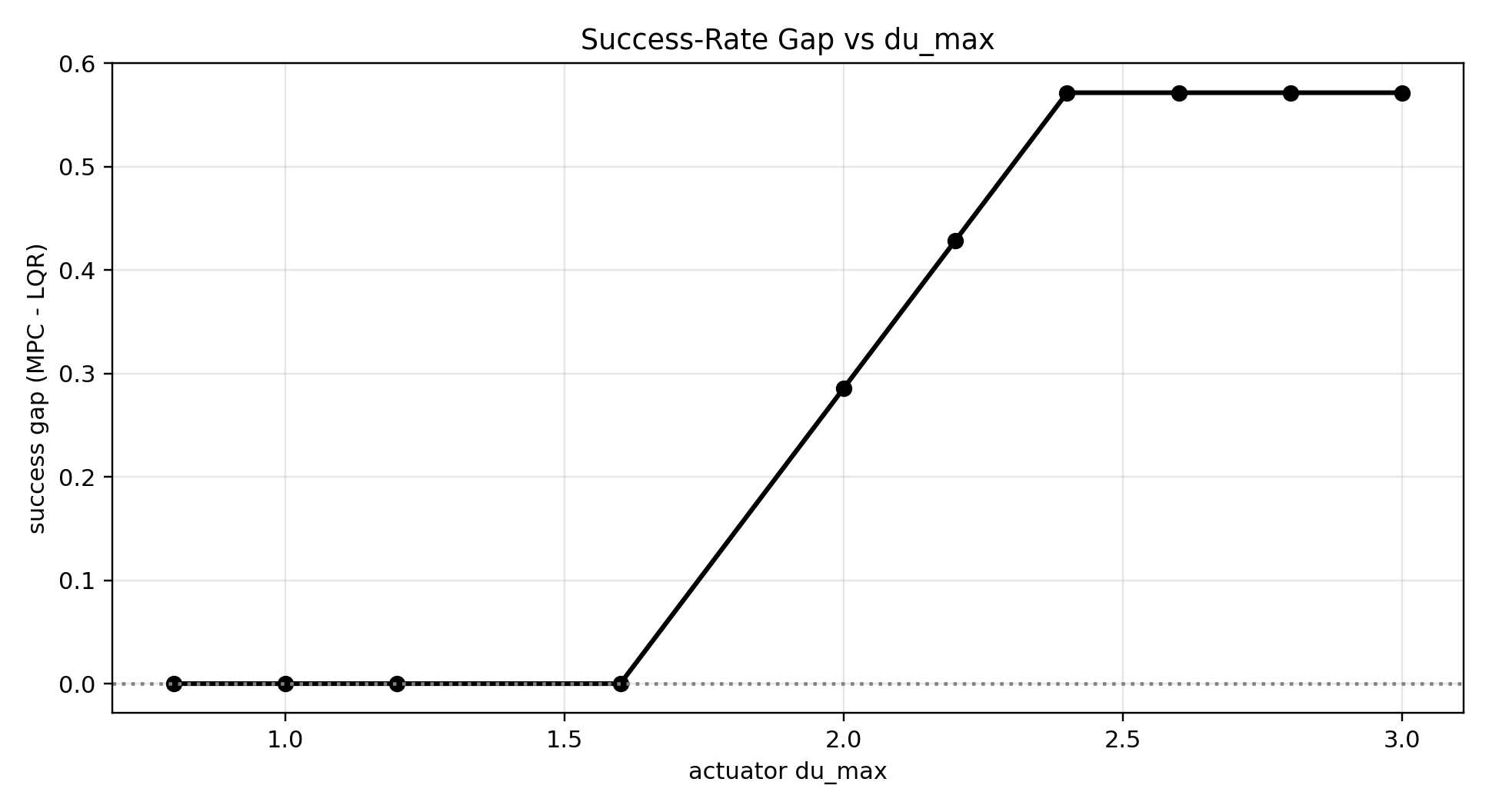
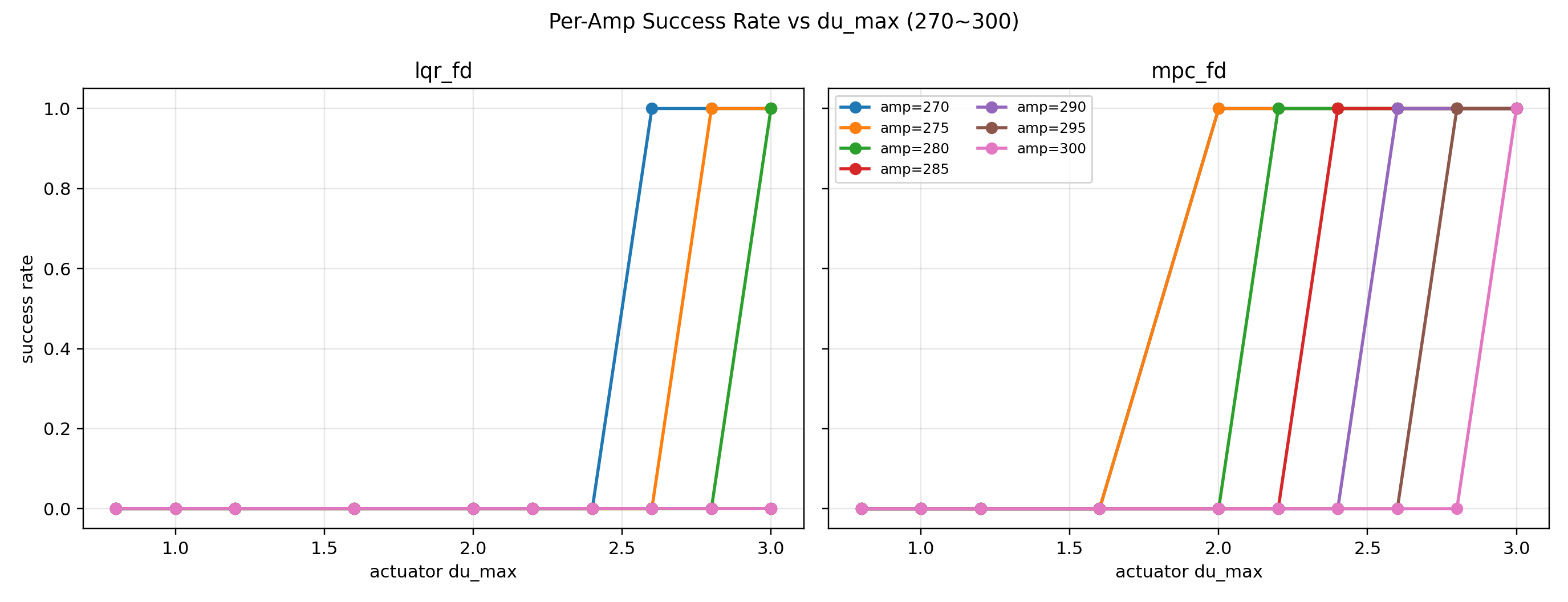
$\Delta u$ 가 너무 작거나 너무 크면 이 amp 구간에서 LQR이랑 MPC가 둘 다 실패하거나(둘 다 0%), 둘 다 성공해서(둘 다 100%) 차이를 보여주기 어려웠다.
그래서 먼저 amp 250~290처럼 결과가 갈리기 시작하는 전이 구간을 잡고, 그 안에서 $\Delta u$ 를 0.8~3.0으로 실험했다.
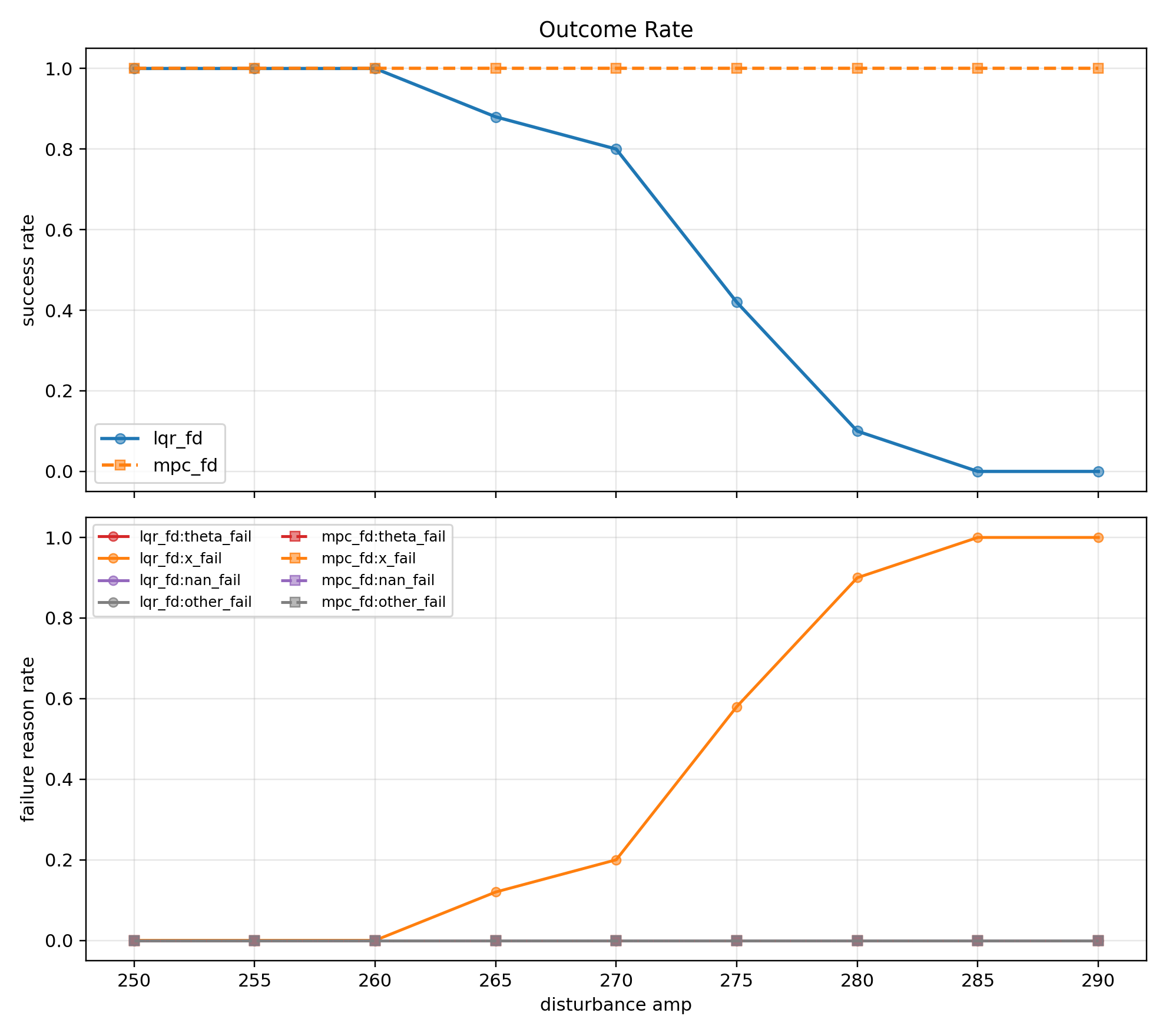
위 두 그래프는 amp별, $\Delta u$별 성공률 전체 실험 결과를 보여준다.
그 중에서 두 제어기의 성공률 차이가 가장 잘 드러나는 값 $\Delta u = 2.6$ 을 대표값으로 선택하였다.
성공 판정 조건
외란이 가해진 이후
- 막대 각도가 $90^\circ$ 이내 유지
- 카트가 레일 양 끝에 닿지 않음
결과
 |
 |
 |
 |
 |
|
 |
 |
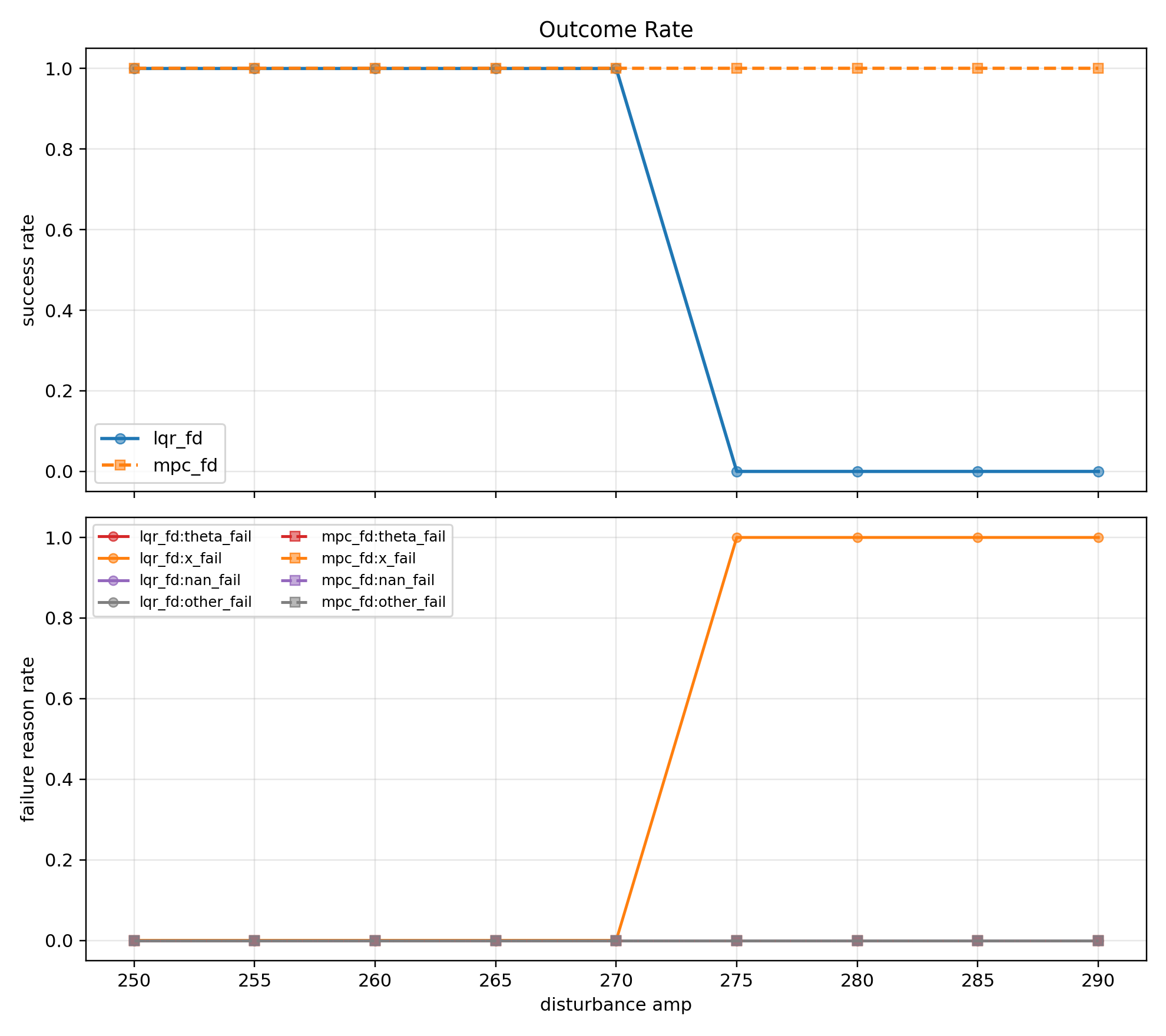
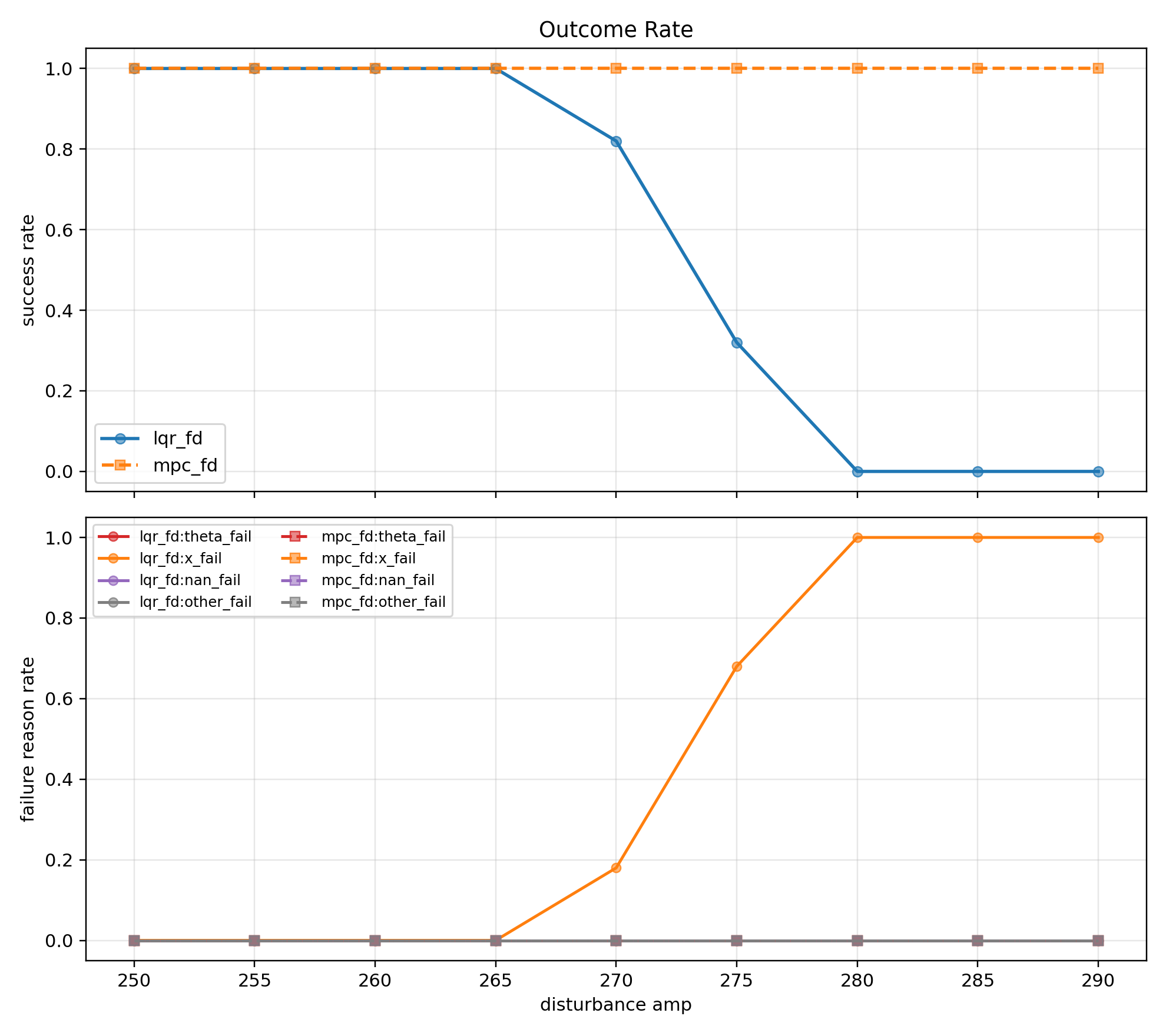
(1 - amp 250~290 성공률)
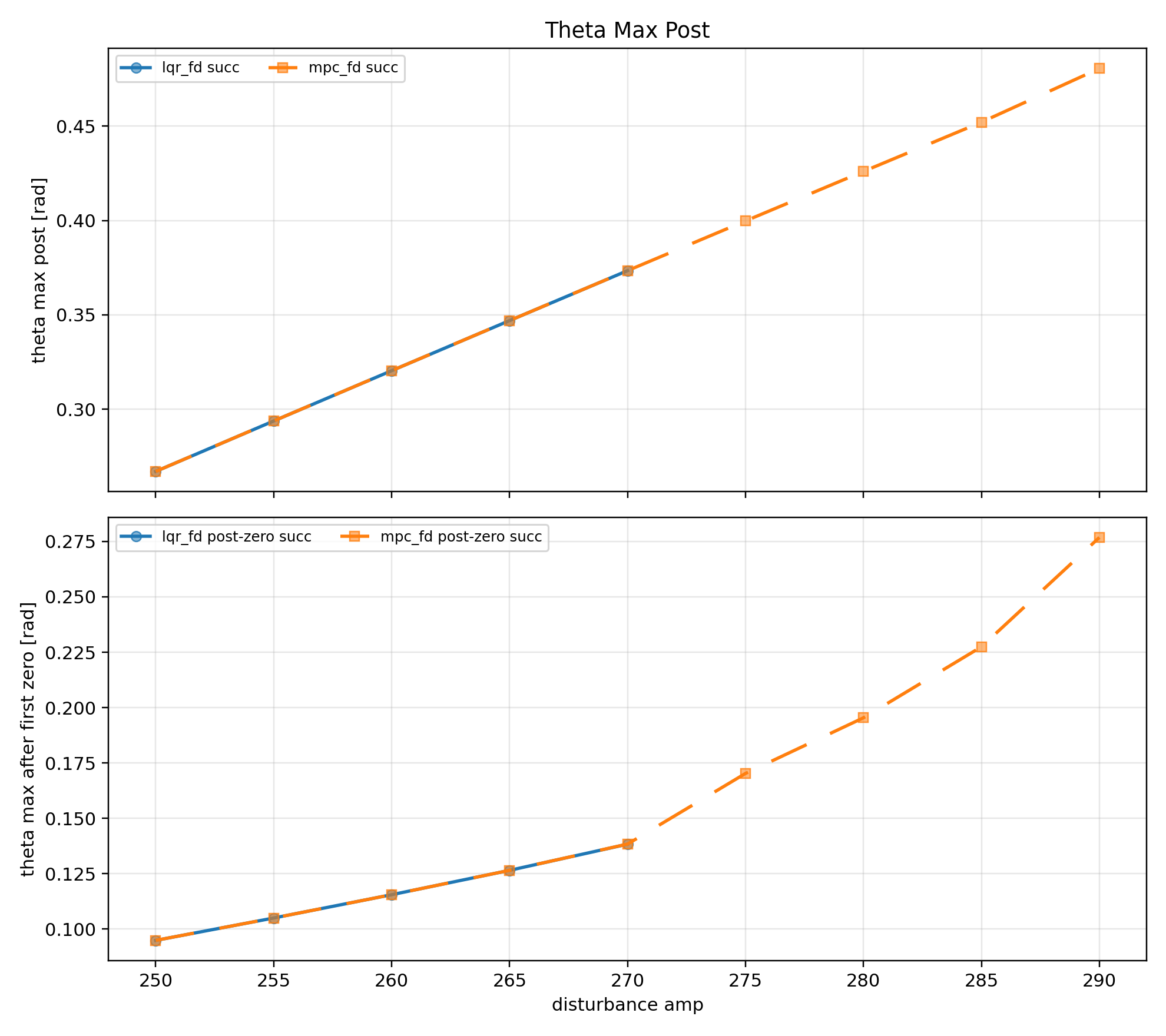
(2 - amp 250~290 최대 각도)
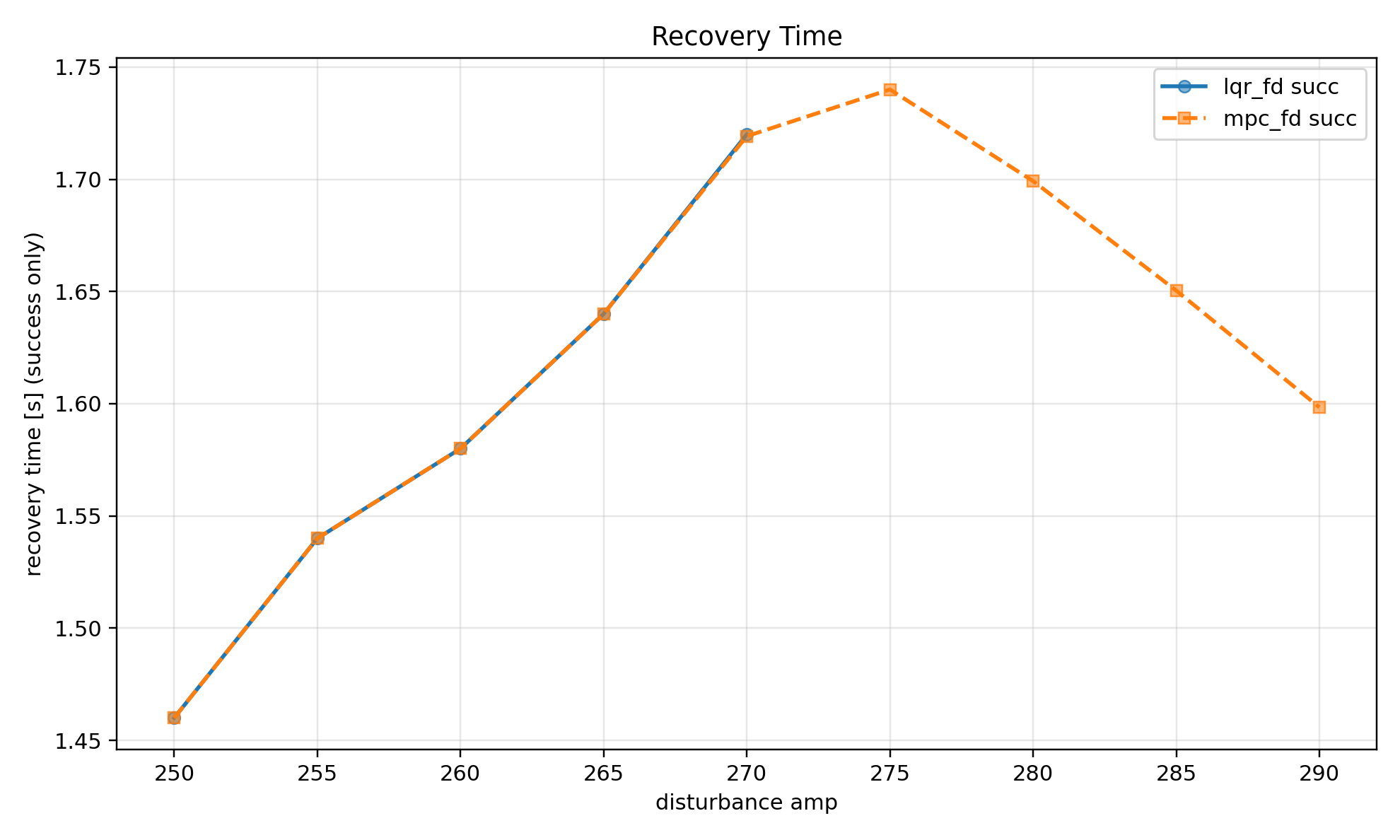
(3 - amp 250~290 회복 시간)
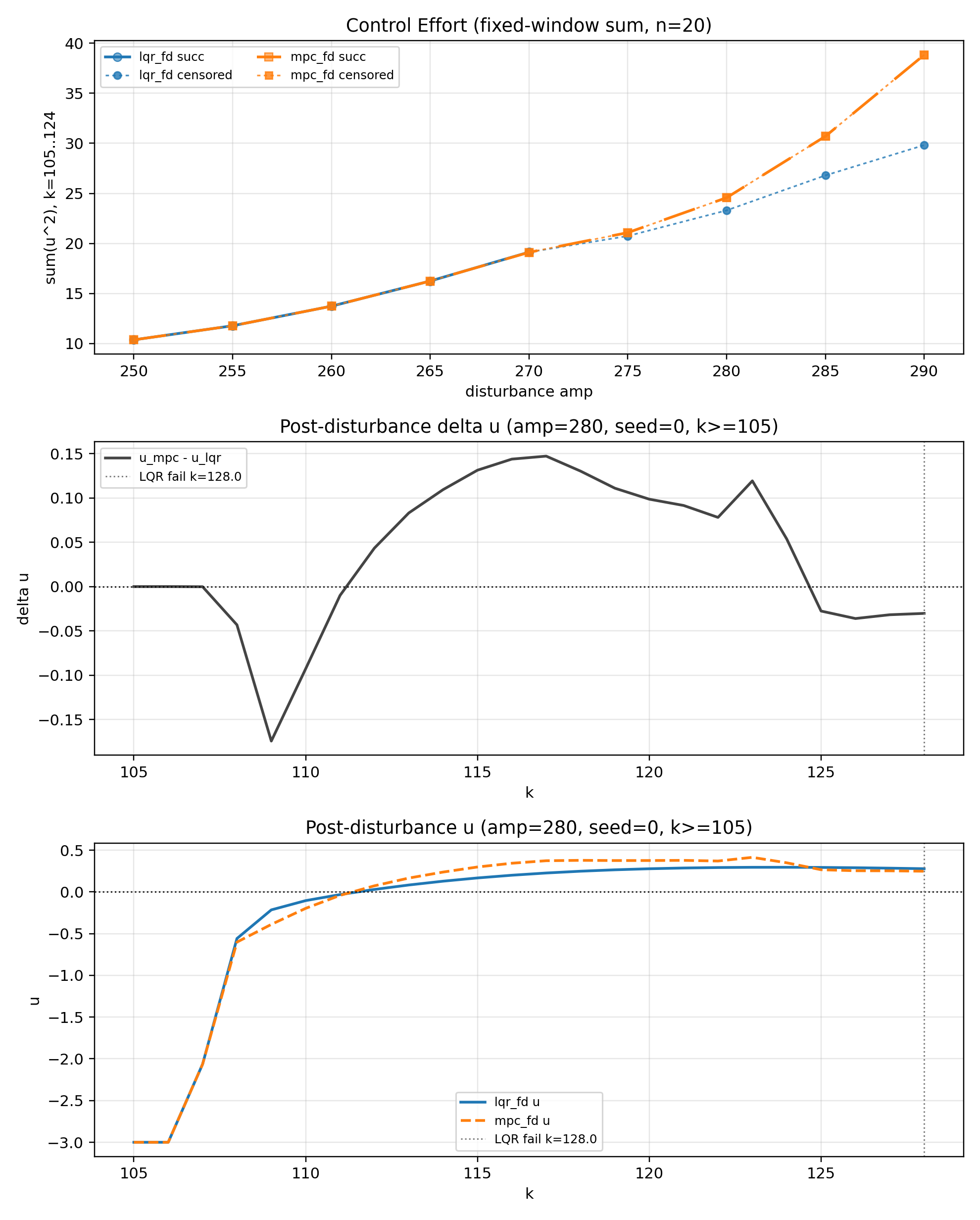
(4 - amp 250~290 외란 이후 20 step동안 제어 입력 u)
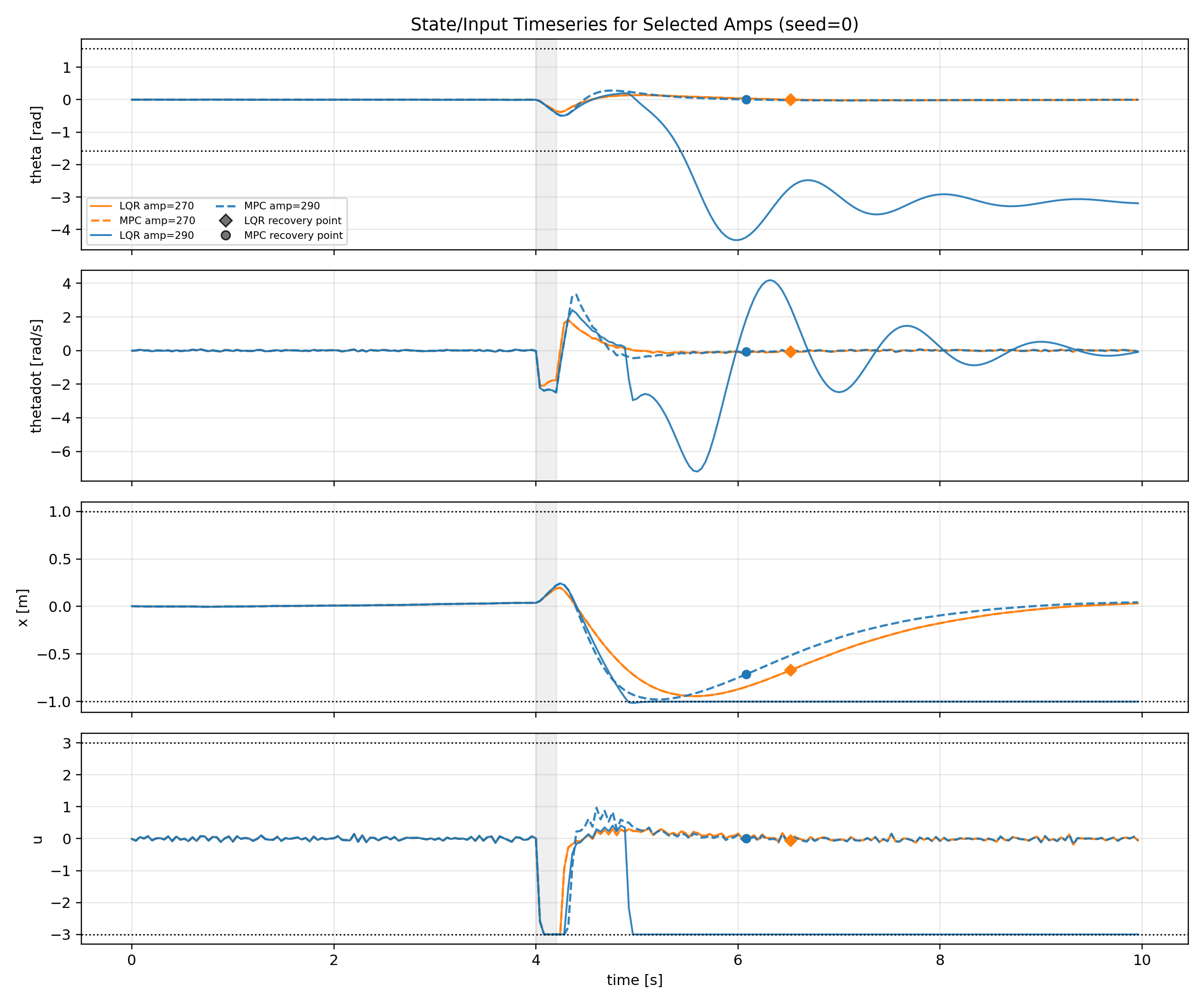
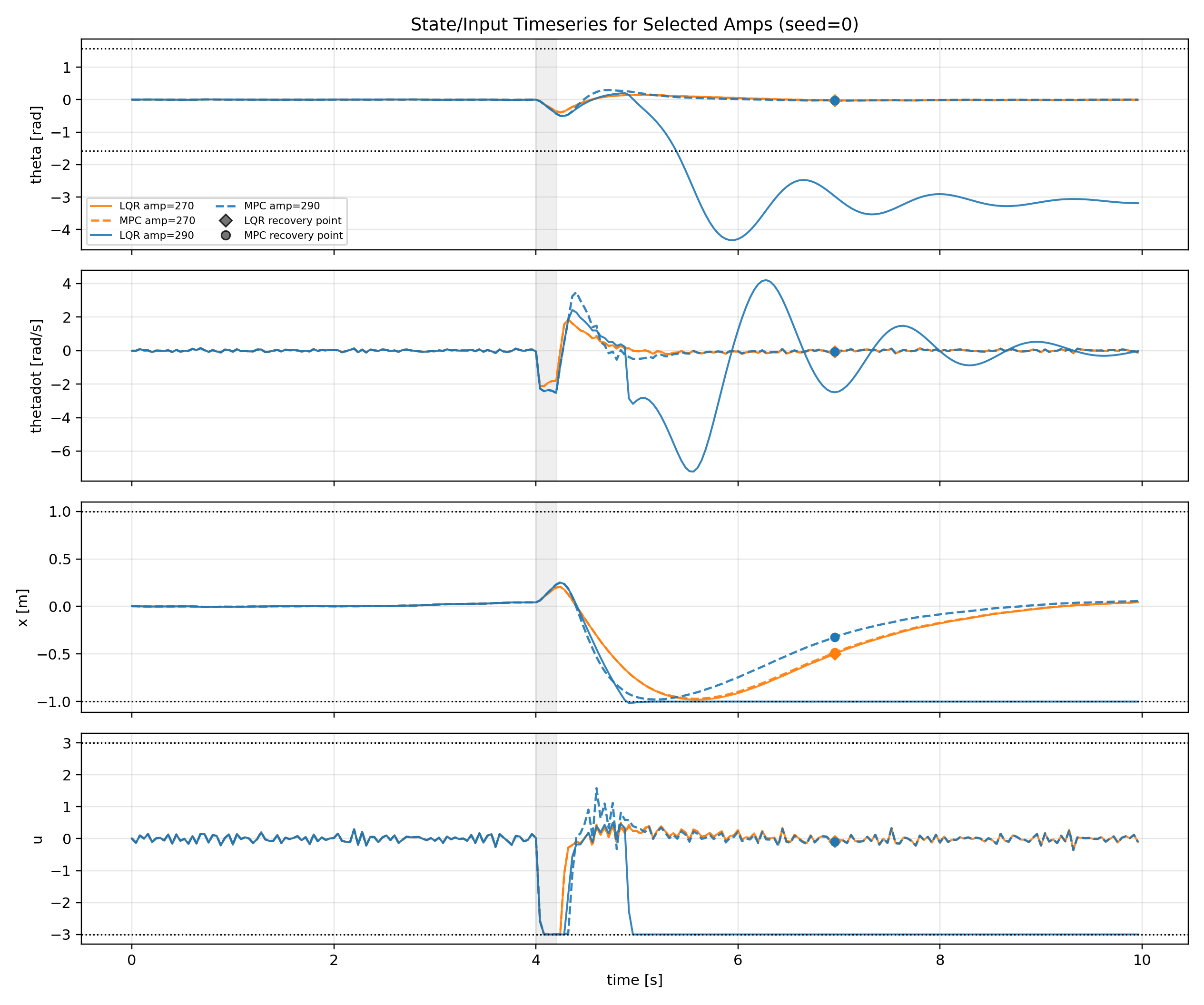
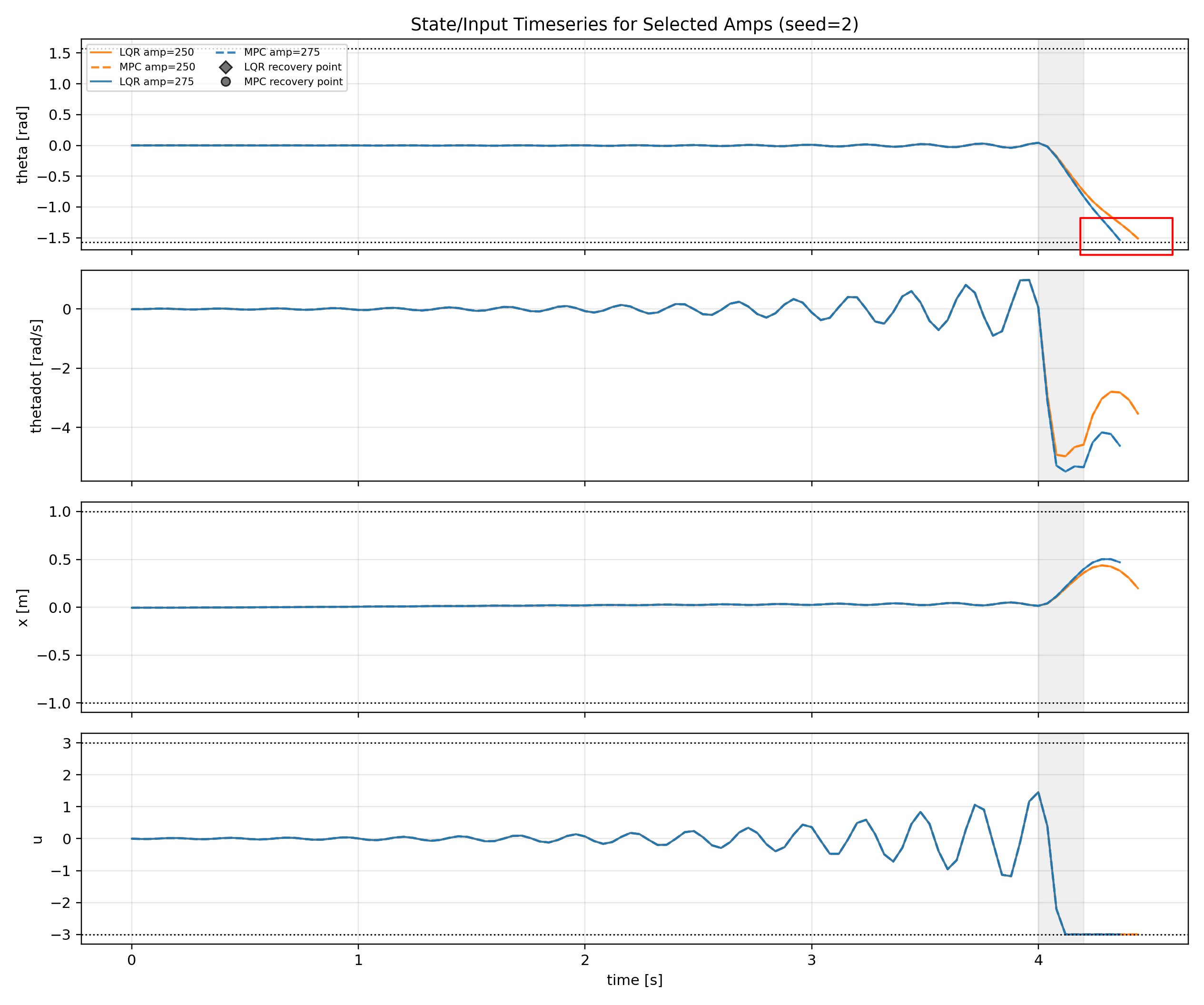
(5 - amp 270, 290 상태 시계열)
(MPC amp 250 제어 성공)
(MPC amp 290 제어 실패)
Outcome Rate 그래프(1)에서 amp 250~290 구간에서 LQR 제어는 amp 270까지 직립 유지에 성공하고 MPC 제어는 amp 290까지도 성공하는 것을 볼 수 있다.
amp 275부터 LQR의 실패 원인은 $x$ fail이다.
LQR은 제어에 현재 상태만 반영할 뿐, $x$ 나 $u$ 같은 제약을 사전에 고려하지 않는다.
따라서 $x$ 위치 고려 없이 카트가 움직이다가 레일 끝에 부딪혀 제어를 성공적으로 할 수 없었다.
반면에 MPC 제어는 $x$ 범위를 고려해서 예측 지평 내에서 $x$ 한계를 회피하도록 입력 $u$ 를 재분배했기 때문에 충돌하지 않았다.
Theta max post 그래프(2)는 전체 시뮬레이션 시간동안의 최대 값을 나타내며 LQR은 amp 275부터 실패하므로 값이 비어 보인다.
시계열 데이터를 확인한 결과 외력이 들어오는 step 동안에 관성에 의해 순간 기울어진 각도가 막대의 최대 각도였다.
내가 확인하고 싶은 것은 외란이 들어온 순간을 제외한 각도의 오버슈트였다. 따라서 아래 Theta_max_after_zero 그래프를 추가하였다.
아래 그래프는 외란 이후 막대가 카트 제어에 의해 0도를 한 번 지나친 시점 이후의 최대각이다.
외란의 강도가 강해질수록 각도가 증가했지만, 제어의 영향으로 완벽한 선형으로 증가하지는 않았다.
Recovery Time 그래프(3)에서는 MPC 제어일때, amp 275에서 가장 느린 회복 시간을 보여주는 것을 볼 수 있다.
이는 외력의 힘이 더 약한 경우와 강한 외력에 맞서 강한 제어가 들어올 경우에, 회복 시간이 더 짧아진다는 것을 보여준다.
회복 시간의 정의는 다음과 같다.
$\Delta t$ : 샘플링 시간(시뮬레이션 1 step 시간)
$k_{0}$ : 외란 시작 스텝
$D$ : 외란 길이 (step)
$k_{s} = k_{0} + D$ : 외란 종료 직후부터 평가 시작하는 기준 스텝
각 스텝에서 리커버리 밴드 진입 여부를
\[b_k = \mathbf{1} \left( \vert\theta_k\vert \le \varepsilon_{\theta} \land \vert\dot{\theta}_k\vert \le \varepsilon_{\omega} \right)\]위와 같이 정의해서 각도와 각속도가 모두 기준치 이하일 때만 1을 출력하게 하고
hold 시간 $T_{h}$ 를 시뮬레이션 step 시간인 $\Delta t$ 로 나눠서, 시간을 안정적으로 머물러야하는 step으로 바꾸면
$N_h = \max \left( 1, \mathrm{round} \left( \frac{T_h}{\Delta t} \right) \right)$
리커버리 완료 스텝은
\[k_{\mathrm{rec}} = \min \left\{ k \ge k_s \mid \prod_{j=0}^{N_h-1} b_{k+j} = 1 \right\}\]곱연산을 통해서 모든 스텝이 1일때만 전체가 1이 되는 특성을 사용했다.
$\prod_{j=0}^{N_h-1} b_{k+j} = 1$ 을 처음 만족하는 $k$를 회복 완료 스텝으로 판정하였다.
$\varepsilon_{\theta}$ : $3^\circ$
$\varepsilon_{\omega}$ : $0.1 \ rad/s$
$T_{h}$ : $0.5 \ s$
기준치는 위와 같이 설정했다.
요약하자면, (3도 이내 & 0.1의 각속도 이하)를 0.5초 유지하면 회복한 것으로 판정하였다.
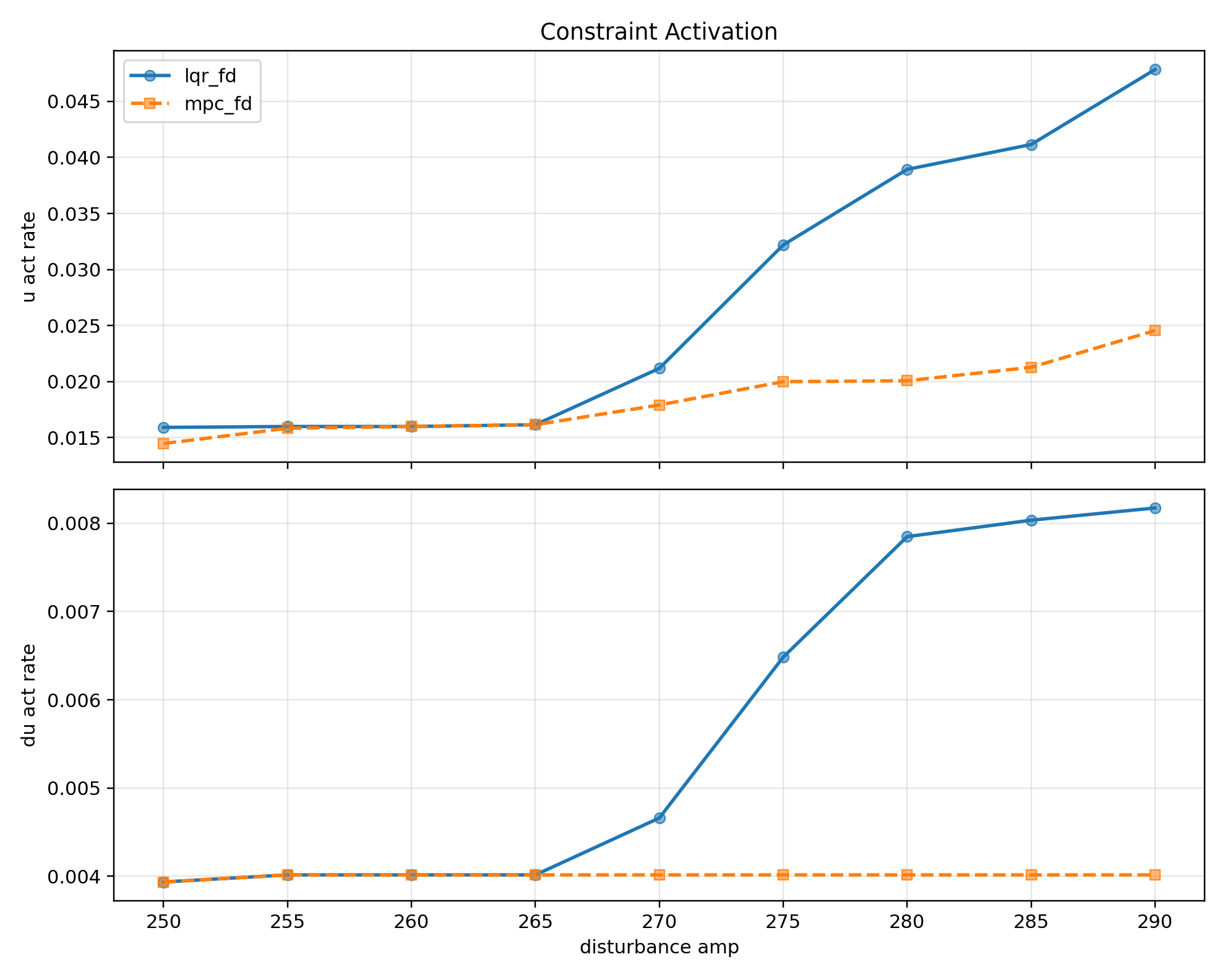
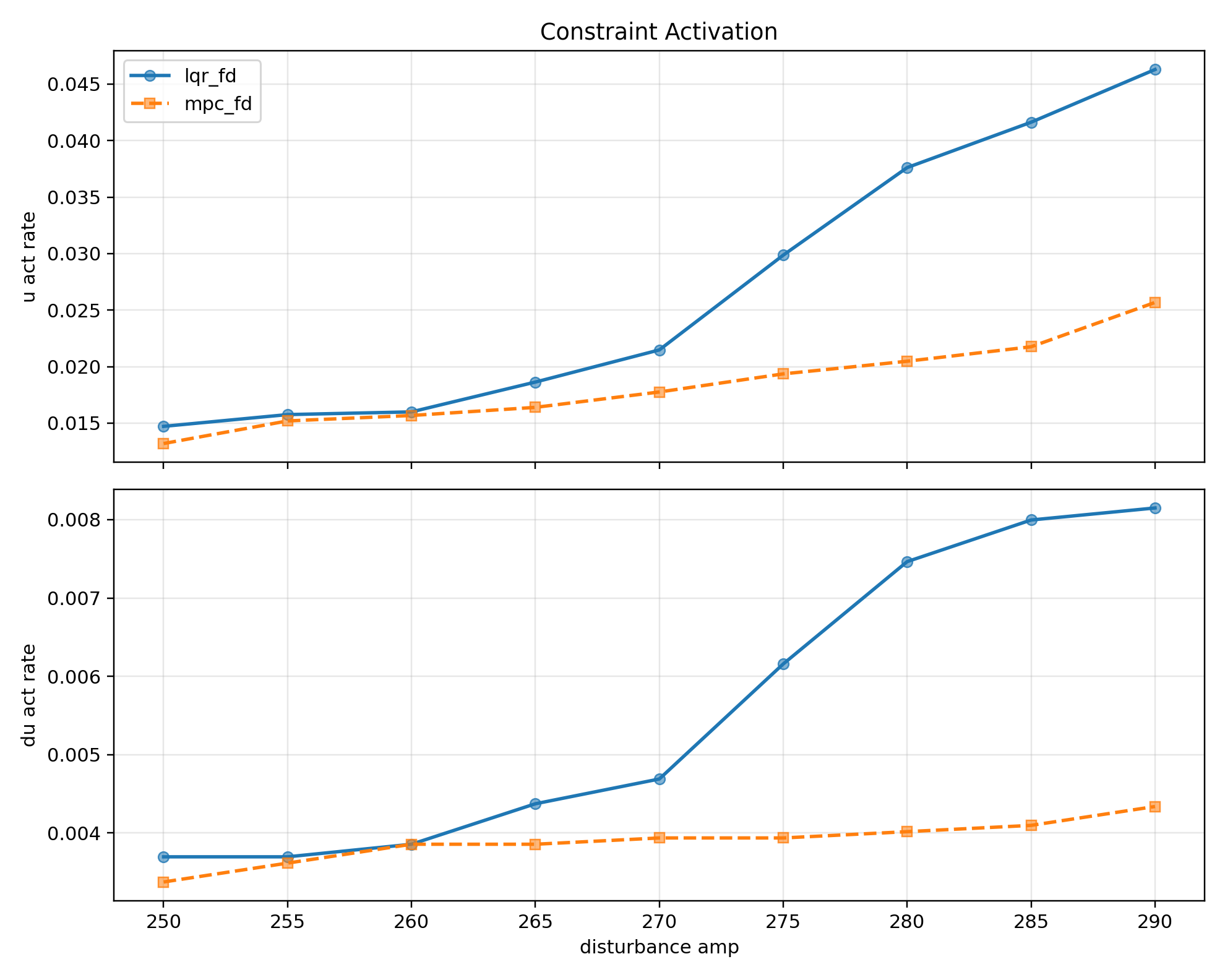
Theta 그래프와 Recovery 그래프를 보면 두 제어기 모두 성공하는 구간 amp 250~270에서 제약이 활성화 되는 빈도가 낮아, 값이 거의 동일한 것을 확인할 수 있다.
제약이 거의 활성화 되지 않는 구간에서는 LQR의 해가 사실상 최적해이기때문에 MPC 역시 LQR에 근접한다.
하지만 외란 이후부터 LQR 실패 시점 까지 분리된 제어 입력 에너지 그래프(4)를 보면, amp 270 까지는 LQR과 MPC가 거의 비슷하지만 LQR이 실패하는 275부터 MPC 에너지가 상대적으로 급상승 하는 것 처럼 보인다.
이 현상은 LQR이 실패 이후 step 구간에서는 제어가 멈추고, 실패 직전 step까지 MPC보다 약한 제어 입력을 내보내기 때문이다.
각 시점별로 확인하기 위해 두 번째 그래프에서 외란이 끝나는 시점인 105번째 step부터 LQR 실패 시점인 128 step 시점까지만 제어 입력을 분리해보았다.
음(-) 부호의 제어 입력은 카트를 왼쪽 벽으로 향하게 하는 힘이 된다.
MPC는 109 step 부근에 강하게 가속해서 막대의 균형을 먼저 잡고, 115 step 부근에서 양(+) 부호 제어 입력을 강하게 넣어 충돌 방지를 위한 감속을 시작한다.
하지만 LQR은 109 step 부근에서 균형을 약하게 잡고 양(+) 부호로 감속하는 제어 입력 역시 약하다.
MPC는 $x$ 위치에 대한 제약을 고려하기 때문에 균형을 빠르게 잡고 남은 시간을 레일을 벗어나지 않기 위해 감속하는 것에 사용하지만, LQR은 레일 제약을 알지 못하기 때문에 막대 상태에 따른 최적의 제어만 하다가 결국 레일 끝에 부딪혀 막대 균형 잡기를 실패하게 된다.
전체 시계열 그래프(5)를 보면 MPC는 각속도를 강한 제어로 양수로 바꾼 후 균형을 유지하지만, LQR은 상대적으로 약한 제어로 균형을 잡으려다가 시간이 부족하여 레일 끝에 도달하는 것으로 나타난다.
노이즈/지연 모델
이제 앞선 실험과 동일한 환경에서 노이즈와 지연만 추가해서 응답이 어떻게 바뀌는지 확인해볼 차례이다.
노이즈가 추가된 경우
센서 노이즈는 $\theta_{\mathrm{meas}} = \theta + \mathcal{N}(0,\sigma_\theta^2)$ 로 적용하였다.
$\sigma_\theta = {0.005, 0.01}$ 을 적용하여 2가지 경우에 대해 실험하였다.
노이즈는 제어의 전체적인 경향은 유지한채, 각 제어 입력에 $\pm$ 범위를 주게되어 전체적인 응답 위에 작은 진동이 추가될 것으로 예상했다.
 |
 |
 |
(6 - amp 250~290 성공률)
(7 - amp 270, 290 상태 시계열)
(8 - amp 250~290 포화 활성 비율 u, du)
노이즈가 생긴 상황에서는 노이즈가 없는 상황과 비교했을 때, LQR 제어기의 성공률이 amp 270에서 감소하고 275에서는 증가하였다.
한 두 step 차이로 $x$ fail로 실패하던 amp 275에서, 노이즈의 영향으로 제어 값이 범위를 갖게 되어 드물게 성공하는 경우가 생겼다는 것을 알 수 있다.
반대로 노이즈로인해 $x$ 가 감소한 경우에는 성공하던 amp 270에서도 드물게 실패하는 경우가 생겼다.
각속도와 제어 입력 그래프에서 특히 잔진동이 증가함을 확인했고, 이로인해 리커버리 타임이 증가한 것을 알 수 있다.
 |
 |
 |
(9 - amp 250~290 성공률)
(10 - amp 270, 290 상태 시계열)
(11 - amp 250~290 포화 활성 비율 u, du)
노이즈가 0.01로 증가하면서 0.005에서 보인 경향성이 더 짙어졌다.
90% 이상 성공률을 가지는 amp를 의미하는 $A_{90}$ 값은 LQR의 경우 0.005 노이즈에서 $A_{90} = 265$ 에서 0.01 노이즈일때 $A_{90} = 260$ 으로 감소했고, $A_{10}$ 의 경우 노이즈가 증가함에 따라 $A_{10} = 275$ 에서 $A_{10} = 280$ 으로 증가하였다.
노이즈로 인한 제어 무작위성으로 인해 각 amp에서 더 견디거나 덜 견딜수 있게 되어 초기 조건에 따라 성공률이 낮아지거나 높아지는 것으로 확인된다.
Constraint Activation 그래프를 보면 외력이 강해서 포화가 길었던 amp에서는 노이즈가 포화를 줄이는 방향으로 작용하고, 외력이 약해서 포화가 짧았던 amp에서는 노이즈가 포화를 증가시키는 방향으로 작용했다.
이는 포화선 부근 전후에 위치하는 제어 입력들이 노이즈에 의해 포화선 밖으로 나가고 들어오는 비율의 차이 때문에 발생한다.
각속도와 제어 입력은 일관된 경향으로 더 불안정해졌고, 리커버리 타임은 더 증가하였다.
지연이 추가된 경우
지연은 $u_{\mathrm{applied}}(k) = u_{\mathrm{cmd}}(k-d)$, $d = {1, 2}$ step으로 2가지 지연 상황을 실험하였다.
지연은 노이즈와 달리 작은 진동이 추가되는 것이 아니라 전체적인 응답 자체의 불안정성을 높여서 수렴을 어렵게 하고, 그 결과 응답 형태가 진동/발산하는 형태일 것으로 예상했다.
기존 amp 250~290 범위 실험에서는 지연이 1 step일때, MPC가 제약을 만족하면서 제어 입력 u를 찾을 수 없었다(solver_fail/infeasible).
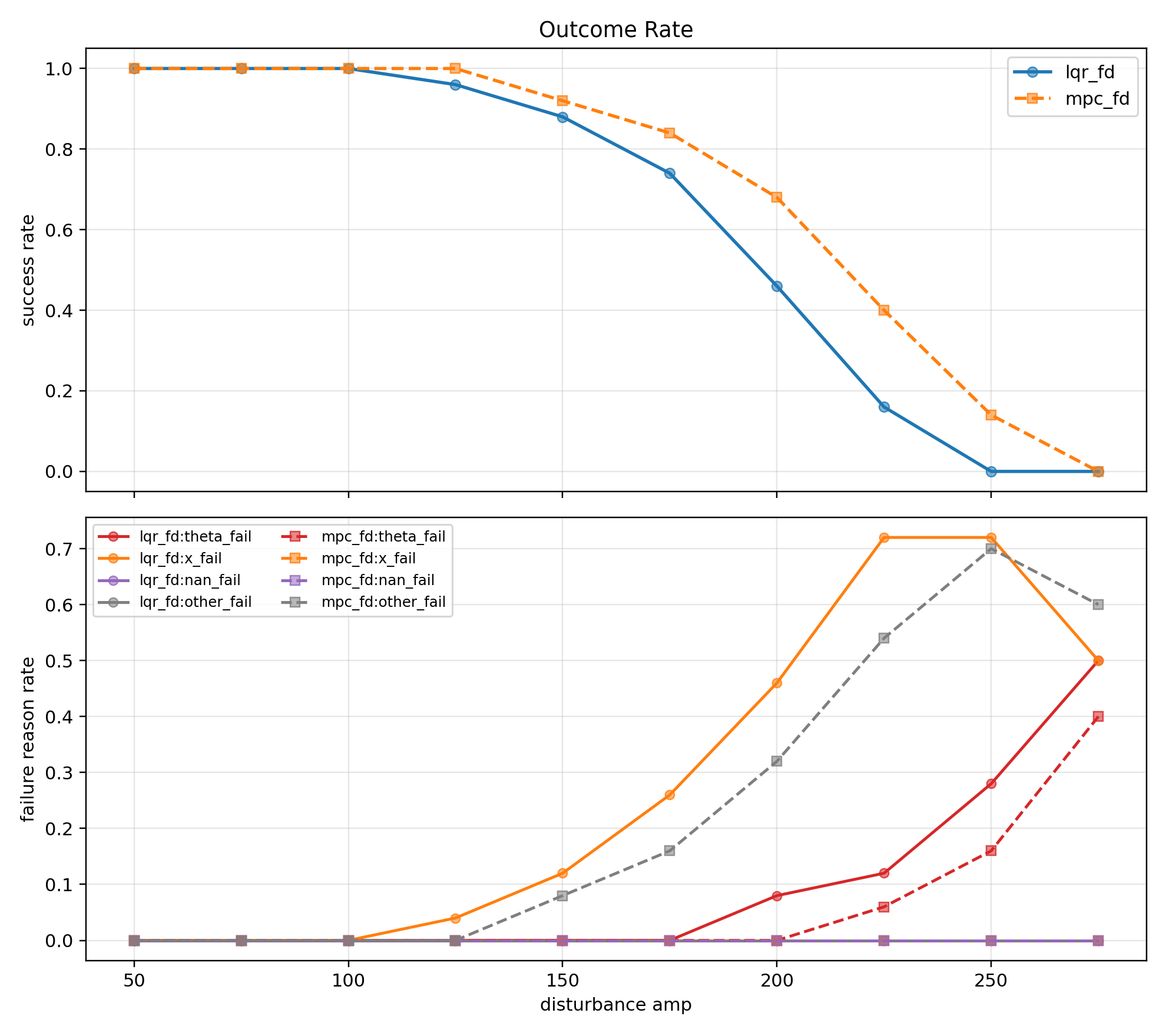
따라서 지연에 의해 제어 가능한 외력 amp 구간이 얼마나 감소하는지 확인하기 위해 amp 50부터 275까지 25 단위로 성공률을 확인했다.
 |
 |
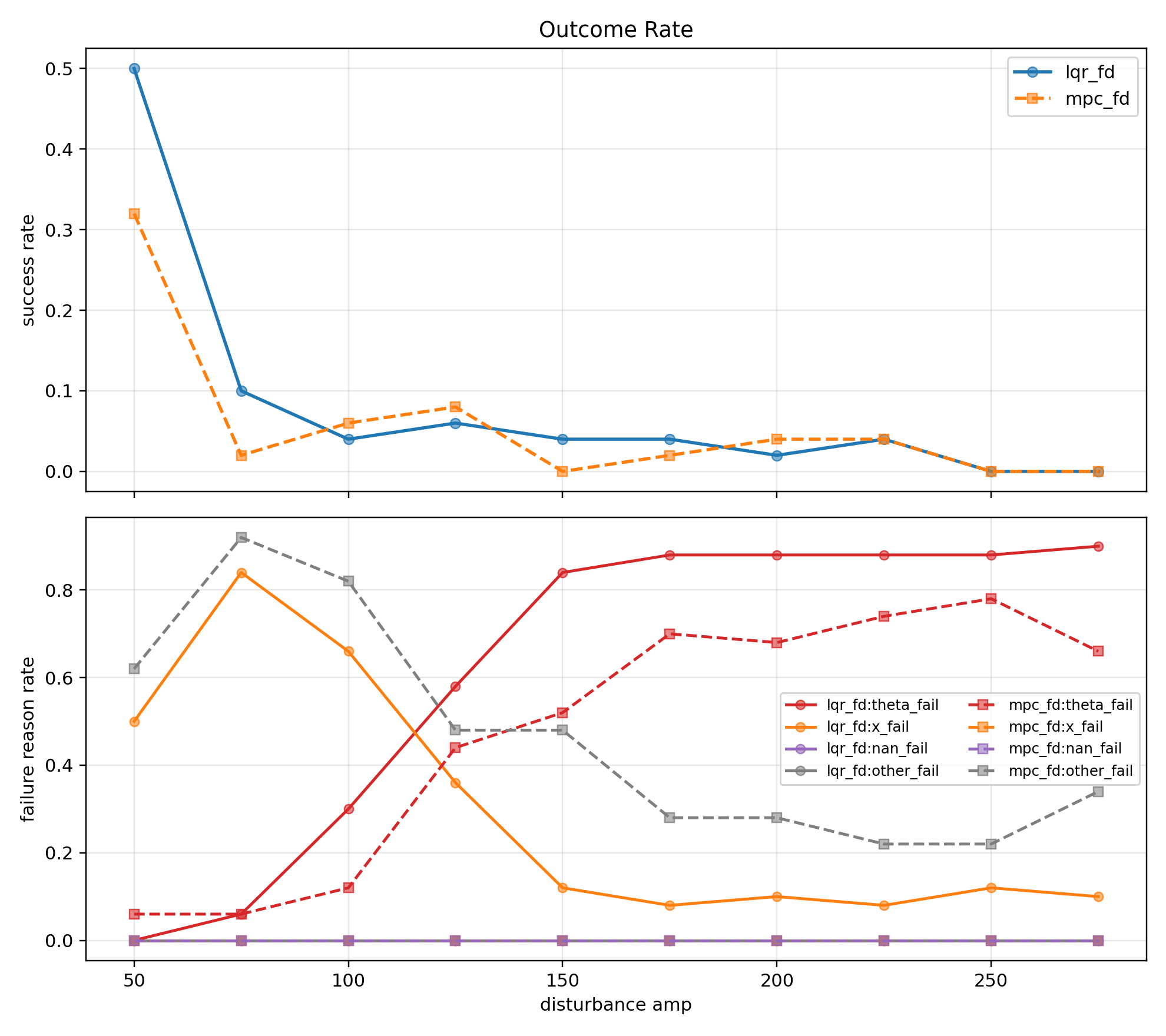
(12 - amp 50~275 성공률)
(13 - amp 250, 275 상태 시계열)
amp 50부터 100 구간에서는 LQR과 MPC 모두 제어에는 성공했지만 이후 구간에서 두 모델 모두 꾸준히 성공률이 감소했다.
LQR은 $x$ fail, MPC는 $\theta$ fail, solver fail이 각각 발생했다.
LQR은 앞선 경우(노이즈/포화)와 마찬가지로 $x$ 제약을 반영하지 못해 제어에 실패했고, MPC는 제어 입력 지연에 hard한 제약까지 맞물려 입력 해를 찾지 못하거나(solver fail) 제어가 불안정해져 각도 제어에 실패(theta fail)하였다.
노이즈/지연이 없을 때 $A_{90} = 265$ 값을 가지던 LQR이 지연이 추가되자 amp 100에서부터 성공률이 감소하기 시작해서 $A_{90} = 125$ 를 가지게 되었다.
지연에 의해 버틸 수 있는 외력이 일찍 감소하기 시작하였고, 최대 외력 한도 $A_{max}$ 이 $A_{max} = 270$ 에서 $A_{max} = 250$ 으로 7.4% 감소하였다.
MPC도 마찬가지로 $A_{max} = 275$ 까지 감소하였다.
 |
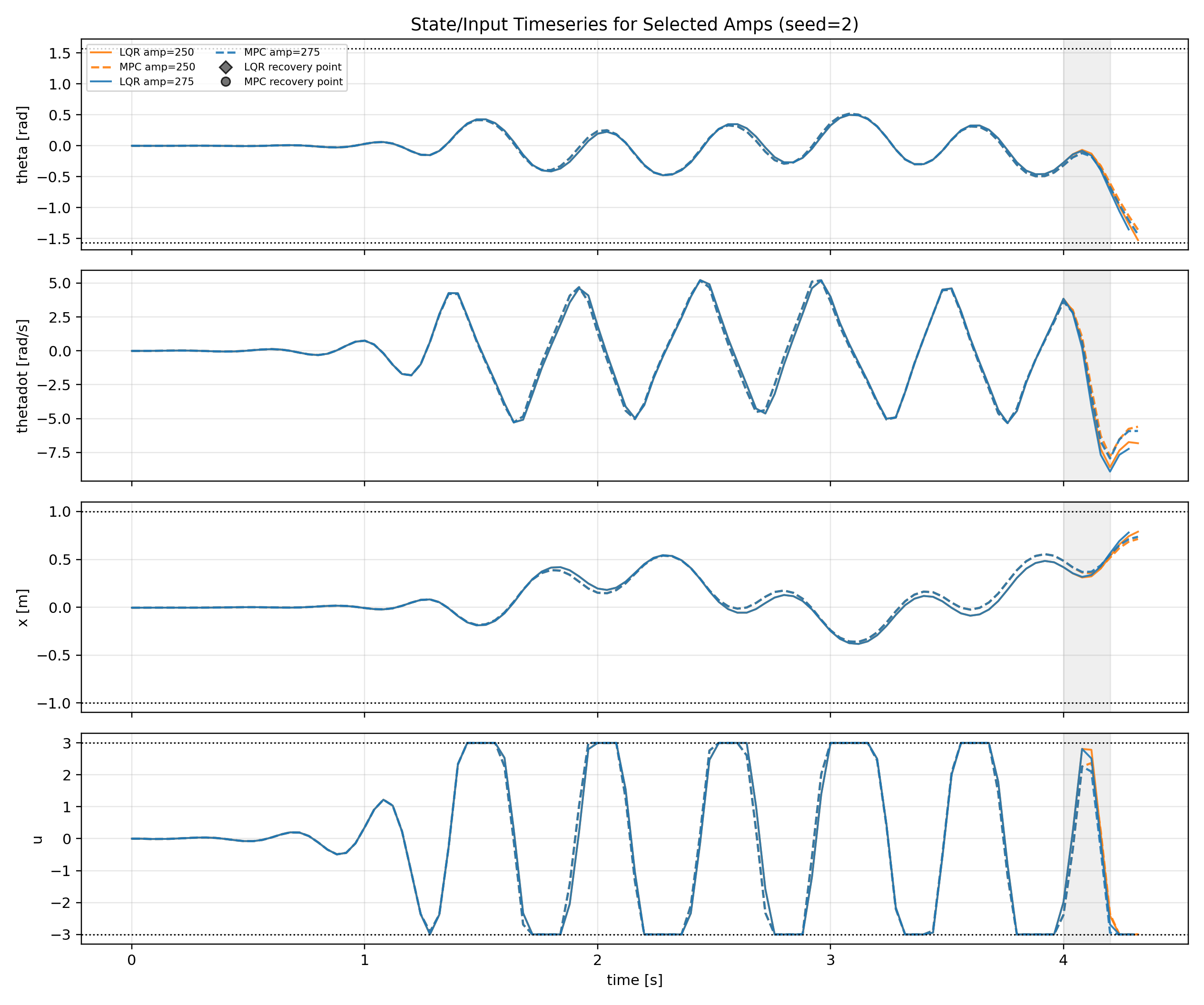 |
(14 - amp 50~275 성공률)
(15 - amp 250, 275 상태 시계열)
지연이 2 step이 된 경우, LQR과 MPC 모두 최대 외력 한도는 다른 amp 구간에 비해 크게 감소하지 않은 $A_{max} = 250$ 값을 가졌지만 낮은 amp 범위에서 전체적인 성공률이 급격하게 감소했다.
또한 제어 진동이 계속 유지되어 리커버리 타임을 구할 수 없었다.
LQR은 각도 제어 실패(theta fail)와 $x$ 제약 실패(x fail)를 모두 가지고 있었지만, MPC는 각도 제어에 실패(theta fail)하거나 $x$ 제약을 지키기위한 제어 해를 찾는 것에 실패(solver fail)한다는 차이가 있었다.
지연 실험으로부터 입력이 늦어짐에따라 위상 여유가 감소함에따라 진동/발산 방향으로 제어가 변하면서 불안정해진다는 것을 확인할 수 있다.
지연은 성공률 분산을 키우는 노이즈와 달리 임계 외력 구간을 일관되게 왼쪽으로 이동시킨다는 것을 확인하였다.
결론 및 토의
앞선 결과를 조건별로 종합하면, 포화/노이즈/지연은 성능을 떨어뜨리는 방식이 서로 다르게 나타났다. 포화는 입력과 상태의 허용 범위를 직접 제한하여, 제어기가 사용할 수 있는 여유를 물리적으로 깎아먹는다. 특히 $x$ 레일 제약이 있는 환경에서는, 제약을 사전에 고려하지 않는 LQR이 $x$ fail로 먼저 무너지는 반면, MPC는 예측 지평 내에서 $x$ 한계를 회피하도록 입력 $u$를 재분배하여 같은 외란에서도 성공 구간을 확장했다.
노이즈는 지연과 달리 임계 구간 자체를 일관되게 이동시키기보다는, 성공률의 분산을 키우는 형태로 나타났다. $\theta$ 측정 노이즈가 증가하면 특정 amp에서 “한 두 step 차이로” 성공/실패가 갈리며, $A_{90}$은 감소(안정적으로 버틸 수 있는 구간 축소)하고 $A_{10}$은 증가(경계 amp에서 운 좋게/나쁘게 버티는 경우 증가)하는 경향이 확인되었다. 즉 노이즈는 평균 성능을 낮추는 효과도 있지만, 더 직접적으로는 변동성을 키워 성공률 곡선의 경계를 모호하게 만든다.
반면 지연은 성공률 분산을 키우기보다는 임계 구간 자체를 왼쪽으로 이동시키는 효과가 지배적이었다. 지연이 추가되자 LQR은 $A_{90}$이 $265 \rightarrow 125$로 크게 감소했고, $A_{max}$ 역시 $270 \rightarrow 250$으로 감소했다. 이는 입력이 늦어지면서 위상 여유가 줄어들고, 동일 외란에서도 제어가 진동/발산 방향으로 변해 안정성 여유가 줄어들기 때문이다. 이때 실패 모드 역시 LQR과 MPC에서 갈린다. LQR은 주로 $x$ fail이 중심이었고, MPC는 1. 지연 + hard 제약으로 인해 feasibility가 먼저 붕괴하는 solver_fail/infeasible, 2. feasibility가 유지되더라도 지연으로 인해 $\theta$ fail로 이어지는 두 경향이 나타났다.
이 차이는 로봇 제어에서 현실에 적용할 때 중요하다고 생각한다. 현실 시스템은 센서 노이즈와 입력 지연이 항상 존재하므로, MPC를 “hard 제약 + fallback 없음”으로 구성하면 성능 열화 이전에 최적화가 먼저 죽는 문제가 생길 수 있다. 따라서 실제 적용에서는 soft constraint, solver 실패 시 대체 제어기, 지연을 미리 고려한 모델링, 그리고 노이즈를 완화하는 상태 추정기가 함께 필요할 것 같다.
한계로는 노이즈를 $\theta$에만, 지연을 입력에만 적용했으며, fallback이 없는 MPC 설정이라 feasibility 문제가 과장될 수 있다. 다음 단계로 soft constraint 및 지연을 고려한 모델 MPC로 설정을 확장하고, 동일 프로토콜에서 임계 amp($A_{90}, A_{10}, A_{max}$)와 실패 모드 분포가 어떻게 바뀌는지 개선 효과를 검증하면 좋을 것 같다.
부록/실험 정의
사용한 환경/모델/비용함수/제약/외란/평가/프로토콜을 한 곳에 고정해 재현 가능하도록 정리했다.
M0. 표기/단위
- 상태: $\mathbf{x}_k = [x,\theta,\dot{x},\dot{\theta}]^\top$ (단위: $x\,[m]$, $\theta\,[rad]$, $\dot{x}\,[m/s]$, $\dot{\theta}\,[rad/s]$)
- 입력: $u_k$ (환경 action), $F_k = \mathrm{gear}\,u_k$ (단위: $u\,[\mathrm{unitless}]$, $F\,[N]$)
- 샘플링: $\Delta t =$
0.04s, $k$는 이산 시간 인덱스
M1. 시뮬레이션/환경
| 항목 | 값 |
|---|---|
| 시뮬레이터 | MuJoCo 3.4.0 |
| Env | Gymnasium InvertedPendulum-v5 (xml_file=envs/assets/inverted_pendulum_unlimited_hinge.xml) |
| integrator / substeps | RK4 / frame_skip=2 (model timestep 0.02 s) |
| timestep | $\Delta t =$ 0.04 s |
| 마찰/댐핑 | cart geom friction=(1.0, 0.1, 0.1), hinge damping=1.0 |
| gear | $\mathrm{gear} =$ 100 |
| 레일/조인트 리밋 | $x \in [x_{\min}, x_{\max}]$, $x_{\min}=$ -1(기본) , $x_{\max}=$ 1(기본) |
M2. 모델 및 선형화/이산화
- 선형화 기준점: 직립 근처 $\theta^* = 0$, $\dot{x}^* = 0$, $\dot{\theta}^* = 0$, $x^* =$
0, $u^* =$0 - 이산 선형 모델: $\mathbf{x}_{k+1} = A_d \mathbf{x}_k + B_d u_k$
- $A_d, B_d$ 수치는 위 발췌 내용($A_d^{th}/A_d^{fd}$, $B_d^{th}/B_d^{fd}$) 중 아래에서 선택한 것을 사용한다.
| 항목 | 값 |
|---|---|
| 사용 모델 | fd |
| $A_d$ | A_d^{fd} |
| $B_d$ | B_d^{fd} |
M3. 외란 주입
- 외란 시작/길이: $k_0 =$
100(기본), $D =$5(실험값)step, $k_s = k_0 + D$ - amp 정의:
| 항목 | 값 |
|---|---|
| 적용 물리량 | 카트 수평 외력 F_ext (action bias 아님) |
| 적용 위치 | slider joint DOF (qfrc_applied) |
| 파형 | window ($k_0 \le k < k_0 + D$) |
| 크기 | amp [N], $F_{\mathrm{ext}}(k)=s\cdot\mathrm{amp}$ (seed별 $s\in{-1,+1}$, 기본 balanced) |
M4. 제어기 설계
M4.1 LQR
- 시스템: $\mathbf{x}_{k+1} = A_d \mathbf{x}_k + B_d u_k$
- 비용함수(무한지평 LQR):
- $Q, R$
| 항목 | 값 |
|---|---|
| $Q$ | \(\mathrm{diag}([\,1 , 80 , 1 , 10\,])\) |
| $R$ | 0.1 |
| 선정 근거 | 각도에 중점을 둔 큰 가중치와 과도한 입력 방지를 위한 작은 입력 가중치 |
| 사용 게인 | K^{fd} |
- 구현상의 제약 처리
| 항목 | 값 |
|---|---|
| raw 입력 | $u_{\mathrm{raw}} = -K\mathbf{x}_k$ |
| 입력 포화 | $u = \mathrm{clip}(u_{\mathrm{raw}}, u_{\min}, u_{\max})$ |
| 레이트 제한 | $\vert u_k-u_{k-1}\vert \le \Delta u_{\max}$ |
| 적용 순서 | clip/rate 제약 교집합으로 동시 투영 |
M4.2 MPC
- 예측모델: $\mathbf{x}_{i+1} = A_d \mathbf{x}_i + B_d u_i$
- 예측 지평: $N =$
20(외란이 5 step이므로 20 step은 외란 이후 회복 구간 포함) - 비용(예시: terminal 포함):
- 제약: M5의 제약을 예측 상태와 입력에 적용한다. (현재 상태가 아닌 미래 구간) \(\mathbf{x}_1,\ldots,\mathbf{x}_N \quad(\text{i.e., }\mathbf{x}_{k+1},\ldots,\mathbf{x}_{k+N}), \qquad u_0,\ldots,u_{N-1}\)
| 항목 | 값 |
|---|---|
| terminal cost $P$ | DARE의 P (solve_discrete_are) |
| terminal constraint | 미사용 |
| QP solver | auto (osqp 우선, 없으면 scipy) |
| tol / max_iter | eps_abs=1e-5, eps_rel=1e-5, max_iter=4000 |
| warm start | on |
| infeasible 처리 | 별도 slack/fallback 없음 (해 실패 시 RuntimeError) |
M5. 제약
- 입력 제약: $u_{\min} \le u_k \le u_{\max}$, $u_{\min} = -3$, $u_{\max} = 3$
- 상태 제약(레일): $x_{\min} \le x_k \le x_{\max}$, $x_{\min} = -1$, $x_{\max} = 1$
- 입력 변화량: $\vert u_k-u_{k-1}\vert \le \Delta u_{\max}$, $\Delta u_{\max} = 2.6$
- 센서 노이즈: $\theta_{\mathrm{meas}} = \theta + \mathcal{N}(0,\sigma_\theta^2)$, $\sigma_\theta =$
0.005, 0.01- 입력 지연: $u_{\mathrm{applied}}(k) = u_{\mathrm{cmd}}(k-d)$, $d =$
1, 2step
(제어기는 지연을 고려하지 않고 $u_{\mathrm{cmd}}(k)$를 계산하며, 실제 적용은 $d$ step 지연된 값이 사용됨)
M6. 평가 지표
-
성공/실패:
전 시간 구간 기준. terminated_any=0이면 성공, |θ|>1.5708 또는 |x|≥1.0 또는 NaN이면 실패 - $\theta$ 오버슈트:
- $\theta_{\max,\mathrm{all}} = \max_k \vert\theta_k\vert$
- $\theta_{\max,\mathrm{post}} = k_s$ 이후 첫 0-crossing 뒤 구간에서 $\max \vert\theta_k\vert$ (success only)
- 리커버리 시간:
\(b_k = \mathbf{1} \left( \vert\theta_k\vert \le \varepsilon_{\theta} \land \vert\dot{\theta}_k\vert \le \varepsilon_{\omega} \right)\)- $\varepsilon_{\theta} = 3^\circ$, $\varepsilon_{\omega} = 0.1\ \mathrm{rad/s}$, $T_h = 0.5\ \mathrm{s}$
- $N_h = \max \left( 1, \mathrm{round} \left( \frac{T_h}{\Delta t} \right) \right)$
- $k_{\mathrm{rec}} = \min{\,k \ge k_s \mid \prod_{j=0}^{N_h-1} b_{k+j} = 1\,}$
- 리커버리 시간: $t_{\mathrm{rec}} = (k_{\mathrm{rec}}-k_s)\Delta t$
- 입력 사용량
- $E_u = \sum_{k=0}^{T-1} u_{\text{applied},k}^2$
- summary CSV의
u_energy는 에피소드 전체 구간의 applied input 제곱합 u_energy.png의 1행은 별도 보조지표로, 외란 이후 20 step 구간($k_{\text{start}}\ldots k_{\text{start}}+k_{\text{len}}-1$)에서의 $\sum u_k^2$를 사용
M6.1 그래프 산출 규칙
- 성공률 그래프(
success_rate*.png)- 집계 단위:
(controller, amp)별 seed 평균 - 계산식: $\mathrm{SuccessRate}(c,a)=\frac{1}{N_{\text{seed}}}\sum_{s=1}^{N_{\text{seed}}}\mathbf{1}[\mathrm{success}_{c,a,s}=1]$
success=1조건: summary CSV의terminated_any=0(실패 조건은 M6의 성공/실패 정의와 동일)
- 집계 단위:
- 시계열 그래프(
u_timeseries*.png)- 데이터 소스: step CSV
- 채널: $\theta$, $\dot{\theta}$, $x$, $u_{\mathrm{applied}}$ (없으면 $u_{\mathrm{raw}}$ 대체)
- 선택 규칙: 지정한
seed와 amp(단일 amp 또는 amp index 목록)만 시각화 - 보조 표기: 외란 구간 $[t_0,\ t_0+\mathrm{duration})$ 음영, 리커버리 마커(설정된 $\varepsilon_\theta,\varepsilon_\omega,T_h$ 기준)
u/du포화(활성) 비율 그래프(sat_rate*.png)- 계산 구간: 에피소드 유효 구간 $k=0\ldots T-1$ (실패 시 실패 시점까지)
u활성 마스크: \(\mathbf{1}\!\left[|u_k|\ge u_{\max}-s_u\right], \quad s_u\equiv \texttt{sat_tol}\)du활성 마스크: \(\mathbf{1}\!\left[|\Delta u_k|\ge \Delta u_{\max}-s_{\Delta u}\right],\quad \Delta u_k=u_k-u_{k-1},\quad s_{\Delta u}\equiv \texttt{du_tol}\)- 비율: \(r_u=\frac{1}{T}\sum_{k=0}^{T-1}\mathbf{1}\!\left[|u_k|\ge u_{\max}-s_u\right]\) \(r_{\Delta u}=\frac{1}{T-1}\sum_{k=1}^{T-1}\mathbf{1}\!\left[|\Delta u_k|\ge \Delta u_{\max}-s_{\Delta u}\right]\)
- $A_{90}$ 정의:
- $A_{90} = \max{\text{amp} \mid \text{success_rate}(\text{amp}) \ge 0.9}$
- $A_{10}$ 정의:
- $A_{10} = \max{\text{amp} \mid \text{success_rate}(\text{amp}) \ge 0.1}$
- $A_{\max}$ 정의:
- $A_{\max} = \max{\text{amp} \mid \text{success_rate}(\text{amp}) \ge 0}$
M7. 실험 프로토콜
| 항목 | 값 |
|---|---|
| 초기조건 분포 | x0, xdot0, thetadot0 ~ Uniform[-0.01, 0.01], theta0=0 (override) |
| 에피소드 길이 | 250 step |
| seed 수 | 50 (0~49) |
| seed 특성 | LQR/MPC 비교는 동일 seed에서 동일 노이즈/외란 시퀀스를 사용 |
| amp sweep (Level1/Noise) | 250,255,260,265,270,275,280,285,290 (간격 5) |
| amp sweep (Delay) | 50,75,100,125,150,175,200,225,250,255,260,265,270,275,280,285,290 (간격 25) |
| 조기 종료 | 종료 조건: $\vert\theta\vert > 1.5708$ 또는 $\vert x\vert \geq 1.0$ 또는 NaN |
| 로그 | step CSV(k,t_sec,x,theta,xdot,thetadot,u_raw,u_applied,du_applied,disturb_force,reward,terminated,truncated) + summary CSV(성공/실패, term_reason, sat/du 활성화, recovery, u_energy 등) |
M8. 터미널 실행 예시
인자들에 대한 자세한 설명은 GitHub EXPERIMENT_COMMANDS.md 파일 참조
python -m experiments.fd_compare.eval_sweep_fd_compare \
--mode metrics \
--controllers lqr_fd,mpc_fd \
--amps 50,75,100,125,150,175,200,225,250,275 \
--seeds 50 \
--disturbance-kind window \
--t0 100 \
--duration 5 \
--theta0 0 \
--termination-theta 1.5708 \
--termination-x-limit 1.0 \
--x-fail-limit 1.0 \
--x-fail-eps 0.0 \
--x-fail-hold 1 \
--actuator-u-max 3.0 \
--actuator-u-min -3.0 \
--actuator-du-max 2.6 \
--du-tol 0.01 \
--mpc-state-constraint x \
--mpc-x-margin 0.02 \
--metric-du-threshold 2.6 \
--sat-tol 0.02 \
--steps 250 \
--actuation-delay-steps 1 \
--step-log-dir logs/fd_compare/steps_metrics \
--out logs/fd_compare/summary_force.csv
python -m experiments.fd_compare.plot_fd_compare \
--csv logs/fd_compare/summary_force.csv \
--outdir plots/fd_compare \
--step-log-dir logs/fd_compare/steps_metrics \
--u-seed 2 \
--u-amp-idx 5,10 \
--u-energy-amp 250 \
--u-energy-seed 2